
본 시리즈에서는 데이터베이스의 개념을 정리하고 필요시 실습을 진행합니다.
- 실습 환경(Server)
- 원격 서버 (OS) : AWS-EC2 (
Ubuntu-24.04) - DBMS(관리 시스템) : MariaDB (
10.11.8-MariaDB)
- 원격 서버 (OS) : AWS-EC2 (
- 실습 환경(Client)
- Client OS : Windows 11
- DB Tool (IDE) : JetBrains DataGrip (
2024.2.2) - Java (JDBC) : JDK 21 (
correto-21) - Java IDE : IntelliJ IDEA (
Ultimate Edition)
- DB 실습 예제
- MySQL
world database - https://dev.mysql.com/doc/index-other.html
- MySQL
DataBase - SQL Logic (CASE, FUNCTION, PROCEDURE, TRIGGER)
0. SQL 로직 구현 개요
데이터베이스에서 로직 구현은 단순히 데이터를 저장하고 조회하는 것 이상의 역할을 수행하며, 데이터의 정합성과 무결성을 유지하는 데 중요한 역할을 합니다.
SQL을 통해 로직을 구현하는 다양한 방식들이 존재하며, 이러한 요소들은 주로 조건 처리, 함수, 프로시저, 트리거를 사용하여 데이터베이스의 비즈니스 로직과 자동화된 데이터 처리를 지원합니다.
주요 SQL 로직 구현 도구 개요
1. CASE문 (조건문)
- CASE문은 SQL에서 조건별로 다른 값을 반환하고자 할 때 사용되는 조건문입니다.
- 여러 조건을 설정하여 동적 데이터 처리를 수행할 수 있으며, 특히 보고서 생성이나 특정 값의 변환에서 유용하게 사용됩니다.
- 주로
SELECT구문에서 동적인 값 설정이나 가독성을 위한 데이터 변환 목적으로 활용됩니다.
2. FUNCTION (사용자 정의 함수)
- 함수(Function)는 SQL에서 특정 값을 계산하여 반환하는 로직 단위로, 특정 작업을 수행한 후 단일 값을 반환합니다.
- 사용자 정의 함수를 통해 복잡한 연산을 재사용 가능하게 하고, 쿼리 내에서 간결하게 계산 로직을 처리할 수 있습니다.
- 단일 값 반환이라는 특성상 계산식, 형 변환, 복잡한 조건 등을 반복적으로 사용해야 할 때 유용합니다.
3. PROCEDURE (프로시저)
- 프로시저(Procedure)는 특정 작업을 수행하기 위해 SQL에서 정의된 일련의 명령어 블록으로, 다수의 작업을 묶어 실행할 수 있습니다.
함수와 달리 여러 개의 값을 반환하거나 단순한 데이터 조작을 수행하는 데 유용하며, 입력 및 출력 매개변수를 활용하여 복잡한 데이터 로직을 처리할 수 있습니다.- 주로 복잡한 트랜잭션이나 일괄 처리 작업을 자동화할 때 사용됩니다.
4. TRIGGER (트리거)
- 트리거(Trigger)는 테이블의 특정 이벤트(INSERT, UPDATE, DELETE)가 발생할 때 자동으로 실행되는 SQL 구문입니다.
- 데이터가 변경될 때마다 자동으로 실행되어 데이터 무결성을 유지하고, 특정 로직을 데이터 조작과 동시에 수행할 수 있습니다.
- 데이터의 추가, 수정, 삭제 시 자동화된 검증이나 연관된 테이블의 데이터 동기화 등에 주로 활용됩니다.
SQL 로직 구현의 중요성
- 자동화와 효율성
- 로직을 미리 정의하여 데이터베이스가 자동으로 데이터를 처리하게 할 수 있으며, 이는 사용자 개입을 줄이고 효율성을 높입니다.
- 비즈니스 로직 캡슐화
- SQL 로직을 통해 애플리케이션의 비즈니스 로직을 데이터베이스 내에 구현하여 데이터베이스와 애플리케이션의 일관성을 유지할 수 있습니다.
- 데이터 무결성
- 조건문, 트리거 등을 활용하여 데이터의 무결성을 강제하고, 예상치 못한 데이터 오류를 방지할 수 있습니다.
