
시계열 데이터 분석에 필요한 개념들을 정리하는 시리즈 - 1. 통계 기초 및 시계열 데이터 분석 개요 편
1. 데이터 분석 통계 기초
- 시계열 분석에 있어서 기반이 되는 통계학의 기본 개념들을 정리해봅니다.
1-1. 통계 분석의 범위
- 데이터를 통계적으로 분석하는 방법에는 크게 두가지가 있습니다.
- 기술통계 (Descriptive Statistics)
- 주어진 데이터의 분포를 파악하고 빈도, 평균, 표준편차와 같은 통계량을 통해서 데이터의 속성만을 설명하는 과정
- 중심경향값 (평균, 중앙값, 최빈값, 등...)
- 분포 (정규분포, 왜도, 등...)
- 분산도 (범위, 사분위편차, 분산, 표준편차, 첨도, 등...)
- 상관관계 (산포도, 공분산, 상관계수, 등...)
- 추론통계 (Inferential Statistics)
- 표본(sample)에서 얻은 자료로 모집단(population)의 특성을 추정하는 과정
- 표본을 복원추출하여 표본평균들의 분포를 통해 모집단을 추정하며, 이때 표본평균의 분포를 표집분포(sampling distribution)라 합니다.
- 기술통계 (Descriptive Statistics)
1-2. 통계적 가설 검정
- 가설(Hypothesis) : 어떤 사실을 잠정적인 진리로 놓고, 이를 지지 혹은 기각하기 위한 잠정적인 설명,가능성
- 귀무가설,영가설(Null hypothesis) : 진리인 내용, 연구에서 검정받는 사실
- 로 주로 표기하고, 등호()를 포함해야 합니다.
- 부등호( or )로 표기하면 '등가설'이라 부릅니다.
- 대립가설(Alternative hypothesis) : 영가설을 부정하기 위해 연구자가 주장하고자 하는 내용
- 혹은 으로 주로 표기하고, 등호를 포함하지 않아야합니다.
- 부등호( or )로 표기하면 '부등가설'이라 부릅니다.
- 귀무가설,영가설(Null hypothesis) : 진리인 내용, 연구에서 검정받는 사실
- 가설의 표현방법에 따라 다음과 같이 분류되기도 합니다.
- 서술적가설 : 언어에 의하여 표현한 가설
- 통계적가설 : 서술적 가설을 어떤 기호나 수에 의해 표현한 가설
- 통계적 가설을 표기할땐 모수치에 대한 표기를 해야합니다. ( μ, σ, ⋯ )
- 통계적 가설 검정 4단계
- 귀무가설() 및 대립가설(), 유의수준 설정
- 표집(sampling), 검정통계량, 기각역 설정
- 검정통계량 계산 및 영가설 기각여부 확인
- 통계적인 의사결정 실시
- 가설에 대한 오판단
- 1종오류 (Type I Error)
- 귀무가설이 참인 경우, 귀무가설을 기각하는 경우
- 로 표기하며, 유의수준(significant level)이라고도 부릅니다.
- 2종오류 (Type II Error)
- 귀무가설이 거짓인 경우, 귀무가설을 채택하는 경우
- 로 표기하며, 은 검정력(power)라고 부릅니다.
- 일반적으로 2종오류보다 1종오류를 극소화하는 방향으로 연구가 이루어지고, 유의수준은 0.05 혹은 0.01로 주로 설정합니다.
- 1종오류 (Type I Error)
- p-value (Probability-value)
- 귀무가설이 참인 경우, 계산한 통계량이 극단적인 값으로 관측되는 빈도에 대한 확률 값
- 영가설의 기각 여부를 결정하는 지표가 되므로, 가설검정에서 매우 중요한 개념입니다.
2. 예측모델과 시계열모델
2-1. 예측모델
- 를 따른다는 기본 가정으로 종속변수 를 예측하기 위한 모델
- 예측 모델은 종속변수 의 형태에 따라 두가지로 분류됩니다.
- 회귀모델 (Regression) : 예측하고자 하는 변수(y)가 연속적인 변수
- 선형회귀 : Linear Regression
- 비선형회귀 : Polynomial Regression, GLM, GAM, Spline 등...
