
본 시리즈에서는 데이터베이스의 개념을 정리하고 필요시 실습을 진행합니다.
- 실습 환경(Server)
- 원격 서버 (OS) : AWS-EC2 (
Ubuntu-24.04) - DBMS(관리 시스템) : MariaDB (
10.11.8-MariaDB)
- 원격 서버 (OS) : AWS-EC2 (
- 실습 환경(Client)
- Client OS : Windows 11
- DB Tool (IDE) : JetBrains DataGrip (
2024.2.2) - Java (JDBC) : JDK 21 (
correto-21) - Java IDE : IntelliJ IDEA (
Ultimate Edition)
- DB 실습 예제
- MySQL
world database - https://dev.mysql.com/doc/index-other.html
- MySQL
DataBase - SQL DML & JOIN
1. CRUD란?
CRUD는 데이터의 생성(Create), 조회(Read), 수정(Update), 삭제(Delete)를 의미하며, 대부분의 애플리케이션이 데이터를 관리하는 기본적인 네 가지 작업입니다.
- 데이터베이스와 같은 저장 시스템에서 CRUD는 핵심 개념으로, 각 작업이 SQL에서 특정 명령어로 표현됩니다.

1.1 SQL의 CRUD
SQL의 CRUD는 다음과 같이 데이터베이스에서 데이터를 관리하는 네 가지 주요 작업을 포함합니다.
- Create (생성): 데이터베이스에 새로운 레코드를 삽입하여 데이터를 추가하는 작업입니다.
- SQL 명령어:
INSERT - 예: 새로운 사용자를
users테이블에 추가
- SQL 명령어:
INSERT INTO users (user_id, name, email) VALUES (1, 'Alice', 'alice@example.com');- Read (조회): 데이터베이스에서 데이터를 검색하고 조회하는 작업입니다. 필요한 데이터를 특정 조건에 맞게 불러옵니다.
- SQL 명령어:
SELECT - 예:
users테이블에서 모든 사용자 정보 조회
- SQL 명령어:
SELECT * FROM users;
- Update (수정): 기존 데이터의 값을 변경하는 작업입니다. 특정 조건을 만족하는 레코드의 값을 업데이트합니다.
- SQL 명령어:
UPDATE - 예: 특정 사용자의 이메일 주소를 변경
- SQL 명령어:
UPDATE users SET email = 'new_email@example.com' WHERE user_id = 1;- Delete (삭제): 데이터베이스에서 데이터를 삭제하는 작업입니다. 특정 조건에 맞는 레코드를 삭제합니다.
- SQL 명령어:
DELETE - 예: 특정 사용자를
users테이블에서 삭제
- SQL 명령어:
DELETE FROM users WHERE user_id = 1;이와 같이, SQL에서의 CRUD는 데이터베이스를 조작하고 관리하기 위한 기본적인 명령어들로 구성됩니다.
1.2 SQL & HTTP의 CRUD
웹 애플리케이션에서 CRUD 작업은 일반적으로 HTTP 메서드와 매칭되어 사용됩니다.
SQL의 CRUD 작업과 HTTP 메서드 간의 대응 관계는 다음과 같습니다.
| 작업 | SQL 명령어 | HTTP 메서드 | 설명 |
|---|---|---|---|
| Create | INSERT | POST | 새로운 리소스를 생성 |
| Read | SELECT | GET | 기존 데이터를 조회 |
| Update | UPDATE | PUT / PATCH | 기존 데이터를 수정 |
| Delete | DELETE | DELETE | 기존 데이터를 삭제 |
이와 같이, SQL의 CRUD 작업과 HTTP 메서드는 데이터의 생성, 조회, 수정, 삭제라는 기본적인 목적을 공유하며, 웹 애플리케이션에서 데이터베이스와의 상호작용을 이해하는 데 중요한 개념입니다.
참고: CRUD와 HTTP 메서드의 관계에 대한 자세한 내용은 네트워크 파트에서 다룰 예정입니다.
2. SQL Alias(AS) & WildCard(*)
Alias(AS)와 WildCard(*)는 SQL 쿼리에서 자주 사용되는 기능으로, 데이터를 더 쉽게 조회하고 조작할 수 있도록 도와줍니다.
2.1 Alias (별칭)
Alias(AS)는 열(Column)이나 테이블에 별칭(별명)을 부여하는 기능으로, 쿼리 결과를 더 읽기 쉽게 하거나, 복잡한 쿼리에서 특정 열이나 테이블을 간단하게 표현할 때 유용합니다.
AS키워드를 사용하여 별칭을 설정하며, 별칭은 주로 보고서나 데이터 시각화 시 가독성을 높이는 데 사용됩니다.- 테이블 Alias: 복잡한 쿼리에서 테이블 이름을 간략하게 줄일 때 유용합니다.
- 열 Alias: 계산된 열이나 긴 열 이름에 별칭을 부여하여 가독성을 높입니다.
-- 열에 별칭 사용
SELECT name AS 'Name', salary AS 'Annual Salary' FROM employees;
-- 테이블에 별칭 사용
SELECT e.name, d.department_name
FROM employees AS e
JOIN departments AS d ON e.department_id = d.department_id;참고:
AS키워드는 생략 가능하지만, 가독성을 위해 사용하는 것이 좋습니다.
2.2 WildCard (*)
Wildcard(*)는 모든 열을 선택할 때 사용되는 기호로, *를 사용하여 테이블의 모든 열을 한번에 조회할 수 있습니다.
- 이는 단순한 조회 쿼리에서 편리하지만, 일부 열만 필요한 경우에는 명시적으로 열 이름을 지정하는 것이 좋습니다.
- 모든 열을 조회하는 것은 데이터 전송량이 증가할 수 있기 때문에, 많은 열이 포함된 테이블에서는 성능에 영향을 줄 수 있습니다.