SQL의 다양한 로직 구현 도구를 통해 데이터베이스에서 복잡한 비즈니스 로직을 처리하고, 데이터 조작 자동화와 데이터 무결성 유지가 가능해집니다.
1. CASE문 (조건문)
CASE문은 SQL에서 조건에 따라 서로 다른 결과를 반환할 때 사용하는 조건문입니다.
- 특히 복잡한 쿼리나 데이터 변환이 필요한 경우에 유용하며, 다양한 조건에 따라 결과를 동적으로 설정할 수 있습니다.
1.1 CASE문의 기본 구문
SELECT
column1,
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE default_result
END AS alias_name
FROM table_name;WHEN: 조건을 지정합니다.WHEN에 지정된 조건이 참일 때 그에 해당하는result가 반환됩니다.
THEN: 조건이 참일 때 반환할 값을 지정합니다.ELSE: 모든 조건이 거짓일 때 반환할 기본값을 지정합니다.ELSE는 선택사항입니다.
END:CASE문을 종료합니다.AS alias_name: 결과 열에 별칭(alias)을 부여합니다.
1.2 CASE문 예시
- 단순 조건 사용
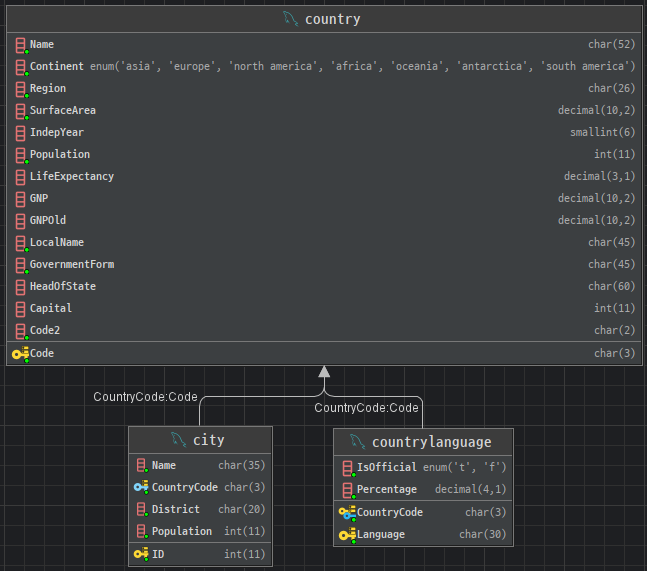
- 예를 들어,
country테이블에서 인구(Population)에 따라 국가를"대국", "중간국", "소국"으로 분류하고자 한다면 다음과 같이 작성할 수 있습니다:
- 예를 들어,
SELECT Name AS Country,
Population,
CASE
WHEN Population >= 100000000 THEN '대국'
WHEN Population >= 10000000 THEN '중간국'
ELSE '소국'
END AS SizeCategory
FROM country;- 위 쿼리는
Population값에 따라 각 국가가 속하는 범주를SizeCategory라는 별칭으로 반환합니다.
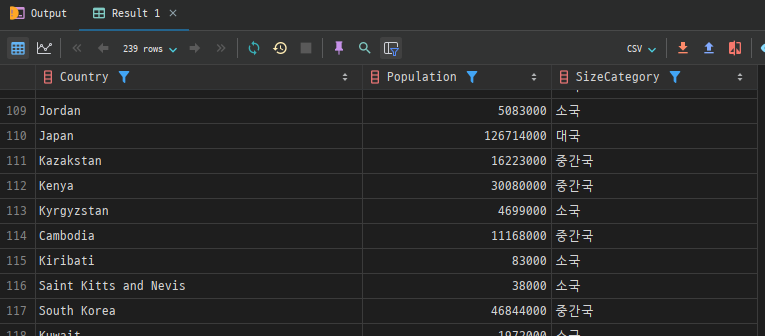
- 복수 조건 사용
CASE문은AND로 복수의 조건을 통해 좀 더 복잡한 논리 처리가 가능합니다.- 예를 들어,
city테이블에서 도시의 인구가1,000,000이상이고CountryCode가'USA'인 경우"미국 대도시"로, 그렇지 않으면"일반 도시"로 분류할 수 있습니다.
