
본 시리즈는 프로그래밍 알고리즘의 개념을 정리하고 실습을 진행해보는 시리즈입니다.
- 실습은 다음과 같은 개발환경 및 버전에서 진행하였습니다.
- IDE : IntelliJ IDEA (Ultimate Edition)
- Java : JDK 21 (corretto-21)
- Python : 3.9 (conda env)
[알고리즘] 정렬(Sorting) - Tree Sort & Heap Sort
- 정렬 알고리즘의 전반적인 개요와 분류는 다음 포스팅에서 확인하실 수 있습니다.
1. 트리 기반 정렬 (Tree Based Sorting)
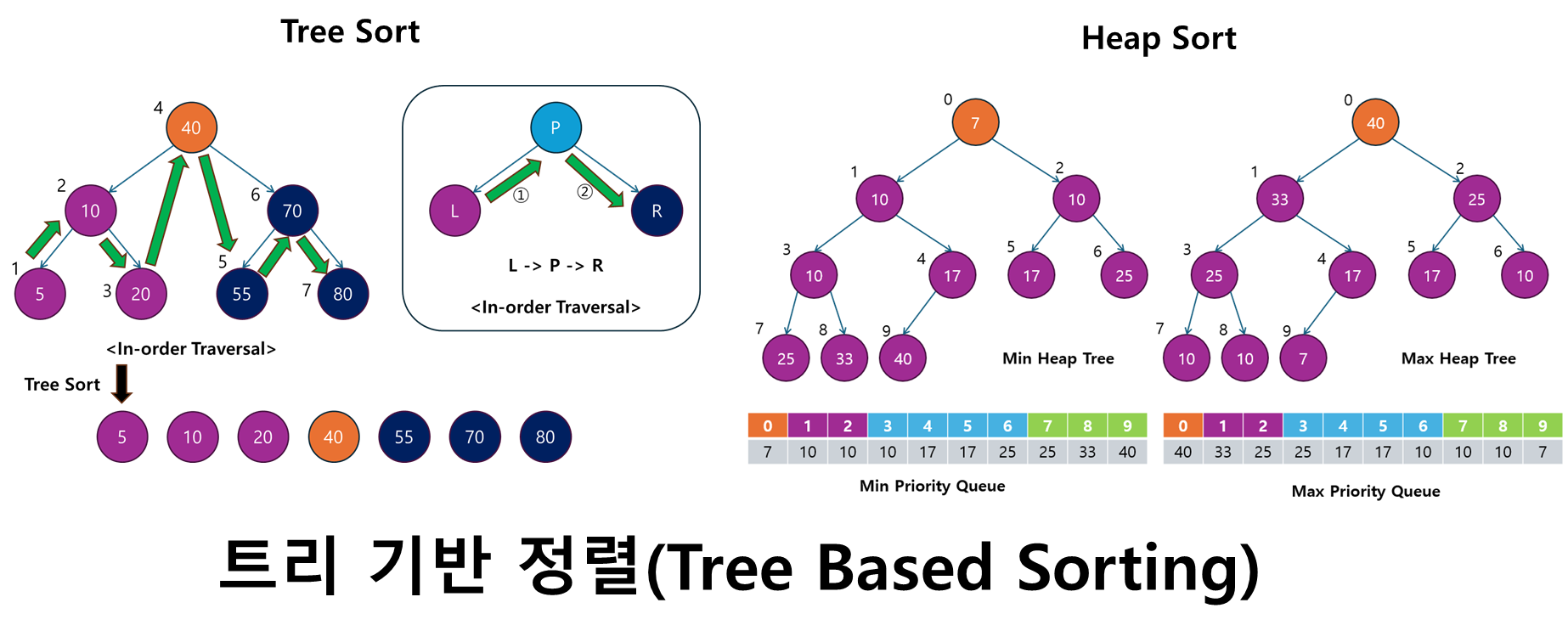
트리 기반 정렬은 트리 자료구조를 활용하여 데이터를 정렬하는 알고리즘입니다.
- 이 방식은 이진 탐색 트리(Binary Search Tree, BST)나 최대/최소 힙(Heap) 같은 트리 구조를 이용하여 데이터를 효율적으로 정렬할 수 있게 해줍니다.