-- 모든 열 조회
SELECT * FROM employees;주의사항:
*를 사용하여 불필요한 데이터를 조회하는 것은 성능에 영향을 미칠 수 있습니다. 필요한 열만 선택하여 데이터를 조회하는 것이 일반적으로는 더 좋습니다.
3. SQL DML(Data Manipulation Language)
DML(Data Manipulation Language)은 SQL에서 데이터베이스에 저장된 데이터를 조작하는 명령어로 구성된 언어입니다.
- DML 명령어는 데이터를 조회(SELECT), 추가(INSERT), 수정(UPDATE), 삭제(DELETE)하는 작업을 수행하며, 데이터베이스의 CRUD 기능을 제공합니다.
- DML 명령어는 데이터의 변동이 잦은 데이터베이스에서 가장 자주 사용되며, 사용자 입력과 연동하여 애플리케이션의 데이터 조작에 활용됩니다.
- 주요 DML 명령어로는
SELECT, INSERT, UPDATE, DELETE가 있습니다.
이번 파트부터는 MySQL 예시 데이터를 활용해볼 것입니다.
- 다운로드 링크 : https://dev.mysql.com/doc/index-other.html
- 세팅 방법은 따로 다루진 않을 것이라서 아래 링크를 참고해서 본인의 환경에 맞게 설정하시면 됩니다.
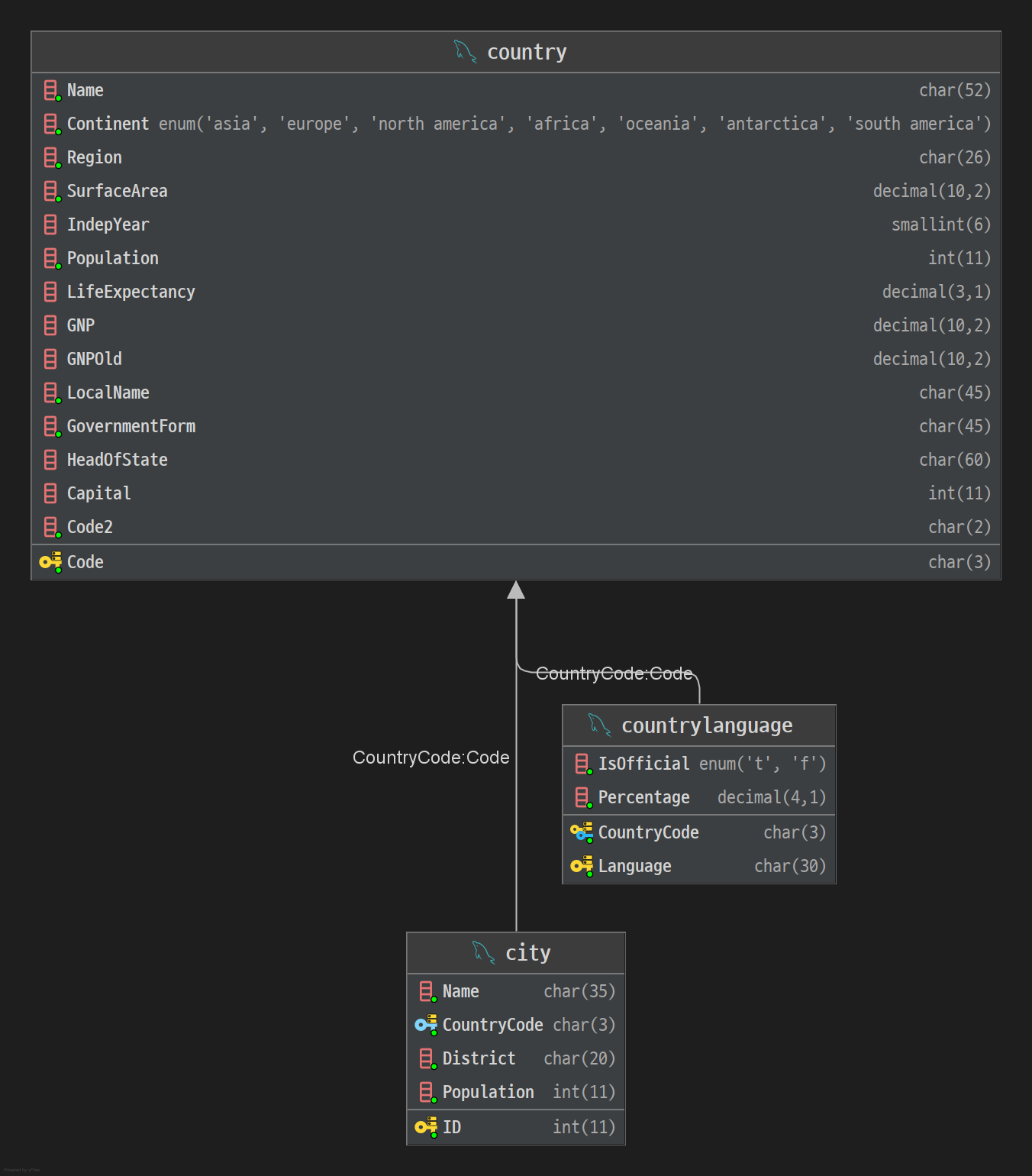
- 예시 데이터베이스 (
world.sql) 스키마 구조
3.1 Read (SELECT)
SELECT 명령어는 SQL에서 데이터를 조회하는 가장 기본적인 명령어입니다. SELECT 구문을 통해 테이블에서 특정 데이터를 선택하고, 필요한 열이나 행을 조건에 맞게 필터링하여 조회할 수 있습니다.
SELECT 기본 문법
SELECT column1, column2, ...
FROM table_name;1. FROM: 테이블 지정
FROM 절은 데이터를 가져올 테이블을 지정합니다. 데이터베이스 내 여러 테이블에서 원하는 테이블을 선택하여 데이터를 조회할 수 있습니다.
예시: country 테이블에서 모든 열을 조회
SELECT * FROM country;
2. WHERE: 조건 지정
WHERE 절은 특정 조건을 만족하는 행만 조회할 때 사용합니다. WHERE 절을 사용하면 필요한 데이터만 필터링하여 조회할 수 있습니다.