SELECT Name AS City,
Population,
CASE
WHEN Population >= 1000000 AND CountryCode = 'USA' THEN '미국 대도시'
ELSE '일반 도시'
END AS CityCategory
FROM city
WHERE CountryCode = 'USA';- 이 쿼리는
Population과CountryCode의 조합 조건을 활용하여 도시를 분류합니다.
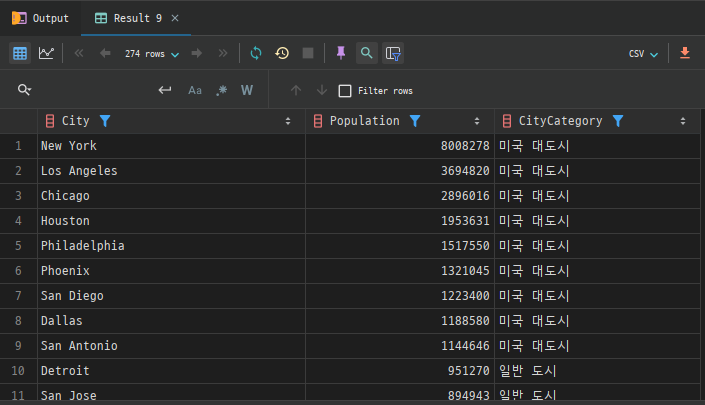
- CASE문과 함께 집계 함수 사용
CASE문은 집계 함수와 함께 사용하여 조건에 따라 집계 결과를 구할 수 있습니다.- 예를 들어,
country테이블에서 대륙(Continent)별로 인구가50,000,000이상인 국가의 수를 구하려면 다음과 같이 작성할 수 있습니다.
SELECT Continent,
COUNT(CASE WHEN Population >= 50000000 THEN 1 END) AS HighPopulationCountryCount
FROM country
GROUP BY Continent;- 이 쿼리는
Continent별로 인구가50,000,000이상인 국가의 개수를 집계하여 반환합니다.
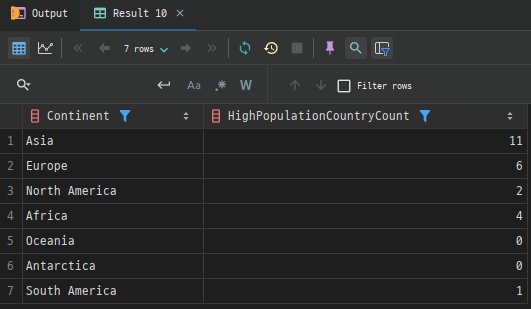
- CASE문과 함께 ORDER BY 사용
CASE문을ORDER BY절에서도 사용할 수 있습니다.- 예를 들어,
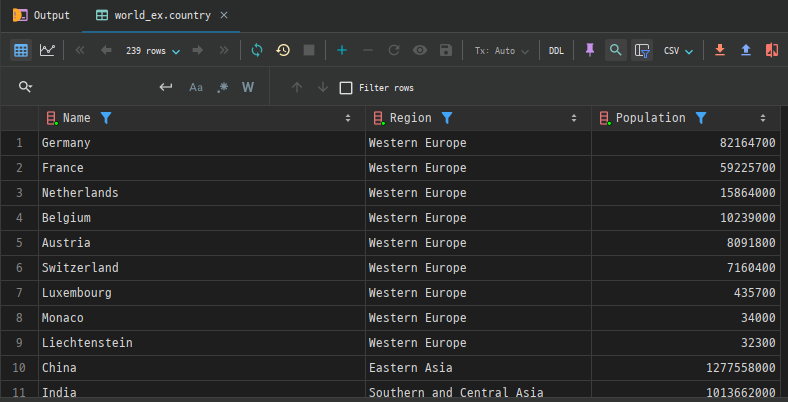
country테이블에서Region이"Western Europe"인 국가를 우선으로 정렬하고,그 외의 국가를 인구 순으로 정렬하고자 할 때 다음과 같이 작성할 수 있습니다.