트리 기반 정렬의 대표적인 예로는 트리 정렬(Tree Sort)과 힙 정렬(Heap Sort)이 있으며, 이들은 대규모 데이터셋에서의 효율적인 정렬을 가능하게 합니다.
- 특히, 이진 탐색 트리와 힙 구조를 기반으로 한 알고리즘들은 평균적으로 의 시간 복잡도를 가지며, 이는 비교 기반 정렬의 이론적인 최적 시간 복잡도입니다.
트리 기반 정렬의 주요 특징은 다음과 같습니다:
- 이진 탐색 트리나 힙 같은 트리 구조는 데이터의 삽입과 삭제를 빠르게 처리할 수 있어 정렬에 적합합니다.
- 힙 정렬은 비교 기반 정렬 알고리즘 중 추가 메모리 사용이 거의 없는 방식으로, 대규모 데이터셋에서 우수한 성능을 발휘합니다.
- 트리 정렬은 이진 탐색 트리의 중위 순회(in-order traversal)를 활용하여 자연스럽게 정렬된 결과를 도출합니다.
트리 기반 정렬 알고리즘은 트리의 균형이나 힙화(heapify) 과정이 중요한 역할을 하며, 이러한 과정이 제대로 수행되지 않으면 최악의 성능을 보일 수 있습니다.
이제 각 트리 기반 정렬 알고리즘을 자세히 살펴보겠습니다.
2. 트리 정렬 (Tree Sort)