- 분류모델 (Classification) : 예측하고자 하는 변수(y)가 이산적인 변수
- 선형기반분류 : Logistic Regression, Softmax, SVM 등...
- 트리기반분류 : Decision Tree, Bagging(Random Forest), Boosting 등...
- 회귀모델 (Regression) : 예측하고자 하는 변수(y)가 연속적인 변수
- 분류 모델의 경우 예측하고자 하는 변수(y)의 Class 수에 따라 다음과 같이 분류되기도 합니다.
- 이진분류 (Binary Classification) : 0 또는 1로 분류
- 다중분류 (Multi-Class Classification) : 셋 이상의 Class로 분류
2-2. 시계열 모델
- 기본가정 :
- 관측시간 에 대한 관측자료 의 관계로 표현됩니다.
- 수리통계학, 전파공학, 딥러닝 등의 방법론을 차용하여 분석이 이뤄집니다.
- 시계열 분석이 유용한 이유
- 데이터를 발생 순서에 따라 배열하여 새로운 패턴들을 파악할 수 있습니다.
- 동일 기간 동안의 다른 관찰 대상의 차이를 분석할 수 있습니다.
- 시기별 데이터의 차이를 정량화할 수 있습니다. (연도별, 분기별, 월별 등..)
- 구간별 데이터의 패턴을 파악할 수 있습니다. (상승-하락, 확장-수축 등..)
- 특정 사건의 반복적인 패턴과 발생 빈도를 확인할 수 있습니다.
- 시계열 분석시 주의해야할 점들
- 자기상관(autocorrelation)에서 자유로울 수 없어서 데이터간의 연관성을 잘 고려해야합니다.
- 자기상관 : 어떤 확률변수가 주어졌을 때, 서로 다른 두 시점에서의 관측치 사이에 나타나는 상관성
- 결측치가 많거나 불균형한 빈약한 자료를 다룰 때에 주의를 더 기울여야합니다.
- 예측(Prediction, Forcasting)을 실시하여 추정치를 얻는 경우, 수리적 통계모형에 의한 인과관계와 시간의 상관관계를 고려하여 미래 시점()의 추정치 얻어내야 합니다.
- 데이터의 전처리와 유의수준에 대한 측정에 있어서 다양한 요소들을 고려해서 진행해야합니다.
- 자기상관(autocorrelation)에서 자유로울 수 없어서 데이터간의 연관성을 잘 고려해야합니다.
- 시계열 데이터 분석의 대표적인 사례들
- 금융 (주식, 시장성, 자산배분 등..)
- 모션 센서 수집 데이터를 이용한 분석
- 모빌리티 패턴파악, 택배 물동량 추이파악 등..
3. 시계열 분석 기초
- 시계열을 분석하는 대표적인 프로그래밍 언어로
R과Python이 있습니다.R은 무료로 제공되는 오픈 소스 통계분석 프로그래밍 언어로써, 데이터 전처리, 통계분석, 데이터 시각화에 특화되어 있는 것이 특징입니다.- 통계분석이 주된 목적인 경우에 쉽고 간단하게 통계분석 및 시각화분석을 실시하고자 할 때 유용합니다.
- 다만, 머신러닝이나 딥러닝과 같은 고도화된 모델링을 하는 경우엔, 다소 복잡해지고 많은 기능들을 지원하지 못한다는 단점이 있습니다.
- R Gui, R Studio 등으로 쉽게 설치하여 이용해볼 수 있고, VSCode, Jupyter Notebook에서도 개발환경 세팅을 따로 하여 R을 이용해볼 순 있지만 세팅과정이 다소 복잡하기 때문에 그다지 추천드리지는 않습니다. (본 글에서는 VSCode의 Jupyter Notebook에서 R을 이용하여 분석을 진행했습니다.)