SELECT Name, Region, Population
FROM country
ORDER BY
CASE WHEN Region = 'Western Europe' THEN 1 ELSE 2 END,
Population DESC;Western Europe에 속한 국가가 먼저 나오고, 그 외 국가들은 인구 내림차순으로 정렬됩니다.
1.3 CASE문의 장점과 유용성
- 가독성 향상
- 복잡한 조건을 간단하고 읽기 쉽게 표현할 수 있어 쿼리의 가독성을 높여줍니다.
- 다양한 조건 처리
- 여러 조건을 정의하여 복잡한 로직을 처리할 수 있습니다.
- 동적 값 변환
- 데이터의 값에 따라 동적으로 열을 생성할 수 있어, 특정 조건을 기반으로 결과를 변환하는 데 유용합니다.
참고:
CASE문은 SQL 쿼리의WHERE절에서는 사용할 수 없으며,SELECT,ORDER BY,GROUP BY등에서 주로 사용됩니다.
2. FUNCTION (사용자 정의 함수, UDF)
사용자 정의 함수(User-Defined Function, UDF)는 사용자가 정의한 논리를 SQL에서 재사용할 수 있는 함수입니다.
- 복잡한 계산이나 특정 데이터 변환을 반복해서 사용해야 할 때 함수로 정의해 두면 쿼리에서 쉽게 호출할 수 있습니다.
사용자 정의 함수(UDF)의 특징
- 입력 매개변수를 받을 수 있으며, 하나의 값을 반환합니다.
- 주로 반복되는 계산이나 데이터 변환 작업을 처리하기 위해 사용됩니다.
트랜잭션내에서 사용되거나 여러 쿼리에서 재사용할 수 있어 코드 재사용성과 유지보수성을 향상시킵니다.
2.1 FUNCTION의 기본 구문
CREATE FUNCTION function_name(parameter1 datatype, parameter2 datatype, ...)
RETURNS return_datatype
BEGIN
DECLARE variable_name datatype;
-- 함수 로직 (SQL 구문)
RETURN result;
END;CREATE FUNCTION: 함수를 정의하여 생성합니다. (DB의 routines 항목에 저장됩니다)function_name: 함수 이름을 지정합니다.parameter: 입력 매개변수로, 함수에 전달되는 값을 지정합니다.
RETURNS: 반환 타입을 지정합니다.BEGIN ... END: 함수 본체를 정의하는 구간으로, 내부에서 SQL 구문을 작성합니다.DECLARE: 함수 내부에서 사용할 변수를 선언합니다. (일종의 지역변수 입니다)
참고로 생성한 함수를 지우려면
DROP FUNCTION function_name;구문을 사용하시면 됩니다.
2.2 사용자 정의 함수 예시
1. 두 숫자의 합을 구하는 함수
- 간단한 예로, 두 개의 숫자를 받아서 합을 반환하는 함수를 정의해 보겠습니다.
CREATE FUNCTION add_numbers(a INT, b INT)
RETURNS INT
BEGIN
RETURN a + b;
END;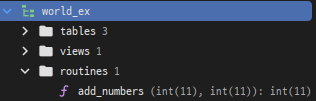
- 호출 예시
SELECT add_numbers(10, 20) -- 결과: 30
FROM dual;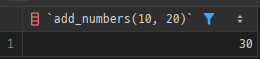
2. 도시 이름과 국가 코드로 해당 도시의 인구를 반환하는 함수
city테이블에서도시 이름과국가 코드를 입력받아 해당 도시의인구를 반환하는 함수를 만들어 보겠습니다.
CREATE FUNCTION get_city_population(city_name VARCHAR(50), country_code CHAR(3))
RETURNS INT
BEGIN
DECLARE population INT;
SELECT ct.Population INTO population
FROM city AS ct
WHERE ct.Name = city_name AND ct.CountryCode = country_code;
RETURN population;
END;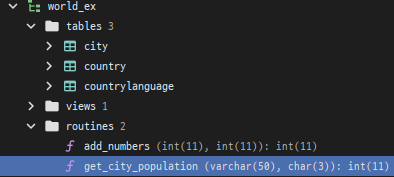
- 호출 예시
SELECT get_city_population('New York', 'USA') -- 예시 결과: 8008278
AS NewYorkPopulation
FROM dual;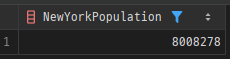
3. 국가별 인구 밀도를 계산하는 함수
country테이블에서국가 코드를 입력받아 해당 국가의인구 밀도를 계산하여 반환하는 함수를 정의해보겠습니다.- 인구 밀도는 인구(
Population)를 면적(SurfaceArea)으로 나눈 값으로 계산할 수 있습니다.