예시: country 테이블에서 인구가 1억 이상인 국가 조회
SELECT Name, Population
FROM country
WHERE Population >= 100000000;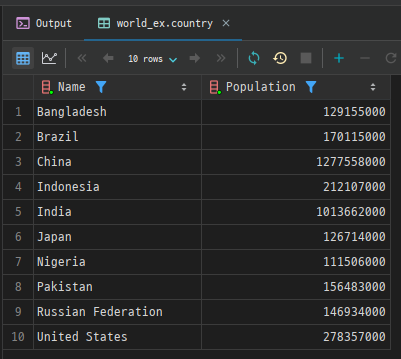
3. IS NOT NULL: NULL이 아닌 값 조회
IS NOT NULL 조건은 특정 열에 NULL이 아닌 값이 있는 행만 조회할 때 사용합니다. NULL 값은 데이터가 존재하지 않음을 의미하기 때문에, 이를 제외하고 조회할 수 있습니다. (반대로 IS NULL 조건으로 NULL값을 가지는 행만 조회할 수 있습니다)
예시: country 테이블에서 IndepYear 값이 NULL이 아닌 국가 조회
SELECT Name, IndepYear
FROM country
WHERE IndepYear IS NOT NULL;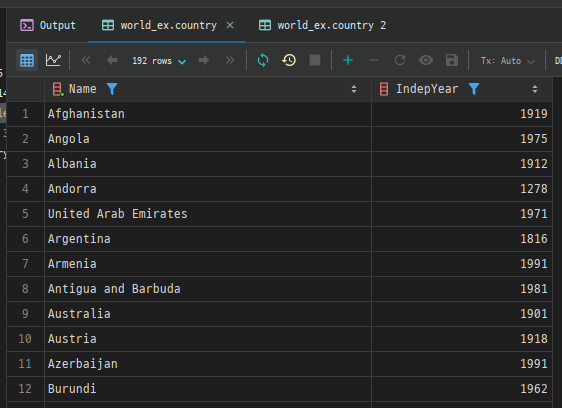
예시: country 테이블에서 IndepYear 값이 NULL인 국가 조회
SELECT Name, IndepYear
FROM country
WHERE IndepYear IS NULL;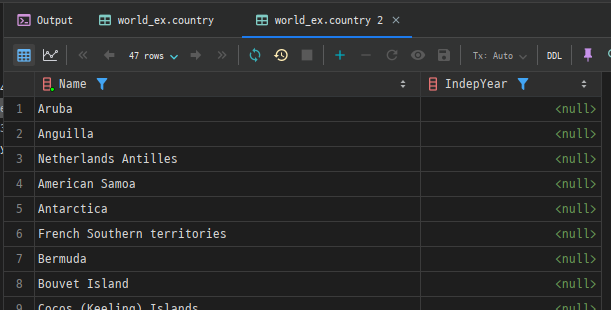
4. DISTINCT: 중복 값 제거
DISTINCT 키워드는 조회된 결과에서 중복 값을 제거하고 고유한 값을 반환합니다. 동일한 데이터가 중복으로 포함된 열에서 고유한 값만 필요할 때 유용합니다.
예시: country 테이블에서 고유한 대륙(Continent) 목록 조회
SELECT DISTINCT Continent
FROM country;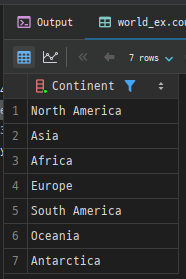
5. LIMIT: 결과 제한 및 시작 지점 지정
LIMIT 절은 조회 결과에서 반환할 행의 수를 제한할 때 사용됩니다. 많은 데이터를 조회할 때, 제한된 수만큼 데이터를 확인하고 싶을 때 유용합니다.
LIMIT절은 두 개의 인자를 사용할 수 있으며, 이를 통해 조회 결과의 시작 위치와 행 수를 지정할 수 있습니다.LIMIT row_count: 조회 결과의 상위row_count개의 행만 반환합니다.LIMIT offset, row_count:offset부터 시작하여row_count개의 행을 반환합니다.
- 이 기능은 페이징(pagination) 기능을 구현할 때 자주 사용됩니다.
- 예를 들어, 첫 번째 페이지는
LIMIT 0, 10으로 0번째 행부터 10개의 결과를, 두 번째 페이지는LIMIT 10, 10으로 10번째 행부터 10개의 결과를 조회할 수 있습니다.
- 예를 들어, 첫 번째 페이지는
예시: country 테이블에서 인구가 많은 상위 5개 국가 조회
SELECT Name, Population
FROM country
ORDER BY Population DESC
LIMIT 5;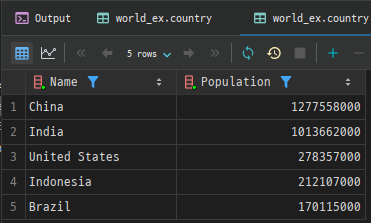
ORDER BY는 아래 쪽에서 다시 다룹니다.
예시: country 테이블에서 인구가 많은 국가를 조회하되, 10번째 결과부터 5개의 행을 반환
SELECT Name, Population
FROM country
ORDER BY Population DESC
LIMIT 10, 5;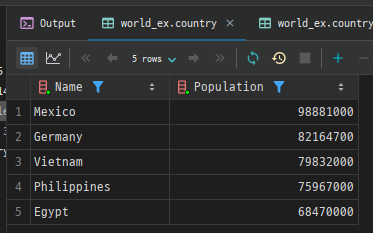
SELECT 종합 예시
아래 예시는 country 테이블에서 인구가 5천만 이상이고, 대륙이 아시아인 국가의 이름과 인구를 조회하는 쿼리입니다. 결과는 중복을 제거하고 최대 10개의 행만 반환합니다.
