
본 시리즈에서는 데이터베이스의 개념을 정리하고 필요시 실습을 진행합니다.
- 실습 환경(Server)
- 원격 서버 (OS) : AWS-EC2 (
Ubuntu-24.04) - DBMS(관리 시스템) : MariaDB (
10.11.8-MariaDB)
- 원격 서버 (OS) : AWS-EC2 (
- 실습 환경(Client)
- Client OS : Windows 11
- DB Tool (IDE) : JetBrains DataGrip (
2024.2.2) - Java (JDBC) : JDK 21 (
correto-21) - Java IDE : IntelliJ IDEA (
Ultimate Edition)
- DB 실습 예제
- MySQL
world database - https://dev.mysql.com/doc/index-other.html
- MySQL
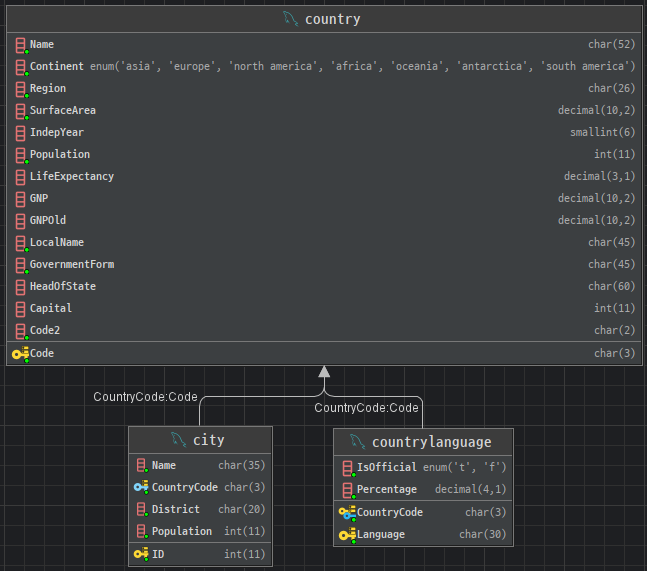
DataBase - SQL 가상테이블 & 내장함수 & SUBQUERY
1. 가상 Table(View Table & Dual Table)
1.1 View Table
View(뷰)는 가상 테이블로, 실제 데이터를 저장하지 않고 기존 테이블에서 생성한 쿼리 결과를 저장하여 사용합니다.
- 복잡한 쿼리를 단순화하거나 데이터 접근 권한을 제한할 때 유용하게 사용됩니다.
- 뷰를 통해 데이터를 조회하면, 뷰에 정의된 쿼리가 실행되어 실시간 데이터가 조회됩니다.
View의 주요 특징
- 가상 테이블
View는 데이터가 아닌 쿼리의 결과를 기반으로 만들어진 가상의 테이블입니다.
- 데이터 보호
- 특정 컬럼만 포함하거나 조건을 설정하여 민감한 정보를 보호할 수 있습니다.
- 복잡한 쿼리의 단순화
- 복잡한 쿼리를
View로 정의하여 쉽게 재사용할 수 있습니다.
- 복잡한 쿼리를
View 생성 및 사용 예시
기존 city 테이블에서 인구가 9,000,000 이상인 도시만 포함된 View를 생성한다고 가정해보겠습니다.
View생성
# view 생성
CREATE VIEW large_cities AS
SELECT Name, CountryCode, Population
FROM city
WHERE Population > 9000000;View조회
# view 조회
SELECT * FROM large_cities;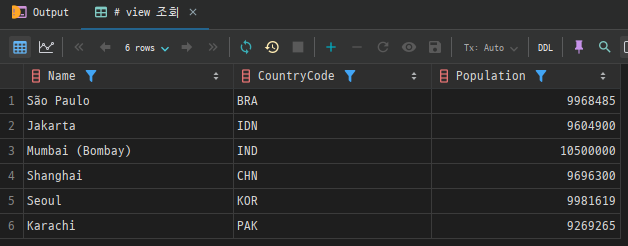
View삭제
# view 삭제
DROP VIEW large_cities;View의 활용 사례
View는 보고서나 특정 사용자에게 데이터를 제한적으로 제공해야 할 때 유용합니다.
- 예를 들어, 회사 내 재무 데이터를 볼 수 있는 사용자에게 특정 컬럼만 포함된 View를 제공함으로써, 민감한 정보에 대한 접근을 제한할 수 있습니다.
1.2 Dual Table
Dual Table은 Oracle에서 주로 사용하는 임시 테이블로, 쿼리에 실제 테이블이 필요하지 않을 때 사용됩니다.
- 예를 들어, 상수 값을 반환하거나 내장 함수를 테스트할 때 유용합니다.
MySQL혹은MariaDB에서는Dual Table을 사용할 필요는 없지만, 호환성이나 다른 데이터베이스 환경을 고려할 때Dual Table의 개념을 이해해두는 것이 좋습니다.