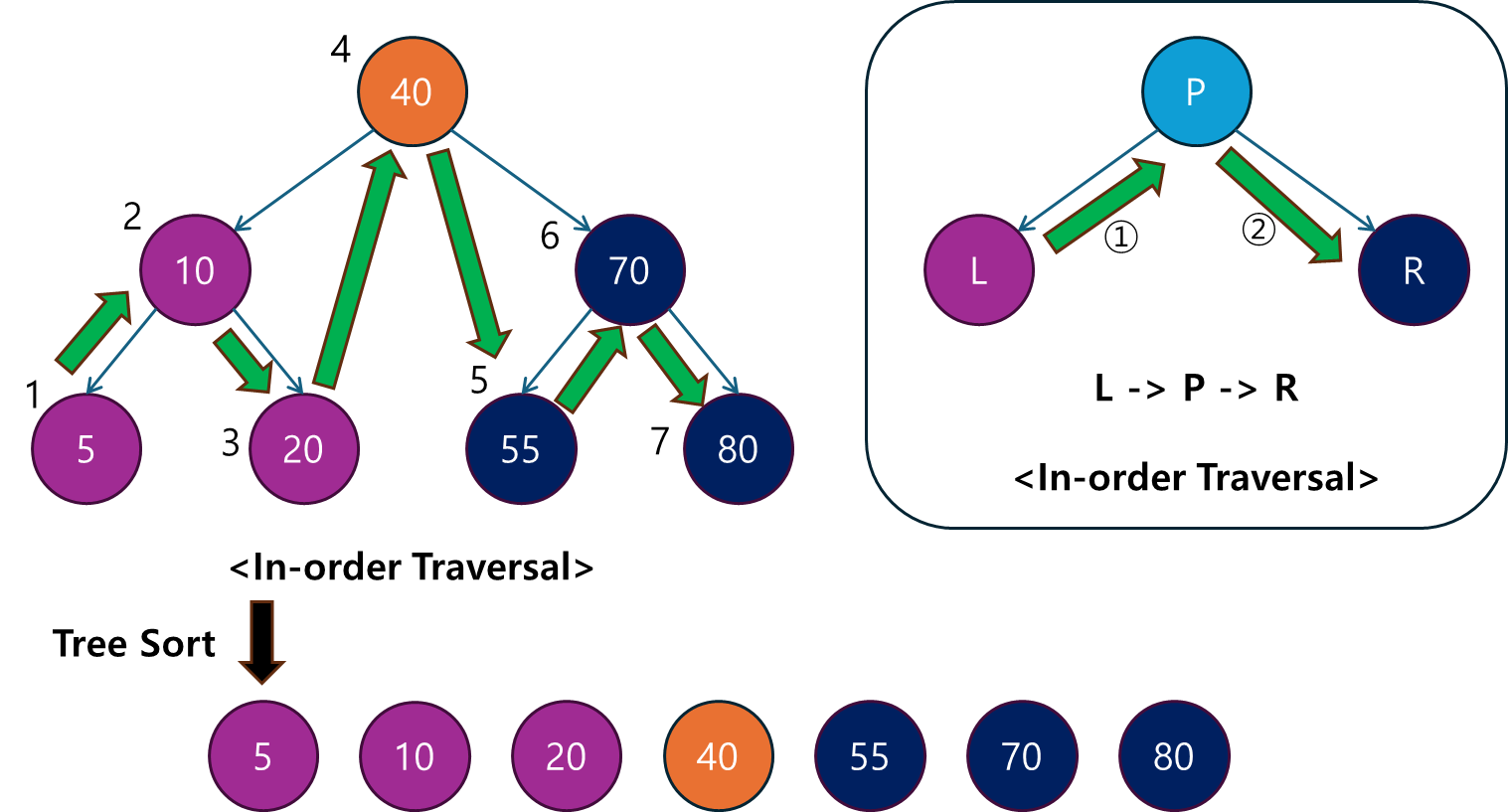
2.1 Tree Sort란?
트리 정렬(Tree Sort)은 이진 탐색 트리(Binary Search Tree, BST)를 기반으로 데이터를 정렬하는 알고리즘입니다.
- 먼저, 배열의 데이터를 이진 탐색 트리에 삽입한 후, 중위 순회(In-order Traversal)를 통해 트리에서 요소들을 오름차순으로 출력합니다.
- 트리 정렬은 트리 구조가 자동으로 데이터를 정렬된 상태로 유지하기 때문에, 삽입만 완료되면 중위 순회를 통해 자연스럽게 정렬된 데이터를 얻을 수 있습니다.
시간 복잡도:
- 최악의 경우 (트리가 한쪽으로 치우친 경우)
- 평균적으로 (균형 트리의 경우)
특징:
- 안정성이 보장되지 않음 (같은 값의 요소들 간 순서가 유지되지 않음)
- 트리의 균형이 잘 맞을 경우 성능이 뛰어나지만, 트리가 불균형해질 경우 성능이 급격히 저하될 수 있습니다. (이 문제는 AVL 트리나 레드-블랙 트리 같은 균형 이진 트리를 사용하면 해결됩니다.)
2.2 Tree Sort 동작 원리
Tree Sort의 동작은 크게 두 가지 단계로 나눌 수 있습니다:
- 데이터 삽입: 주어진 배열의 데이터를 하나씩 이진 탐색 트리에 삽입합니다.
- 트리의 왼쪽 자식 노드에는 작은 값이, 오른쪽 자식 노드에는 큰 값이 위치하도록 트리를 구성합니다.
- 중위 순회(In-order Traversal): 이진 탐색 트리에서 중위 순회를 수행하여 요소들을 오름차순으로 출력합니다.
- 중위 순회는 왼쪽 -> 루트 -> 오른쪽 순으로 트리를 순회하기 때문에, 트리에 저장된 데이터를 오름차순으로 정렬할 수 있습니다.
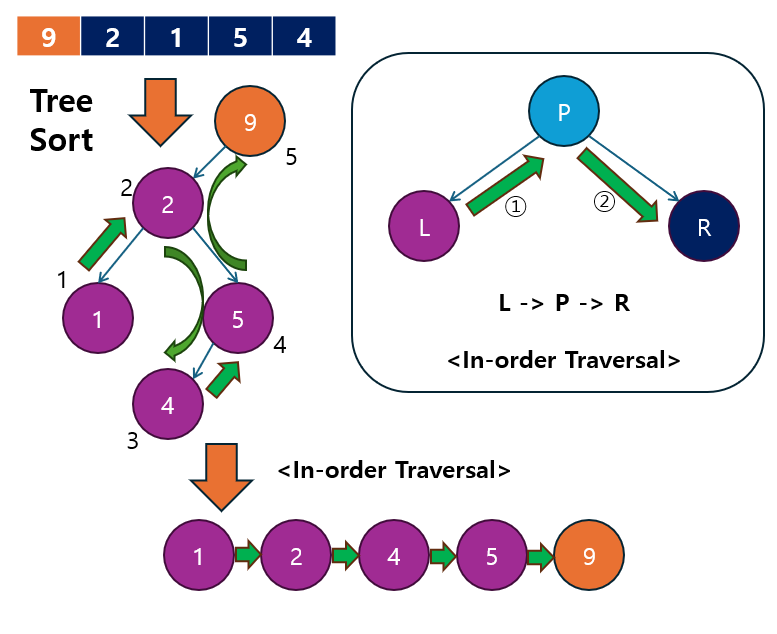
동작 예시: 주어진 배열 [9, 2, 1, 5, 4]를 Tree Sort로 정렬하는 과정:
-
이진 탐색 트리 구성:
9삽입 (루트)2삽입 (9의 왼쪽 자식)1삽입 (2의 왼쪽 자식)5삽입 (2의 오른쪽 자식)4삽입 (5의 왼쪽 자식)
-
중위 순회:
왼쪽 -> 루트 -> 오른쪽순으로 순회하면[1, 2, 4, 5, 9]이 출력됩니다.