- 인구 밀도는 인구(
CREATE FUNCTION calculate_population_density(country_code CHAR(3))
RETURNS DECIMAL(10,2)
BEGIN
DECLARE population INT;
DECLARE area DECIMAL(10,2);
DECLARE density DECIMAL(10,2);
SELECT cout.Population, cout.SurfaceArea INTO population, area
FROM country AS cout
WHERE cout.Code = country_code;
SET density = population / area;
RETURN density;
END;
- 호출 예시
SELECT calculate_population_density('USA')
AS USAPopulationDensity
FROM dual;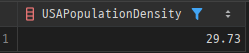
2.3 사용자 정의 함수 관리
- 함수 삭제: 함수를 더 이상 사용하지 않을 경우
DROP FUNCTION명령어를 사용하여 삭제할 수 있습니다.
DROP FUNCTION IF EXISTS function_name;2.4 사용자 정의 함수의 장점과 주의사항
장점
- 복잡한 계산이나 반복되는 로직을 함수로 정의하여 쿼리의 재사용성과 유지보수성을 높일 수 있습니다.
- 쿼리의 가독성이 향상되어 데이터베이스 로직을 쉽게 관리할 수 있습니다.
주의사항
함수는 일반적으로 하나의 값을 반환하므로, 여러 결과를 반환해야 하는 경우는프로시저가 더 적합할 수 있습니다.- 데이터베이스마다 사용자 정의 함수에 대한 지원과 문법이 다를 수 있어, 특정 DBMS 환경에 맞춰 작성해야 합니다. (본 포스팅에선
MariaDB/MySQL로 실습을 진행했습니다.)
3. PROCEDURE (프로시저)
PROCEDURE(프로시저)는 SQL에서 반복적이고 복잡한 작업을 하나의 단위로 묶어 처리할 수 있는 저장된 프로그램입니다.
- 복잡한 로직을 미리 정의하여 여러 번 재사용할 수 있도록 하며, 특정 작업을 자동화하고, 동일한 작업을 반복적으로 수행할 때 매우 유용합니다.
프로시저는 주로 데이터 조작(DML), 제어문(IF, LOOP, WHILE) 등을 포함하여 복잡한 연산을 처리하는 데 사용됩니다.
3.1 프로시저의 주요 특징
- 입력 매개변수와 출력 매개변수를 지원하여 다양한 입력 값을 받아 복잡한 연산을 수행하고, 결과를 반환할 수 있습니다.
프로시저내부에서 다양한 SQL 구문(DML, 제어 구문 등)을 사용하여트랜잭션을 관리하거나, 조건문과 반복문을 활용할 수 있습니다.- 데이터베이스 내에 저장되어 있어 서버 측에서 실행되므로, 클라이언트와 서버 간의 데이터 전송을 최소화할 수 있습니다.
- 일반적으로 복잡한 비즈니스 로직을 수행하거나 데이터 일괄 처리 작업에 많이 사용됩니다.
3.2 프로시저의 생성 및 삭제
CREATE PROCEDURE구문을 사용하여프로시저를 정의하고, 필요에 따라DROP PROCEDURE로 삭제할 수 있습니다.
기본 문법
CREATE PROCEDURE 프로시저이름(매개변수1 [IN|OUT|INOUT] 데이터형, 매개변수2 [IN|OUT|INOUT] 데이터형, ...)
BEGIN
-- 프로시저 로직
SQL 구문들;
END;IN: 입력 매개변수.- 호출 시 값을 전달받고, 프로시저 내에서만 사용됩니다.
OUT: 출력 매개변수.- 프로시저 실행 후 호출자에게 결과를 반환합니다.