Dual Table의 특징
- 하나의 행과 하나의 열로 구성된 테이블로, 주로 상수 또는 함수 결과를 반환할 때 사용됩니다.
Oracle에서만 필수적으로 사용되며,MySQL/MariaDB에서는 생략 가능합니다.- 즉,
MySQL/MariaDB에서는 명시적으로 사용해도 큰 문제가 되지 않습니다.
- 즉,
Dual Table 사용 예시
- 상수 반환:
Dual테이블을 사용하여 상수 값을 반환할 수 있습니다.
SELECT 1 FROM DUAL;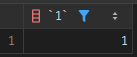
- 함수 테스트:
Dual테이블을 사용하여 함수를 테스트하거나 간단한 계산을 수행할 수 있습니다.
SELECT NOW() AS CurrentDate FROM DUAL;- MySQL에서의 Dual Table 사용:
MySQL(MariaDB)에서는Dual 테이블없이도 동일한 쿼리를 실행할 수 있습니다. 예를 들어, 아래와 같이 테이블을 생략할 수 있습니다.
SELECT NOW() AS CurrentDate;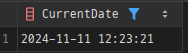
Dual Table의 활용 사례
- 시스템 날짜나 고정 값을 조회하거나 연산을 테스트할 때 사용합니다.
- 예를 들어,
NOW()와 같은 날짜 함수를 실행하여 현재 시간을 확인하거나,PI()와 같은 수학 함수를 테스트할 때 사용합니다.
2. SQL 내장함수
2.1 내장 함수 개요
SQL 내장 함수는 데이터베이스 벤더(Oracle, MySQL 등)에서 기본적으로 제공하는 함수로, SQL 쿼리에서 데이터 조회와 분석을 쉽게 할 수 있게 도와줍니다.
- 사용자가 직접 정의할 수 있는 사용자 정의 함수도 있지만, 일반적인 경우엔 데이터베이스에서 제공하는 기본 함수들을 주로 사용합니다.
- 사용자 정의 함수에 관해선 다뤄야할 내용이 많아서 다음 포스팅에서 자세히 다룹니다.
내장 함수는 크게 두 가지로 구분됩니다:
- 단일행 함수
- 하나의 입력값에 대해 하나의 결과를 반환합니다.
문자형,숫자형,날짜형함수 등이 여기에 해당합니다.
- 다중행 함수
- 여러 행의 값을 입력으로 받아 하나의 결과를 반환하는 함수입니다.
집계함수와그룹함수가 대표적이며,SUM,AVG,COUNT등이 포함됩니다.
2.2 단일행 함수
단일행 함수는 하나의 행을 입력으로 받아 해당 행에 대한 결과를 반환하는 함수입니다.
- 일반적으로 문자형 함수, 숫자형 함수, 날짜형 함수, 변환형 함수, NULL 처리 함수로 분류할 수 있습니다.
- 문자형 함수
| 함수 | 설명 | 예제 |
|---|---|---|
| UPPER() | 문자열을 대문자로 변환 | UPPER('hello') → 'HELLO' |
| LOWER() | 문자열을 소문자로 변환 | LOWER('HELLO') → 'hello' |
| CONCAT() | 여러 문자열을 하나로 결합 | CONCAT('Hello', ' ', 'World') → 'Hello World' |
| SUBSTRING() | 문자열의 일부를 추출 | SUBSTRING('Hello', 1, 3) → 'Hel' |
| LENGTH() | 문자열의 길이를 반환 | LENGTH('Hello') → 5 |
| TRIM() | 문자열 양 끝의 공백을 제거 | TRIM(' Hello ') → 'Hello' |
| REPLACE() | 문자열 내 특정 문자를 다른 문자로 대체 | REPLACE('Hello World', 'World', 'SQL') → 'Hello SQL' |
- 숫자형 함수
| 함수 | 설명 | 예제 |
|---|---|---|
| ROUND() | 지정된 자릿수로 반올림 | ROUND(123.456, 2) → 123.46 |
| ABS() | 절대값 반환 | ABS(-10) → 10 |
| CEIL() | 주어진 값보다 큰 가장 작은 정수 반환 | CEIL(10.2) → 11 |
| FLOOR() | 주어진 값보다 작은 가장 큰 정수 반환 | FLOOR(10.8) → 10 |
| POWER() | 지정된 거듭제곱 계산 | POWER(2, 3) → 8 |
| MOD() | 두 숫자 간의 나머지 반환 | MOD(10, 3) → 1 |
- 날짜형 함수
| 함수 | 설명 | 예제 |
|---|---|---|
| NOW() | 현재 날짜와 시간 반환 | NOW() → 2023-05-12 10:30:00 |
| DATE_ADD() | 날짜에 지정된 기간을 더함 | DATE_ADD('2023-05-12', INTERVAL 10 DAY) → '2023-05-22' |
| DATEDIFF() | 두 날짜 간의 차이 일수 반환 | DATEDIFF('2023-05-22', '2023-05-12') → 10 |
| YEAR() | 날짜에서 연도를 추출 | YEAR('2023-05-12') → 2023 |
| DATE_FORMAT() | 날짜를 지정된 형식으로 변환 | DATE_FORMAT('2023-05-12', '%Y/%m/%d') → '2023/05/12' |
| STR_TO_DATE() | 문자열을 날짜 형식으로 변환 | STR_TO_DATE('12-05-2023', '%d-%m-%Y') → '2023-05-12' |
- 변환형 함수
| 함수 | 설명 | 예제 |