SELECT DISTINCT Name, Population
FROM country
WHERE Population >= 50000000 AND Continent = 'asia'
LIMIT 10;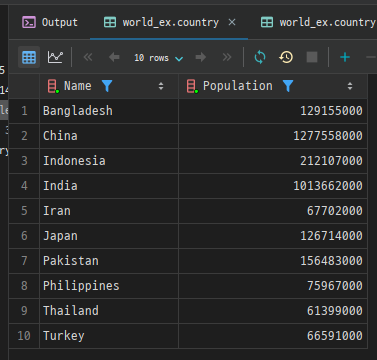
- 이 쿼리는 다음과 같은 요소를 포함하고 있습니다:
SELECT DISTINCT: Name과 Population을 조회하고 중복된 국가 이름은 제외FROM: country 테이블에서 조회WHERE: 인구가 5천만 이상이고, 대륙이 아시아인 조건LIMIT: 최대 10개의 행만 반환
3.2 Create (INSERT)
INSERT 명령어는 테이블에 새로운 레코드(행)을 추가할 때 사용됩니다. 데이터베이스에 새로운 데이터를 저장하여 정보를 지속적으로 유지하고 관리할 수 있습니다.
INSERT 기본문법
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);예시
예를 들어, city 테이블에 새로운 도시 정보를 추가하려면 다음과 같이 작성할 수 있습니다.
INSERT INTO city (Name, CountryCode, District, Population)
VALUES ('MyNewCity', # Name
'USA', # CountryCode
'MyDistrict', # District
2000000); # Population
# 결과 확인용
SELECT *
FROM city
WHERE CountryCode = 'USA'
AND Population >= 2000000;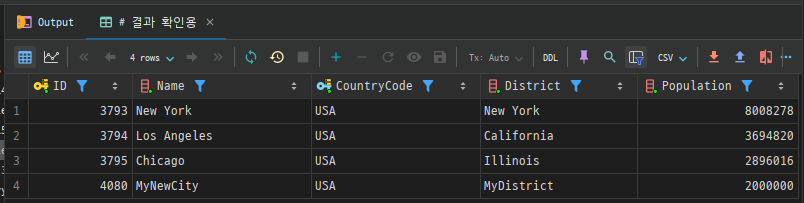
여러 행 삽입
한 번에 여러 행을 추가할 수도 있습니다. 행 별로 괄호를 나열하여 작성합니다.
INSERT INTO city (Name, CountryCode, District, Population)
VALUES
('CityA', 'USA', 'DistrictA', 2200000),
('CityB', 'USA', 'DistrictB', 2400000),
('CityC', 'USA', 'DistrictC', 2600000);
# 결과 확인용
SELECT *
FROM city
WHERE CountryCode = 'USA'
AND Population >= 2000000;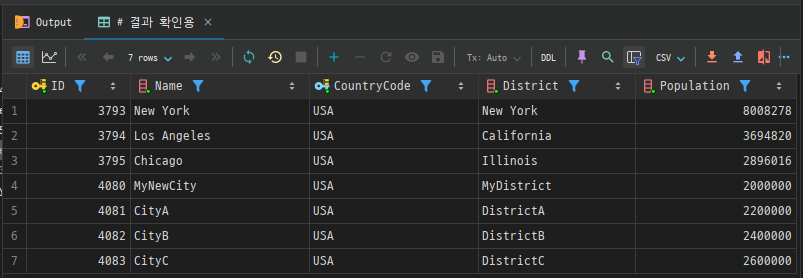
3.3 Update (UPDATE)
UPDATE 명령어는 기존의 레코드를 수정할 때 사용됩니다. 특정 조건을 만족하는 레코드의 값을 업데이트하며, 데이터를 최신 상태로 유지하거나 수정할 때 유용합니다.
UPDATE 기본문법
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;예시
예를 들어, city 테이블에서 도시 이름이 'CityA'인 도시의 인구를 3,000,000으로 업데이트하려면 다음과 같이 작성합니다.
UPDATE city
SET Population = 3000000
WHERE Name = 'CityA';
# 결과 확인용
SELECT *
FROM city
WHERE CountryCode = 'USA'
AND Population >= 2000000;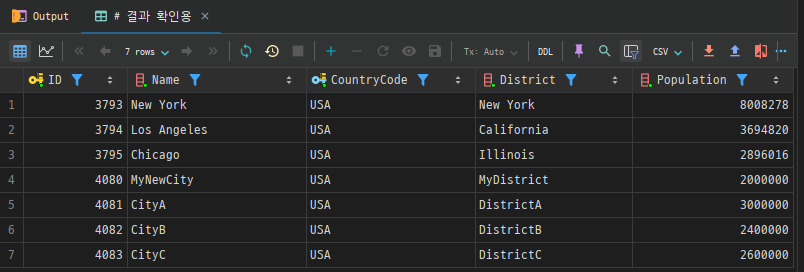
주의:
WHERE절을 생략하면 테이블의 모든 행이 업데이트됩니다. 이는 실수로 모든 데이터를 변경할 위험이 있으므로, 꼭 필요한 경우가 아니면 항상WHERE절을 포함하는 것이 좋습니다.
여러 열 업데이트
다수의 열을 동시에 업데이트할 수 있습니다.
UPDATE city
SET Population = 4000000, District = 'DistrictCCC'
WHERE Name = 'CityC';
# 결과 확인용
SELECT *
FROM city
WHERE CountryCode = 'USA'
AND Population >= 2000000;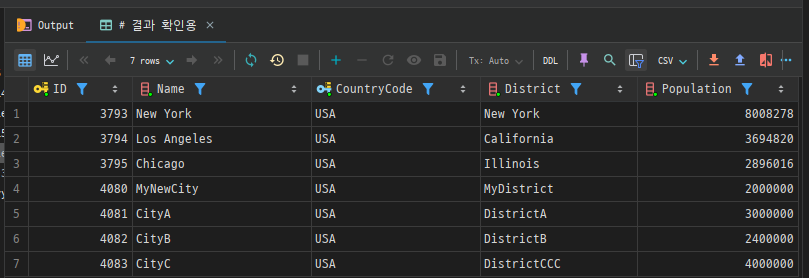
3.4 Delete (DELETE)
DELETE 명령어는 특정 조건을 만족하는 레코드를 삭제할 때 사용됩니다. 데이터베이스에서 불필요한 데이터나 더 이상 유효하지 않은 데이터를 제거하는 데 유용합니다.