2.3 Tree Sort 구현(Java)
import java.util.ArrayList;
import java.util.List;
// 이진 탐색 트리 노드 클래스
class Node {
int value;
Node left, right;
public Node(int value) {
this.value = value;
left = right = null;
}
}
public class TreeSort {
// 트리에 데이터를 삽입하는 함수
public static Node insert(Node root, int value) {
if (root == null) {
return new Node(value); // 새로운 노드 생성
}
if (value < root.value) {
root.left = insert(root.left, value); // 왼쪽에 삽입
} else {
root.right = insert(root.right, value); // 오른쪽에 삽입
}
return root;
}
// 중위 순회를 통해 배열에 값을 저장하는 함수
public static void inOrderTraversal(Node root, List<Integer> sortedList) {
if (root != null) {
inOrderTraversal(root.left, sortedList); // 왼쪽 자식 방문
sortedList.add(root.value); // 현재 노드 값 추가
inOrderTraversal(root.right, sortedList); // 오른쪽 자식 방문
}
}
public static int[] treeSort(int[] arr) {
Node root = null;
// 트리에 모든 요소 삽입
for (int value : arr) {
root = insert(root, value);
}
// 중위 순회로 정렬된 리스트 가져오기
List<Integer> sortedList = new ArrayList<>();
inOrderTraversal(root, sortedList);
// 리스트를 배열로 변환
int[] sortedArr = new int[sortedList.size()];
for (int i = 0; i < sortedArr.length; i++) {
sortedArr[i] = sortedList.get(i);
}
return sortedArr;
}
public static void main(String[] args) {
int[] arr = {9, 2, 1, 5, 4};
int[] sortedArr = treeSort(arr);
System.out.println("Sorted array: " + java.util.Arrays.toString(sortedArr));
}
}Java 구현 설명:
insert함수는 배열의 요소를 이진 탐색 트리에 삽입하고,inOrderTraversal함수는 중위 순회를 통해 정렬된 리스트를 가져옵니다.- 트리 정렬은 배열을 트리 구조에 삽입한 후 중위 순회를 통해 정렬된 데이터를 얻는 방식입니다.
출력 예시:
Sorted array: [1, 2, 4, 5, 9]2.4 Tree Sort 구현(Python)
# 이진 탐색 트리 노드 클래스
class Node:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
# 트리에 값을 삽입하는 함수
def insert(root, value):
if root is None:
return Node(value)
if value < root.value:
root.left = insert(root.left, value)
else:
root.right = insert(root.right, value)
return root
# 중위 순회로 정렬된 리스트를 얻는 함수
def in_order_traversal(root, sorted_list):
if root is not None:
in_order_traversal(root.left, sorted_list)
sorted_list.append(root.value)
in_order_traversal(root.right, sorted_list)
# Tree Sort 함수
def tree_sort(arr):
root = None
# 트리에 모든 요소 삽입
for value in arr:
root = insert(root, value)
# 중위 순회를 통해 정렬된 리스트 가져오기
sorted_list = []
in_order_traversal(root, sorted_list)
return sorted_list
# 예시
arr = [9, 2, 1, 5, 4]
sorted_arr = tree_sort(arr)
print("Sorted array:", sorted_arr)
Python 구현 설명:
insert함수는 이진 탐색 트리에 데이터를 삽입하고,in_order_traversal함수는 중위 순회로 정렬된 리스트를 얻습니다.- 트리 정렬은 Python에서도 이진 탐색 트리와 중위 순회를 활용하여 정렬을 수행합니다.