|---|---|---|
| CAST() | 데이터 타입을 변환 | CAST('123' AS INT) → 123 |
| CONVERT() | 데이터 타입을 변환 | CONVERT('123', SIGNED) → 123 |
| FORMAT() | 숫자를 지정된 문자열로 변환 | FORMAT(1234567.8912, 2) → '1,234,567.89' |
- NULL 관련 함수
| 함수 | 설명 | 예제 |
|---|---|---|
| IFNULL() | NULL일 경우 대체값 반환 | IFNULL(NULL, 'default') → 'default' |
| COALESCE() | NULL이 아닌 첫 번째 값 반환 | COALESCE(NULL, NULL, 'value') → 'value' |
2.3 다중행 함수
다중행 함수는 여러 행의 값을 입력으로 받아 하나의 결과를 반환하는 함수로, 주로 집계 함수라고도 불립니다. 그룹화된 데이터의 요약 정보를 얻는 데 유용합니다.
| 함수 | 설명 | 예제 |
|---|---|---|
| SUM() | 값의 합계 반환 | SUM(salary) |
| AVG() | 값의 평균 반환 | AVG(age) |
| COUNT() | 행의 개수 반환 | COUNT(*) |
| MAX() | 최대값 반환 | MAX(salary) |
| MIN() | 최소값 반환 | MIN(salary) |
3. SUBQUERY
서브쿼리(Subquery)는 SQL에서 쿼리 내에 포함된 또 다른 쿼리입니다.
- 주로 메인 쿼리의 조건을 더 구체적으로 지정하거나 특정 값을 제공하는 데 사용됩니다.
- 내부 쿼리라고도 불리며,
SELECT,FROM,WHERE,HAVING등의 절에서 주로 사용됩니다.
서브쿼리는 결과를 반환하여 메인 쿼리의 조건이나 값으로 사용되며, 쿼리를 단계별로 실행할 수 있는 유연성을 제공합니다.
- 다만 너무 남용하면 가독성이 상당히 떨어질 수 있어서 다소 주의가 필요합니다.
3.1 서브쿼리의 특징
- 단일 값 반환 서브쿼리:
하나의 값만 반환하여 메인 쿼리에서 단일 값을 비교할 때 사용됩니다. - 다중 값 반환 서브쿼리:
여러 행을 반환하며, 메인 쿼리의IN,ANY,ALL조건과 함께 사용됩니다. - 상관 서브쿼리: 서브쿼리가 메인 쿼리의 행마다 다시 실행되어 조건을 만족하는 값을 찾습니다.
- 위치:
SELECT,FROM,WHERE,HAVING절 등에 위치할 수 있으며, 상황에 따라 다양한 방식으로 사용됩니다.
3.2 서브쿼리 사용 위치와 예제
-
SELECT 절에서의 서브쿼리
SELECT절에서 서브쿼리를 사용하여 특정 열에 대한 계산 결과를 반환할 수 있습니다.예제 : 각 나라의 수도 이름을 조회하고, 각 수도의 도시 인구 수를 함께 조회
SELECT country.Name AS Country, (SELECT city.Name FROM city WHERE city.ID = country.Capital) AS Capital, (SELECT Population FROM city WHERE city.ID = country.Capital) AS CapitalPopulation FROM country; -
FROM 절에서의 서브쿼리
FROM절에 서브쿼리를 사용하여 임시 테이블을 생성하고, 이를 메인 쿼리의 데이터 원본으로 사용할 수 있습니다.예제: 각 대륙별로 인구가 가장 많은 국가와 그 인구 수를 조회
SELECT subquery.Continent, country.Name AS LargestCountry, subquery.MaxPopulation FROM ( SELECT Continent, MAX(Population) AS MaxPopulation FROM country GROUP BY Continent ) AS subquery JOIN country ON country.Continent = subquery.Continent AND country.Population = subquery.MaxPopulation; -
WHERE 절에서의 서브쿼리
WHERE절에서 서브쿼리는 특정 조건을 지정하는 데 유용하며, 메인 쿼리의 필터링 조건으로 사용할 수 있습니다.예제:
country테이블에서 인구가 전체 평균 인구 이상인 국가를 조회SELECT Name, Population FROM country WHERE Population >= (SELECT AVG(Population) FROM country); -
HAVING 절에서의 서브쿼리
HAVING절에서 서브쿼리는 그룹화된 결과에 대해 조건을 지정할 때 유용합니다.예제: country 테이블에서 각 대륙별로 평균 인구보다 인구가 많은 국가 조회
SELECT Continent, Name, Population
FROM country
GROUP BY Continent, Name
HAVING Population > (SELECT AVG(Population) FROM country WHERE country.Continent = Continent);- 다만,
HAVING절은 주로 집계 함수의 결과에 조건을 걸 때 주로 사용됩니다.- 다시말해서,
HAVING절은 그룹화된 데이터에 대해 집계 함수로 계산된 결과에 조건을 추가할 때 최적화되어 있기 때문에, 서브쿼리가 들어가면 성능상 비효율적일 수 있습니다.