DELETE 기본문법
DELETE FROM table_name
WHERE condition;예시
예를 들어, city 테이블에서 도시 이름이 'MyNewCity'인 도시를 삭제하려면 다음과 같이 작성합니다.
DELETE FROM city
WHERE Name = 'MyNewCity';
# 결과 확인용
SELECT *
FROM city
WHERE CountryCode = 'USA'
AND Population >= 2000000;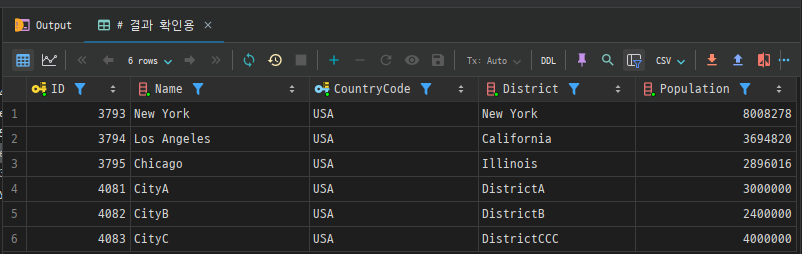
주의:
WHERE절을 생략하면 테이블의 모든 행이 삭제됩니다. 이로 인해 데이터 손실이 발생할 수 있으므로, 항상 필요한 경우에만 WHERE 절 없이 DELETE를 사용해야 합니다.
전체 데이터 삭제(DELETE)와 TRUNCATE의 차이점
- DELETE:
WHERE절 없이DELETE FROM table_name;을 사용할 경우 테이블의 모든 데이터를 삭제하지만, 테이블의 구조는 남아 있습니다. 또한, 삭제된 데이터에 대한 로그가 기록되므로 복구가 가능한 경우가 많습니다. - TRUNCATE:
TRUNCATE table_name;명령어를 사용하면 테이블의 모든 데이터를 삭제하고, 데이터 삭제에 대한 로그가 기록되지 않아 속도가 빠르지만 복구가 불가능합니다. 테이블의 구조는 유지됩니다.
DELETE FROM city; -- 테이블의 모든 데이터 삭제 (로그 기록, 느림)
TRUNCATE TABLE city; -- 테이블의 모든 데이터 삭제 (로그 없음, 빠름)4. JOIN & UNION
JOIN과 UNION은 SQL에서 여러 테이블의 데이터를 결합하여 조회할 때 사용됩니다.
JOIN은 서로 연관된 테이블의 데이터를 결합하는 반면,UNION은 두 개의 쿼리 결과를 합쳐주는 역할을 합니다.
4.1 JOIN
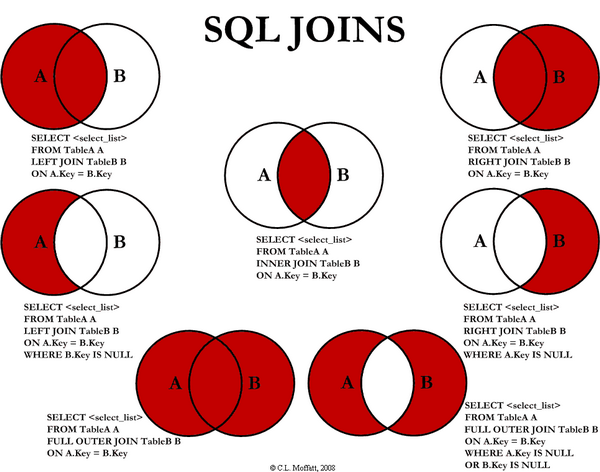
JOIN은 두 개 이상의 테이블을 결합하여 하나의 결과를 생성하는 방법으로, 테이블 간 관계를 정의하고 데이터를 조회할 때 유용합니다. JOIN에는 여러 종류가 있으며, 각 종류에 따라 결합 방식이 다릅니다.
- 여기선 대표적인 4가지 유형을 다루도록 하겠습니다.
JOIN 종류
- INNER JOIN: 두 테이블에서 조건에 일치하는 행만 결합합니다.
- LEFT JOIN:
왼쪽 테이블의 모든 행과오른쪽 테이블에서 조건에 맞는 행을 결합하며, 일치하지 않는 오른쪽 테이블의 값은 NULL로 표시됩니다. - RIGHT JOIN:
오른쪽 테이블의 모든 행과왼쪽 테이블에서 조건에 맞는 행을 결합하며, 일치하지 않는 왼쪽 테이블의 값은 NULL로 표시됩니다. - FULL OUTER JOIN: 두 테이블의 모든 행을 결합하며, 일치하지 않는 값은 NULL로 표시됩니다.
1. INNER JOIN
INNER JOIN은 두 테이블에서 조건에 일치하는 행만 결합합니다.
예시: country 테이블과 city 테이블을 국가 코드(CountryCode)를 기준으로 결합하여 각 국가의 수도를 조회합니다.
SELECT co.Name AS Country, ci.Name AS Capital
FROM country AS co
INNER JOIN city AS ci
ON co.Capital = ci.ID;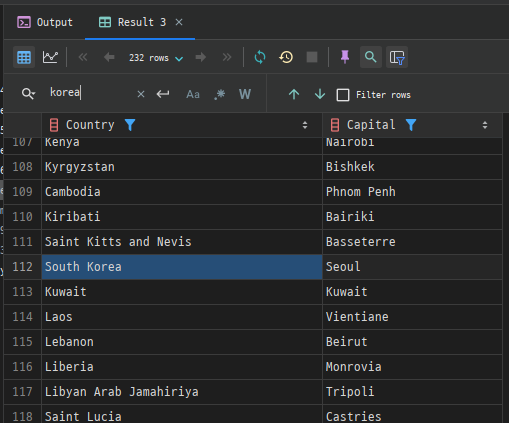
위 쿼리는 country와 city 테이블을 Capital과 ID 열을 기준으로 결합하여 각 국가의 수도 이름을 조회합니다.