INOUT: 입력과 출력을 모두 지원하는 매개변수.- 프로시저 호출 시 값을 전달받고, 수정된 값을 반환합니다.
프로시저 삭제 문법
DROP PROCEDURE 프로시저이름;3.3 프로시저 예제
예제 1: 간단한 데이터 조회 프로시저
- 기본 인구 조회 프로시저
country테이블에서 특정 대륙의 총 인구 수를 조회하는 프로시저를 만들어 보겠습니다.
CREATE PROCEDURE get_population_by_continent(
IN continent_name VARCHAR(50),
OUT total_population BIGINT)
BEGIN
SELECT SUM(cout.Population) INTO total_population
FROM country AS cout
WHERE cout.Continent = continent_name;
END;IN매개변수continent_name을 통해 대륙명을 받아country테이블에서 해당 대륙의 총 인구를 조회합니다.OUT매개변수total_population에 조회 결과를 반환합니다.
- 프로시저 호출 예시
CALL get_population_by_continent('Asia', @total_population);
SELECT @total_population AS AsiaPopulation
FROM dual;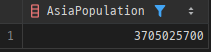
MySQL/MariaDB에서는 OUT 및 INOUT 매개변수를 사용할 때, 반드시 변수로 지정된 값을 전달해야 합니다. (@로 정의된 변수입니다)
예제 2: INOUT 매개변수를 활용한 프로시저
- 계산된 인구 밀도 반환 프로시저
- 특정 국가의 인구 밀도를 계산하고, 결과를 INOUT 매개변수로 반환합니다.
CREATE PROCEDURE calculate_population_density(
INOUT country_code CHAR(3),
OUT density DECIMAL(10, 2))
BEGIN
DECLARE population INT;
DECLARE area DECIMAL(10, 2);
SELECT cout.Population, cout.SurfaceArea INTO population, area
FROM country AS cout
WHERE cout.Code = country_code;
SET density = population / area;
END;- 프로시저 호출 예시
-- 프로시저 호출 전에 변수를 선언합니다.
SET @country_code = 'USA';
SET @density = NULL; -- OUT 매개변수를 저장할 변수를 선언합니다.
-- 프로시저 호출 시 변수를 사용합니다.
CALL calculate_population_density(@country_code, @density);
-- 결과를 조회합니다.
SELECT @density AS USAPopulationDensity;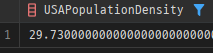
MySQL/MariaDB에서는 OUT 및 INOUT 매개변수를 사용할 때, 반드시 변수로 지정된 값을 전달해야 합니다. (@로 정의된 변수입니다)
3.4 프로시저의 장점과 단점
장점
- 반복 작업의 자동화
- 동일한 작업을 여러 번 수행할 때 유용하며, 코드 중복을 줄일 수 있습니다.
- 복잡한 로직 처리
조건문,반복문등 복잡한 비즈니스 로직을프로시저내에 포함할 수 있습니다.
- 서버 부하 감소
클라이언트-서버간의 데이터 전송이 줄어들며, 서버 내에서 작업이 처리되므로 네트워크 부하를 줄일 수 있습니다.
- 보안성
- 사용자에게 직접 테이블에 접근하지 않도록 하고,
프로시저를 통해 간접적으로 데이터를 제어할 수 있습니다.
- 사용자에게 직접 테이블에 접근하지 않도록 하고,
단점
- 디버깅 어려움
프로시저는 디버깅이 어렵고, 오류를 발견하기 쉽지 않습니다.
- 유지보수 문제
프로시저의 복잡성이 증가하면 유지보수가 어려워질 수 있습니다.
- 벤더 종속성
특정 DBMS에서만 동작하는 경우가 있어, 다른 DBMS로 이식하기 어려울 수 있습니다.
4. TRIGGER (트리거)
트리거(Trigger)는 특정한 이벤트가 발생할 때 자동으로 실행되는 SQL 코드 블록입니다.
- 데이터베이스에서 데이터 변경 작업(INSERT, UPDATE, DELETE)이 일어날 때 자동으로 실행되며, 무결성 유지, 데이터 감사, 자동 계산 등의 작업을 처리하는 데 유용합니다.