- 다시말해서,
- 그래서, 서브쿼리는 가능한
WHERE절에서 사용하는 것이 일반적이며,HAVING절에서 서브쿼리를 사용하는 경우는 많지 않습니다.- 따라서
HAVING절에 서브쿼리를 사용해야 하는 상황이라면, 쿼리를 재구성하거나WHERE절을 활용할 방법을 고려하는 것이 좋습니다.
- 따라서
3.3 상관 서브쿼리 (Correlated Subquery)
상관 서브쿼리(Correlated Subquery)는 메인 쿼리의 각 행에 대해 서브쿼리가 실행되는 방식으로, 메인 쿼리와 서브쿼리가 서로 상호 참조합니다. 상관 서브쿼리는 메인 쿼리와 서브쿼리가 상호 종속적으로 실행됩니다.
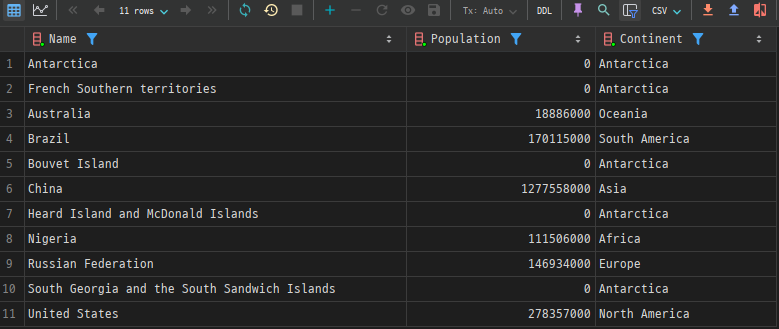
예제: country 테이블에서 자신의 대륙에서 인구가 가장 많은 국가 조회
SELECT Name, Population, Continent
FROM country AS c1
WHERE Population = (
SELECT MAX(Population)
FROM country AS c2
WHERE c2.Continent = c1.Continent
);
3.4 서브쿼리와 EXISTS
EXISTS는 서브쿼리가 결과를 반환하는지 여부를 확인하며, 서브쿼리가 결과를 반환하면 TRUE, 그렇지 않으면 FALSE를 반환합니다. 주로 조건을 효율적으로 필터링할 때 사용됩니다.
예제: city 테이블에 도시가 있는 국가만 조회
SELECT Name
FROM country
WHERE EXISTS (SELECT 1 FROM city WHERE city.CountryCode = country.Code);마무리
이번 포스팅에서는 SQL 내장 함수와 서브쿼리에 대해 깊이 있게 다루었습니다.
- 내장 함수는 SQL에서 데이터를 가공하고 분석하는 데 필수적인 도구이며, 데이터베이스에서 기본적으로 제공하는 다양한 함수들을 활용하여 복잡한 쿼리를 더욱 간단하게 작성할 수 있었습니다.
- 서브쿼리는 SQL 쿼리의 유연성을 높여 주는 강력한 도구로, 다양한 절에서의 활용 방법과 주의 사항까지 다루며 실습 예제와 함께 다루어 보았습니다.
특히 서브쿼리를 사용할 때는 가독성과 성능 최적화에 유의해야 합니다.
- 서브쿼리는 다양한 상황에서 유용하지만, 경우에 따라
JOIN을 사용하여 대체하거나WHERE절을 활용하는 것이 더 효율적일 수 있습니다. - 쿼리 성능을 최적화하고자 한다면, 서브쿼리 사용을 최소화하고 쿼리 작성 순서와 실행 순서에 대한 이해를 바탕으로 쿼리를 재구성하는 것이 좋습니다.
다음 포스팅에서는 SQL에서 로직을 구현하는 조건문(CASE문)과 사용자 정의 함수, 프로시저, 트리거에 대해 다룰 예정입니다.