출력 예시:
Sorted array: [1, 2, 4, 5, 9]3. 힙 정렬 (Heap Sort)
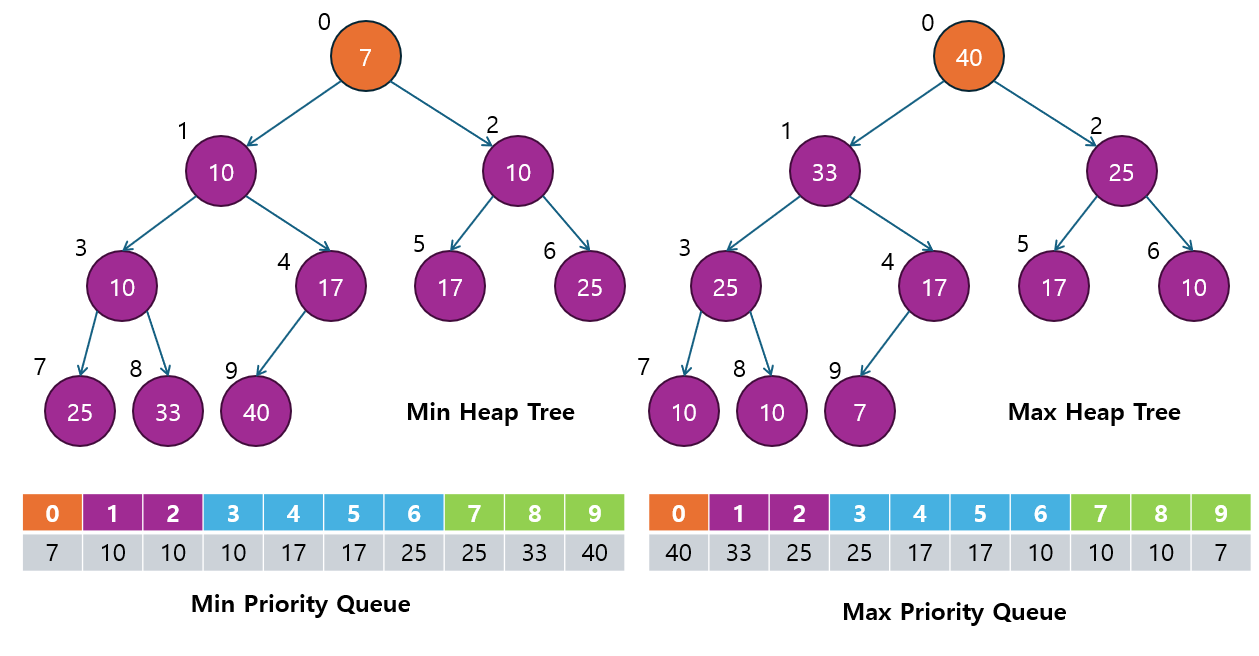
3.1 Heap Sort란?
힙 정렬 (Heap Sort)은 힙(Heap) 자료구조를 이용하여 데이터를 정렬하는 비교 기반 정렬 알고리즘입니다.
- 힙은 완전 이진 트리 형태로, 최대 힙(Max Heap)과 최소 힙(Min Heap)을 사용하여 데이터의 최댓값이나 최솟값을 빠르게 찾을 수 있습니다.
- 힙 정렬은 최대 힙을 이용해 오름차순으로 정렬하거나, 최소 힙을 이용해 내림차순으로 데이터를 정렬할 수 있습니다.
Heap Sort 동작 원리는 힙화(Heapify)라는 과정으로 배열을 힙 구조로 만든 후, 힙의 루트에 있는 최댓값(또는 최솟값)을 배열의 맨 끝으로 이동시키고 다시 힙 구조를 재정렬하는 과정을 반복하여 정렬합니다.
시간 복잡도:
- 최악, 최선, 평균 모두
특징:
- 불안정 정렬 (중복 값의 순서가 유지되지 않음)
- 추가적인 메모리 할당 없이, 제자리 정렬을 지원합니다.
- 대규모 데이터에서도 효율적이며, 특히 추가 메모리 사용이 적은 정렬 알고리즘입니다.