4.1 트리거의 특징과 용도
- 자동 실행
- 트리거는 미리 정의된 작업이 수행될 때마다 자동으로 실행됩니다.
- 무결성 유지
- 데이터가 일관성 있게 유지되도록 보장합니다.
- 예를 들어, 특정 필드 값의 유효성을 검사하거나 자동으로 값을 수정할 수 있습니다.
- 데이터 심사(Audit, 감사)
- 데이터 변경을 기록해 두어 변경 이력을 관리할 수 있습니다.
- 계산 및 갱신
- 다른 테이블의 데이터를 자동으로 갱신하거나 연산할 수 있습니다.
트리거의 활용 사례
- 감사 로그: 데이터가 변경될 때마다 기록을 남겨 데이터 변경 이력을 관리.
- 데이터 무결성 유지: 조건에 따라 다른 테이블의 데이터 자동 갱신.
- 자동 계산: 데이터 입력 시 계산 결과를 다른 테이블에 기록하거나 필드 자동 계산.
4.2 트리거 생성 구문
CREATE TRIGGER 트리거_이름
{BEFORE | AFTER} {INSERT | UPDATE | DELETE}
ON 테이블_이름
FOR EACH ROW
BEGIN
-- 트리거에서 실행할 SQL 코드
END;트리거 생성 구문 설명
CREATE TRIGGER: 트리거를 생성합니다.{BEFORE | AFTER}: 트리거가 실행될 시점을 지정합니다.BEFORE는 데이터 변경 전,AFTER는 데이터 변경 후에 트리거가 실행됩니다.
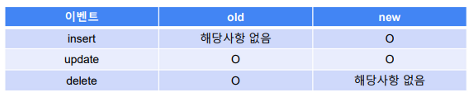
{INSERT | UPDATE | DELETE}: 트리거를 실행할 작업 유형을 지정합니다.
FOR EACH ROW: 각 행에 대해 트리거가 실행되도록 지정합니다.BEGIN ... END: 트리거에서 실행할 SQL 문을 작성하는 구문입니다.
4.3 트리거 예제
트리거에서는 기존 예제와는 다른 새로운 테이블을 생성하여 진행해보도록 하겠습니다.employees테이블 : 직원 관리 테이블audit_log테이블 :employees테이블의 변경 내역을 기록하는 테이블
# employees 테이블 생성
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
name VARCHAR(50),
position VARCHAR(50),
salary DECIMAL(10, 2)
);
# audit_log 테이블 생성
CREATE TABLE audit_log (
log_id INT PRIMARY KEY AUTO_INCREMENT,
emp_id INT,
action VARCHAR(50),
action_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);예제 1: INSERT 트리거 - 새로운 직원 추가 시 감사 로그 작성
employees 테이블에서 새로운 직원이 추가(INSERT)될 때 audit_log라는 감사 테이블에 변경 내역을 기록하는 AFTER INSERT 트리거를 만드는 예제입니다.
AFTER INSERT트리거 생성
CREATE TRIGGER after_employee_insert
AFTER INSERT ON employees
FOR EACH ROW
BEGIN
INSERT INTO audit_log (emp_id, action)
VALUES (NEW.emp_id, 'INSERT');
END;employees테이블에 새로운 직원이 추가될 때마다audit_log테이블에 변경 내역이 기록됩니다.- 여기서
NEW키워드는 트리거에 의해 생성되는 테이블 객체를 의미합니다. (INSERT에서는NEW만 존재합니다)
- 여기서
- 트리거 실행 예시
INSERT INTO employees (emp_id, name, position, salary)
VALUES (1, 'Alice', 'Manager', 75000.00);
SELECT * FROM audit_log;
예제 2: UPDATE 트리거 - 급여 업데이트 시 이전 급여 기록
이번 트리거는 employees 테이블에서 급여가 업데이트될 때 이전 급여(OLD)를 salary_changes 테이블에 기록합니다.