2. LEFT JOIN (RIGHT JOIN)
LEFT JOIN은 왼쪽 테이블의 모든 행을 반환하며, 오른쪽 테이블에서 조건에 맞는 행이 있을 경우 해당 데이터를 결합하고, 일치하지 않으면 NULL로 표시됩니다.
RIGHT JOIN은 테이블 순서만 바꾸면 동일하게 동작합니다
예시: country 테이블과 countrylanguage 테이블을 국가 코드(Code)를 기준으로 결합하여 각 국가에서 사용되는 언어를 조회합니다. 국가 코드가 일치하지 않는 경우도 포함합니다.
SELECT co.Name AS Country, cl.Language, cl.IsOfficial
FROM country AS co
LEFT JOIN countrylanguage AS cl
ON co.Code = cl.CountryCode;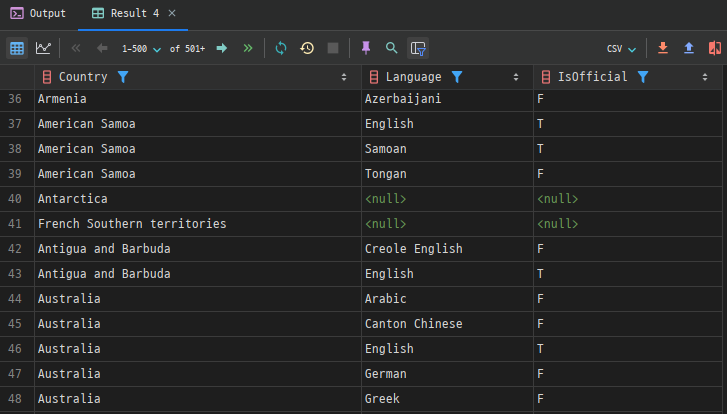
이 쿼리는 country 테이블의 모든 국가와 그 국가에서 사용되는 언어를 조회합니다. 언어 정보가 없는 나라는 NULL로 표시됩니다.
3. FULL OUTER JOIN
FULL OUTER JOIN은 두 테이블의 모든 행을 반환하며, 어느 한쪽에만 존재하는 경우에도 포함되며, 일치하지 않는 값은 NULL로 표시됩니다.
MySQL과MariaDB는FULL OUTER JOIN을 직접 지원하지 않기 때문에LEFT JOIN과RIGHT JOIN을UNION으로 조합하여 사용할 수 있습니다.- 예시는
UNION파트에서 함께 다루겠습니다.
4.2 UNION
UNION은 두 개 이상의 SELECT 쿼리 결과를 합치는 방법으로, 각 쿼리의 열 개수가 같아야 하며, 각 열의 데이터 타입도 서로 호환되어야 합니다.
UNION 기본문법
SELECT column1, column2, ...
FROM table1
UNION
SELECT column1, column2, ...
FROM table2;UNION과 UNION ALL의 차이
UNION: 중복되는 행을 제거하고 고유한 결과만 반환합니다.UNION ALL: 중복되는 행도 모두 포함하여 반환합니다.
예시 1 : country와 countrylanguage 테이블의 모든 국가와 언어를 결합하여 조회 (FULL OUTER JOIN)
SELECT co.Name AS Country, cl.Language
FROM country AS co
LEFT JOIN countrylanguage AS cl
ON co.Code = cl.CountryCode
UNION
SELECT co.Name AS Country, cl.Language
FROM countrylanguage AS cl
LEFT JOIN country AS co
ON co.Code = cl.CountryCode;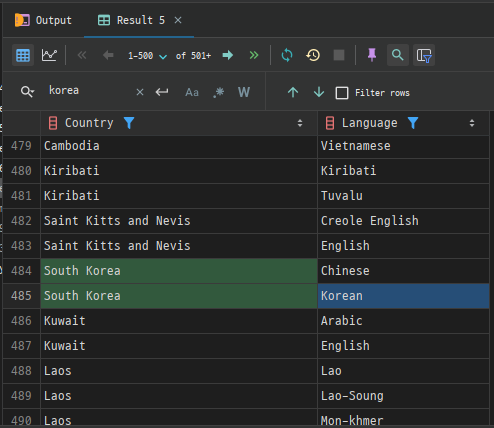
예시 2 : city 테이블에서 미국(USA)의 도시와 캐나다(CAN)의 도시를 조회하여 합칩니다.
SELECT Name, CountryCode, Population
FROM city
WHERE CountryCode = 'USA'
UNION
SELECT Name, CountryCode, Population
FROM city
WHERE CountryCode = 'CAN';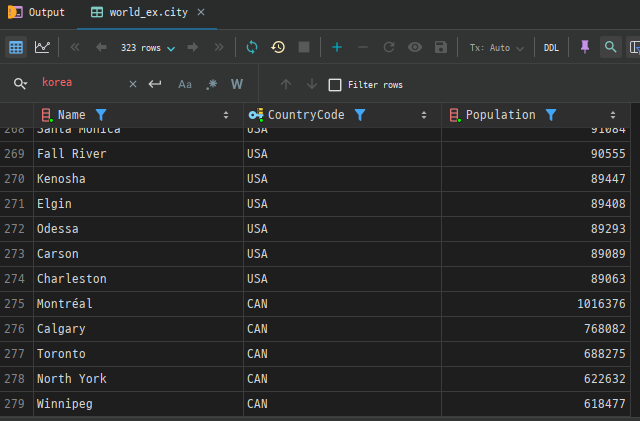
UNION ALL을 사용하여 중복도 포함하려면 다음과 같이 작성할 수 있습니다.