3.2 Heap Sort 동작 원리
Heap Sort는 다음과 같은 단계를 거칩니다 (오름차순 기준):
- 배열을 힙으로 변환 (힙화 과정): 주어진 배열을 최대 힙(Max Heap)으로 변환합니다. 부모 노드가 자식 노드들보다 항상 크도록 배열을 재구성합니다.
- 힙에서 가장 큰 요소 추출: 힙의 루트(가장 큰 값)를 배열의 마지막 요소와 교환한 뒤, 배열에서 마지막 요소를 제외한 나머지 부분을 다시 힙화합니다.
- 이 과정을 배열에 남은 요소가 없을 때까지 반복하면 배열이 오름차순으로 정렬됩니다.
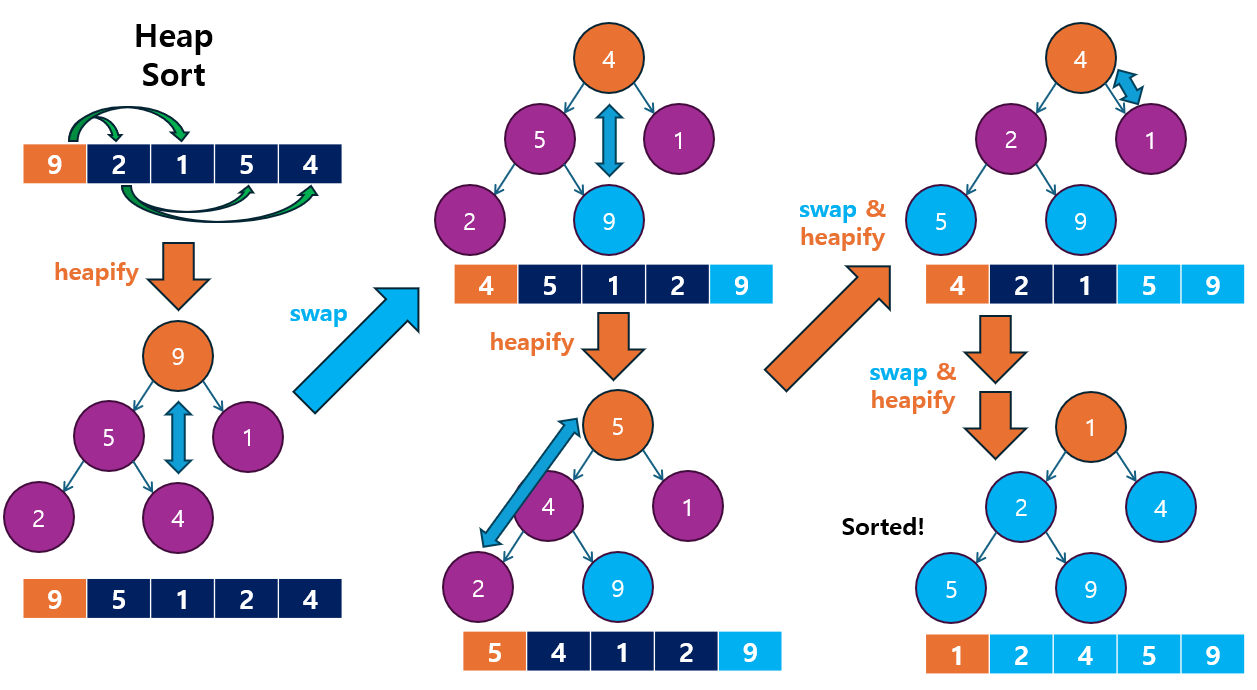
동작 예시: 주어진 배열 [9, 2, 1, 5, 4]을 Heap Sort로 정렬하는 과정:
- Heapify 과정:
- 배열
[9, 2, 1, 5, 4]을 최대 힙으로 변환합니다. - Heapify 결과:
[9, 5, 1, 2, 4]
- 배열
- 최대값 추출 및 교환:
- 루트의 값
9와 배열의 마지막 값4를 교환합니다. - 배열은 [4, 5, 1, 2, 9]이 되고,
9는 정렬된 위치로 확정됩니다. - 나머지 배열
[4, 5, 1, 2]에 대해 힙화를 다시 수행합니다. - Heapify 후 배열:
[5, 4, 1, 2]
- 루트의 값
- 최대값 추출 반복:
- 위의 과정을 계속해서 반복하여 최종적으로 오름차순으로 정렬된 배열을 얻습니다.