salary_changes테이블 생성
CREATE TABLE salary_changes (
change_id INT PRIMARY KEY AUTO_INCREMENT,
emp_id INT,
old_salary DECIMAL(10, 2),
new_salary DECIMAL(10, 2),
change_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);BEFORE UPDATE트리거 생성
CREATE TRIGGER before_salary_update
BEFORE UPDATE ON employees
FOR EACH ROW
BEGIN
IF OLD.salary <> NEW.salary THEN
INSERT INTO salary_changes (emp_id, old_salary, new_salary)
VALUES (OLD.emp_id, OLD.salary, NEW.salary);
END IF;
END;employees테이블에서 급여가 변경되면salary_changes테이블에 이전 급여와 새로운 급여가 기록됩니다.- 여기서
<>은 부정(NOT)의 의미가 있는 연산자이고,!=를 사용해도 됩니다. - 여기서
OLD키워드는 트리거가 실행되기 직전의 테이블 객체를 의미합니다. - 여기서
NEW키워드는 트리거에 의해 수정되는 테이블 객체를 의미합니다.
- 여기서
- 트리거 실행 예시
UPDATE employees
SET salary = 80000.00
WHERE emp_id = 1;
SELECT * FROM salary_changes;
4.4 트리거 관리
- 트리거 삭제: 트리거를 삭제하려면
DROP TRIGGER문을 사용합니다.DROP TRIGGER IF EXISTS after_employee_insert; - 트리거 확인: 데이터베이스의
SHOW TRIGGERS구문으로 트리거 정보를 조회할 수 있습니다.SHOW TRIGGERS FROM testdb3 WHERE `Table` = 'employees';- 여기서
FROM에는 DB 이름,WHERE에는 Table 이름이 들어가면 됩니다.
- 여기서

4.5 트리거 사용시 주의사항
- 무한 루프 방지
- 트리거 내에서 원본 테이블에 영향을 주는 쿼리를 실행하면 무한 루프에 빠질 수 있으므로 주의해야 합니다.
- 트리거의 성능 영향
- 트리거는 데이터 변경 시마다 실행되므로, 너무 많은 연산을 포함하면 성능에 영향을 줄 수 있습니다.
- 테이블 간 의존성 주의
- 트리거가 다른 테이블에 의존하는 경우 트리거와 테이블의 유지보수에 신경 써야 합니다.
트리거를 적절히 사용하면 데이터베이스의 일관성과 무결성을 강화할 수 있지만, 과도하게 사용하면 성능 저하를 초래할 수 있으므로 필요한 경우에만 사용하는 것이 좋습니다.
마무리
이번 포스팅에서는 SQL 로직 구현의 기본 요소인 CASE문, 사용자 정의 함수(FUNCTION), 프로시저(PROCEDURE), 트리거(TRIGGER)에 대해 다루었습니다.
- 이러한 요소들은 데이터베이스에서 단순한 데이터 조회와 저장을 넘어, 복잡한 비즈니스 로직을 데이터베이스 레벨에서 처리할 수 있도록 도와줍니다.
- 특히 데이터의 무결성을 유지하고, 자동화된 처리를 통해 애플리케이션의 성능과 일관성을 높이는 데 중요한 역할을 합니다.
요약
- CASE문을 통해
조건에 따라 다른 값을 반환하고, 데이터조회 시 유연한 조건을 적용할 수 있습니다. - 사용자 정의 함수(UDF)를 활용해
반복적인 계산이나특정 데이터를 동적으로 반환하는 로직을 재사용할 수 있습니다. - 프로시저(Procedure)는 복잡한 데이터 조작과 연산을
하나의 단위로 묶어 반복적인 작업을 자동화할 수 있는 방법을 제공합니다. - 트리거(Trigger)는
특정 이벤트가 발생할 때 자동으로 실행되도록 설정하여 데이터 변경 시자동으로 추가 작업을 수행하고, 데이터 무결성을 강화할 수 있습니다만,과도하게 사용하면 성능 저하를 초래할 수 있으므로필요한 경우에만 사용하는 것이 좋습니다.
다음 포스팅부터는 JDBC(Java Database Connectivity)를 다루면서 Java 애플리케이션과 데이터베이스를 연동하는 방법을 다룰 예정입니다.
- 이를 통해 SQL 로직을 Java 코드 내에서 실행하고, 데이터베이스와 상호작용하여 애플리케이션을 더욱 강력하게 만드는 방법을 알아보도록 하겠습니다.