SELECT Name, CountryCode, Population
FROM city
WHERE CountryCode = 'USA'
UNION ALL
SELECT Name, CountryCode, Population
FROM city
WHERE CountryCode = 'CAN';5. Grouping (GROUP BY) & Sorting (ORDER BY)
GROUP BY와 ORDER BY는 SQL에서 데이터를 그룹화하거나 정렬할 때 사용되는 중요한 명령어입니다.
GROUP BY는 데이터를 특정 열을 기준으로 그룹화하여 집계 함수와 함께 사용하여 요약된 정보를 얻는 데 유용합니다.ORDER BY는 데이터를 지정된 열을 기준으로 오름차순 또는 내림차순으로 정렬할 때 사용됩니다.
5.1 GROUP BY
GROUP BY는 테이블의 데이터를 특정 열을 기준으로 그룹화하고, 각 그룹에 대해 집계 함수(예: COUNT, SUM, AVG, MAX, MIN)를 적용하여 요약된 정보를 조회할 수 있게 합니다.
- 집계함수는 다음 포스팅에서 자세히 다룹니다.
GROUP BY 기본 문법
SELECT column1, aggregate_function(column2)
FROM table_name
GROUP BY column1;예시 1. 대륙별 국가 수: country 테이블을 사용하여 대륙(Continent)별 국가 수를 구해 보겠습니다.
SELECT Continent, COUNT(*) AS CountryCount
FROM country
GROUP BY Continent;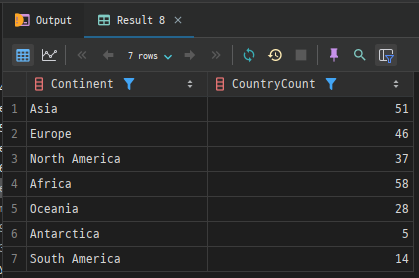
예시 2. 지역별 도시 평균 인구: city 테이블에서 미국(USA)의 지역(District)별 평균 인구를 조회합니다.
SELECT District, AVG(Population) AS AvgPopulation
FROM city
WHERE CountryCode = 'USA'
GROUP BY District;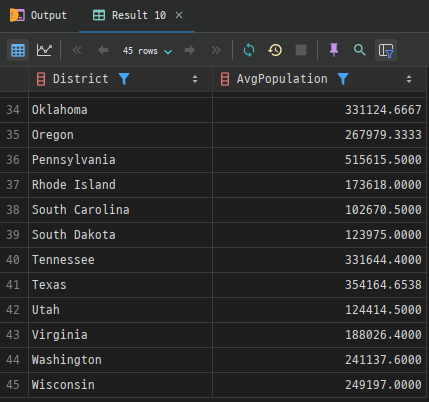
HAVING: 그룹화된 결과에 조건 적용
HAVING 절은 GROUP BY와 함께 사용하여 그룹화된 결과에 조건을 적용할 때 사용됩니다.
WHERE절은 그룹화 전에 개별 행을 필터링하는 데 사용되고,HAVING절은 그룹화 후 결과에 조건을 적용합니다.
예시 1+. 대륙별 국가 수 + HAVING: country 테이블을 사용하여 대륙(Continent)별 국가 수를 구한 테이블에서 국가 수가 30개 이상인 대륙만을 반환해보겠습니다.
SELECT Continent, COUNT(*) AS CountryCount
FROM country
GROUP BY Continent
HAVING COUNT(*) >= 30;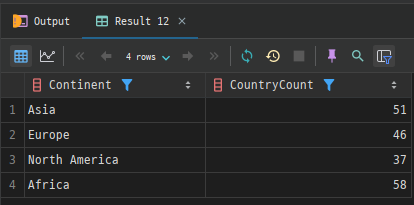
5.2 ORDER BY
ORDER BY는 조회된 데이터를 특정 열을 기준으로 오름차순 또는 내림차순으로 정렬하는 데 사용됩니다.
- 기본적으로는 오름차순(
ASC)으로 정렬되며, - 내림차순으로 정렬하려면
DESC를 지정합니다.
ORDER BY 기본 문법
SELECT column1, column2
FROM table_name
ORDER BY column1 [ASC|DESC];예시 1. 인구가 많은 국가 조회: country 테이블에서 인구가 많은 순서대로 국가를 조회합니다.
SELECT Name, Population
FROM country
ORDER BY Population DESC; # 내림차순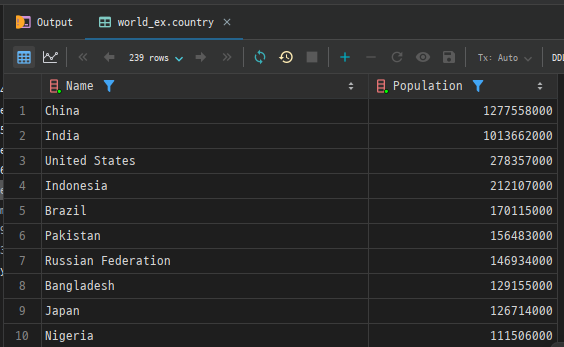
예시 2. 지역별 도시 이름을 알파벳 순서로 조회: city 테이블에서 특정 지역(District)의 도시 이름을 알파벳 순서로 정렬합니다.
SELECT Name, District
FROM city
WHERE District = 'California'
ORDER BY Name ASC; # 오름차순 (ASC 생략가능)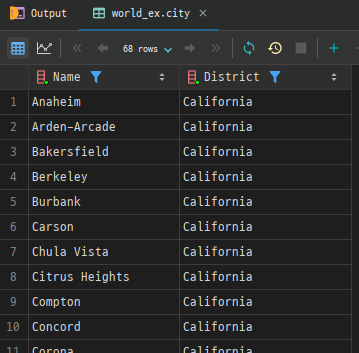
GROUP BY와 ORDER BY 함께 사용하기
GROUP BY와 ORDER BY는 함께 사용할 수 있으며, 각 그룹의 결과를 정렬하여 원하는 결과를 얻을 수 있습니다.