- 최종 결과: [1, 2, 4, 5, 9]
3.3 Heap Sort 구현 (Java)
import java.util.Arrays;
public class HeapSort {
public static void heapSort(int[] arr) {
int n = arr.length;
// 배열을 힙으로 변환
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
// 힙에서 요소를 하나씩 추출하여 정렬
for (int i = n - 1; i > 0; i--) {
// 루트와 마지막 요소 교환
int temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
// 힙의 나머지 부분을 다시 힙화
heapify(arr, i, 0);
}
}
// 힙을 구성하는 함수
private static void heapify(int[] arr, int n, int i) {
int largest = i; // 루트를 가장 큰 값으로 가정
int left = 2 * i + 1; // 왼쪽 자식
int right = 2 * i + 2; // 오른쪽 자식
// 왼쪽 자식이 루트보다 크면 왼쪽 자식을 가장 큰 값으로
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
// 오른쪽 자식이 현재 가장 큰 값보다 크면 오른쪽 자식을 가장 큰 값으로
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
// 루트가 가장 큰 값이 아니면 교환
if (largest != i) {
int swap = arr[i];
arr[i] = arr[largest];
arr[largest] = swap;
// 교환한 부분을 재귀적으로 힙화
heapify(arr, n, largest);
}
}
public static void main(String[] args) {
int[] arr = {9, 2, 1, 5, 4};
heapSort(arr);
System.out.println("Sorted array: " + Arrays.toString(arr));
}
}
Java 구현 설명:
heapify함수는 힙화 과정을 구현한 것으로, 배열의 각 노드를 재배열하여 최대 힙 구조를 만듭니다.- 배열을 힙으로 변환한 후, 루트 요소를 추출하여 배열의 마지막 위치에 놓고, 나머지 배열로 다시 힙화를 반복하는 방식입니다.
출력 예시:
Sorted array: [1, 2, 4, 5, 9]
3.4 Heap Sort 구현 (Python)
# 힙화 과정
def heapify(arr, n, i):
largest = i # 루트
left = 2 * i + 1 # 왼쪽 자식
right = 2 * i + 2 # 오른쪽 자식
# 왼쪽 자식이 루트보다 크면 왼쪽 자식을 가장 큰 값으로 설정
if left < n and arr[left] > arr[largest]:
largest = left
# 오른쪽 자식이 현재 가장 큰 값보다 크면 오른쪽 자식을 가장 큰 값으로 설정
if right < n and arr[right] > arr[largest]:
largest = right
# 가장 큰 값이 루트가 아니라면 교환
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i] # 교환
# 교환된 하위 트리를 재귀적으로 힙화
heapify(arr, n, largest)
# 힙 정렬 함수
def heap_sort(arr):
n = len(arr)
# 배열을 힙으로 변환
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
# 힙에서 요소를 하나씩 추출하여 정렬
for i in range(n - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i] # 루트와 마지막 요소 교환
heapify(arr, i, 0) # 힙의 나머지 부분을 다시 힙화
# 예시
arr = [9, 2, 1, 5, 4]
heap_sort(arr)
print("Sorted array:", arr)
Python 구현 설명:
heapify함수는 배열을 최대 힙으로 변환하며, 루트 노드를 자식 노드들과 비교하여 힙 구조를 만듭니다.- 배열을 힙으로 변환한 후, 루트와 배열의 마지막 요소를 교환하여 다시 정렬합니다.
출력 예시:
Sorted array: [1, 2, 4, 5, 9]4. Tree 기반 정렬 알고리즘 복잡도
Tree 기반 정렬 알고리즘은 주로 트리 구조를 이용하여 데이터를 정렬하는 방식으로, 시간 복잡도와 공간 복잡도가 트리의 구조에 따라 달라집니다.
4.1 Tree Sort 복잡도
Tree Sort는 이진 탐색 트리(Binary Search Tree)를 이용하여 데이터를 정렬합니다.
- 각 요소를 트리에 삽입하고, 트리를 중위 순회(In-order Traversal)하여 정렬된 배열을 얻습니다.
시간 복잡도:
- 평균:
- 트리가 균형 잡힌 경우(예: AVL 트리나 레드-블랙 트리) 삽입, 삭제, 검색 모두 의 시간이 걸립니다.