예시: country 테이블에서 대륙별 국가 수를 구한 후, 국가 수가 많은 대륙 순으로 정렬합니다.
SELECT Continent, COUNT(*) AS CountryCount
FROM country
GROUP BY Continent
ORDER BY CountryCount DESC;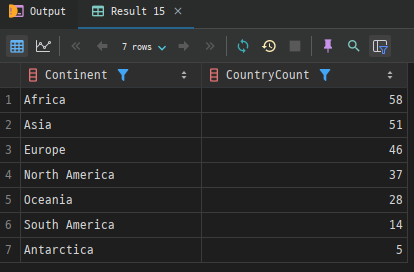
이와 같이 GROUP BY와 ORDER BY를 사용하여 데이터를 그룹화하고 정렬함으로써, 더 나은 분석과 데이터 요약이 가능합니다.
GROUP BY는 집계 함수와 함께 사용하여 데이터를 요약하고,ORDER BY는 결과를 보기 쉽게 정렬하는 데 중요한 역할을 합니다.
6. SQL 작성 순서 및 실행 순서
SQL 쿼리를 작성할 때는 일반적으로 SELECT 문법에 따른 작성 순서로 작성하지만, 데이터베이스 엔진은 실제 쿼리를 처리할 때 내부적으로 실행 순서에 따라 처리합니다.
- 작성 순서와 실행 순서를 이해하면, 쿼리의 동작 방식을 더 깊이 이해하고 성능을 최적화할 수 있습니다.
6.1 SQL 작성 순서
SQL 작성 순서는 쿼리의 논리적인 순서로, 일반적으로 다음과 같은 순서를 따릅니다.
SELECT: 반환할 열을 지정DISTINCT: 중복 제거
FROM: 데이터를 가져올 테이블 지정JOIN: 다른 테이블과의 결합ON: JOIN의 조건 지정
WHERE: 행을 필터링할 조건 지정GROUP BY: 특정 열을 기준으로 그룹화HAVING: 그룹화된 결과에 조건 적용
ORDER BY: 결과 정렬LIMIT: 결과의 개수 제한OFFSET: 시작 위치 지정
예시
SELECT DISTINCT c.Name AS CountryName,
MAX(c.Population) AS MaxPopulation
FROM country AS c
JOIN city ON c.Code = city.CountryCode
WHERE c.Population > 1000000
GROUP BY c.Name
HAVING COUNT(c.Name) > 1
ORDER BY MaxPopulation DESC
LIMIT 10
OFFSET 5;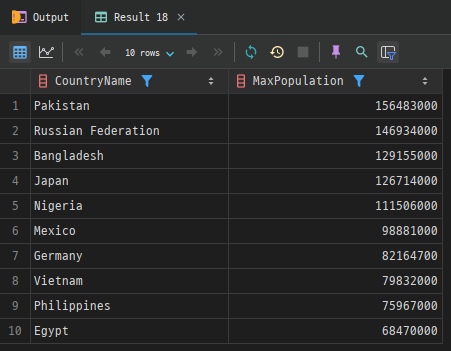
6.2 SQL 실행 순서
SQL의 실행 순서는 데이터베이스 엔진이 쿼리를 처리하는 실제 순서로, 효율적인 데이터 검색을 위해 작성 순서와 다르게 처리됩니다.
- 실행 순서를 이해하면 쿼리의 동작 원리를 파악하고, 복잡한 쿼리의 성능을 개선할 수 있습니다.
FROM: 데이터를 가져올 테이블 결정ON: JOIN 조건을 확인하여 테이블을 결합JOIN: 테이블 간의 결합 수행
WHERE: 필터링 조건 적용하여 행 선택GROUP BY: 특정 열을 기준으로 데이터 그룹화HAVING: 그룹화된 데이터에 조건 적용
SELECT: 반환할 열을 선택DISTINCT: 중복 행 제거ORDER BY: 지정된 열을 기준으로 정렬LIMIT: 결과 행 수 제한OFFSET: 시작 위치 지정
예시와 비교
위의 작성 예시 쿼리를 기준으로 보면, 데이터베이스 엔진은 FROM 절에서 시작하여 OFFSET 절까지의 순서로 쿼리를 처리합니다.
- 예를 들어,
JOIN은FROM과ON절 이후에 처리되며,WHERE필터링이 적용된 후에GROUP BY가 처리됩니다.SELECT,DISTINCT,ORDER BY,LIMIT은 마지막에 수행됩니다.
마무리
이번 포스팅에서는 SQL의 기본 개념과 DML(Data Manipulation Language)을 통한 CRUD 작업을 비롯해, JOIN과 UNION을 사용한 다중 테이블 결합, GROUP BY 및 ORDER BY를 통한 데이터 그룹화와 정렬까지 다루었습니다.
또한, SQL 작성 및 실행 순서에 대한 이해를 통해 SQL 쿼리의 처리 흐름을 파악하고 성능을 최적화하는 방법도 살펴보았습니다.
이처럼 SQL은 데이터를 효율적으로 관리하고 분석하는 데 필수적인 도구입니다.
- 이번 포스팅을 통해 기본적인 SQL 문법과 기능을 익히셨다면, 실제 데이터를 다루며 연습해 보시는 것을 추천합니다.
- 연습을 통해 쿼리 작성에 익숙해지고, 데이터베이스에서 원하는 데이터를 손쉽게 추출할 수 있는 능력을 기를 수 있을 것이라 믿습니다.
다음 포스팅에서는 SQL 내장 함수, 조건문, 그리고 서브쿼리를 다루어, 보다 심화된 데이터 처리와 분석 방법을 알아보겠습니다.
- 내장 함수를 사용하면 데이터를 더욱 쉽게 집계하고 계산할 수 있으며, 서브쿼리를 통해 복잡한 쿼리도 간단하게 작성할 수 있습니다.