- 최악:
- 트리가 한쪽으로 치우친 경우(불균형 트리)에는 삽입 시 한쪽으로만 쌓이게 되면서 선형 시간이 걸릴 수 있습니다.
공간 복잡도:
- : 트리의 각 노드가 메모리에 저장되기 때문에, 총 개의 노드에 대해 의 공간을 차지합니다.
특징:
- 안정성: Tree Sort는 안정 정렬이 아닙니다.
- 적용 범위: 정렬된 데이터나 거의 정렬된 데이터를 처리할 때는 오히려 비효율적일 수 있습니다.
4.2 Heap Sort 복잡도
Heap Sort는 완전 이진 트리 구조인 힙(Heap)을 이용하여 데이터를 정렬합니다.
- 최대 힙(Max Heap)이나 최소 힙(Min Heap)을 구성한 후, 최댓값(또는 최솟값)을 루트에서 반복적으로 추출하여 정렬합니다.
시간 복잡도:
- 최악, 평균, 최선 모두
- 모든 경우에 대해 삽입 및 삭제 연산이 트리의 높이에 따라 에 수행되며, 이를 번 반복하므로 전체 복잡도는 입니다.
공간 복잡도:
- : 추가적인 배열이나 자료구조를 사용하지 않고, 주어진 배열 내에서 정렬이 이루어지기 때문에 추가 메모리 공간이 필요하지 않습니다.
특징:
- 안정성: Heap Sort는 안정 정렬이 아닙니다. (동일한 값을 가진 요소들의 상대적인 순서가 유지되지 않습니다.)
- 적용 범위: 추가 메모리가 필요하지 않으므로 메모리 효율이 중요할 때 유용합니다.
4.3 비교 요약
| 정렬 알고리즘 | 평균 시간 복잡도 | 최악 시간 복잡도 | 공간 복잡도 | 안정성 | 특징 |
|---|---|---|---|---|---|
| Tree Sort | 불안정 | 트리가 불균형해지면 성능 저하 | |||
| Heap Sort | 불안정 | 추가 메모리 없이 정렬 가능 |
이 표에서 보듯이, Tree Sort와 Heap Sort는 둘 다 평균적으로 의 성능을 보여줍니다.
- Tree Sort는 트리의 균형 상태에 따라 최악의 경우 성능이 크게 저하될 수 있습니다.
- Heap Sort는 항상 의 성능을 유지하며 추가적인 메모리를 사용하지 않는다는 장점이 있습니다.
결론
- Tree Sort는 이진 탐색 트리를 기반으로 하여 균형 트리인 경우에는 매우 효율적이지만, 불균형 트리가 될 가능성이 있어 신중하게 선택해야 합니다.
- Heap Sort는 추가 메모리 사용이 제한된 환경에서 강력한 성능을 제공하며, 최악의 경우에도 성능을 보장합니다.
마무리
이번 포스팅에서는 트리 기반의 정렬 알고리즘, 즉 Tree Sort와 Heap Sort의 동작 원리와 구현, 그리고 각 알고리즘의 시간 복잡도와 특징을 자세히 살펴보았습니다.
-
이 두 알고리즘은 이진 탐색 트리와 힙이라는 트리 자료구조를 기반으로 하여, 특히 대규모 데이터를 다룰 때 효율적인 성능을 제공합니다.
-
Tree Sort는 이진 탐색 트리(BST)를 기반으로 데이터를 정렬하며, 트리가 균형을 유지하는 경우 매우 빠르게 동작할 수 있습니다. 하지만, 트리가 불균형해질 경우 성능이 크게 저하될 수 있어, 사용 시 주의가 필요합니다.
-
Heap Sort는 추가 메모리 없이 주어진 배열 내에서 정렬을 수행할 수 있는 알고리즘으로, 대규모 데이터에서 꾸준한 성능을 제공하며 메모리 효율성이 중요한 상황에서 유용합니다.
다음 포스팅에서는 분할 정복 기반 정렬 알고리즘인 퀵 정렬(Quick Sort)과 듀얼 피벗 퀵 정렬(Dual-Pivot Quick Sort)에 대해 다룰 예정입니다.
이들 알고리즘은 빠른 평균 시간 복잡도를 자랑하며, 특히 대규모 데이터에 적합한 방식으로 널리 사용되는 정렬 알고리즘입니다.