Python은 범용적인 개발을 위한 프로그래밍 언어로써, 데이터 전처리, 통계분석, 시각화, 머신러닝, 딥러닝, 데이터베이스 서버 구축, 모델 배포 및 어플리케이션 개발 등 거의 모든 분야에 대한 개발이 가능한 프로그래밍 언어입니다.- 통계분석 뿐만아니라 머신러닝이나 딥러닝과 같은 고도화된 모델을 개발할 수 있도록 제공된 라이브러리 및 모듈들이 상당히 많고 커뮤니티 형성도 매우 잘되어 있는 상당히 인기가 많은 프로그래밍 언어입니다.
- 다만, 파이썬 프로그래밍을 위해 파이썬 문법에 대한 이해가 필요하기 때문에 R에 비해서 알아두어야할 것들이 상당히 많지만, 다른 프로그래밍 언어들에 비해선 배우기 쉬운 언어에 속합니다.
- PyCharm, Jupyter Notebook, VSCode 등 다양한 통합개발환경(IDE)을 통해 이용할 수 있고, 다른 언어와의 호환성이 매우 좋아서 활용도가 높은 것이 특징입니다.
- 특히 Scikit-Learn, Tensorflow, Pytorch와 같은 머신러닝 및 딥러닝 라이브러리나 프레임워크를 제공하기 때문에, 모델링을 실시하는 경우 R보다는 훨씬 간결하고 정밀한 개발을 실시할 수 있습니다.
3-1. 시계열 데이터 만들어보기
- R을 이용하여 간단한 시계열 데이터를 만들어보고, 시각화를 진행해 보겠습니다.
- VSCode와 Jupyter Notebook을 통해 진행하였고, R은 4.2.3 버전을 이용했습니다.
- VSCode와 Jupyter Notebook을 통해 진행하였고, R은 4.2.3 버전을 이용했습니다.
- 시계열 분석에 사용할 R 라이브러리 및 패키지

- ts, tseries는 기본적으로 설치가 되어있어서, TSA와 forcast 패키지를 설치하고, 라이브러리를 불러옵니다.
# 라이브러리 설치 및 불러오기
install.packages('forecast')
install.packages('TSA')
library(forecast)
library(TSA)- 간단한 시계열 데이터 만들어보기
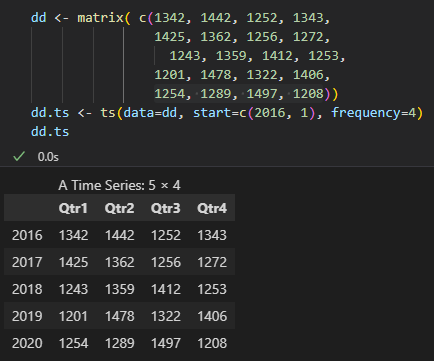
- 시계열 데이터는 ts라이브러리를 통해 만들어 볼 수 있고, start 인수로 시각할 연도와 데이터 시작지점을 설정할 수 있고, frequency 인수로 몇 분기로 나눌지를 설정할 수 있습니다.
3-2. 시계열 데이터의 주요 형태
- 시계열 데이터는 형태에 따라 다음과 같은 4가지의 형태로 분류할 수 있습니다.
- 우연변동 시계열 (Random Variation Time Series)
- 경향성이 없는 경우의 시계열 데이터
- 예시: 주기를 타지 않는 제품의 생산량, 판매량 데이터, 짧은 기간의 주가 데이터, 금리 등
- 계절변동 시계열 (Seasonal Variation Time Series)
- 주기적으로 반복되는 패턴이 있는 경우의 시계열 데이터
- 예시: 강수량, 적설량, 아이스크림 판매 추이, 전력 소비량, 성숙한 플랫폼의 데일리 트래픽 등
- 추세변동 시계열 (Trend Variation Time Series)
- 끝점이나 중간점을 중심으로 살펴보았을 때, 추세에 대한 패턴이 있는 경우의 시계열 데이터
- 예시: 물가 데이터, 희소 원자재 가격 데이터, 대부분의 주가지수 데이터
- 계절적 추세변동 시계열 (Seasonal Trend Variation Time Series)
- 주기적으로 반복되는 패턴도 있고, 추세에 대한 패턴도 보이는 경우의 시계열 데이터
- 우연변동 시계열 (Random Variation Time Series)
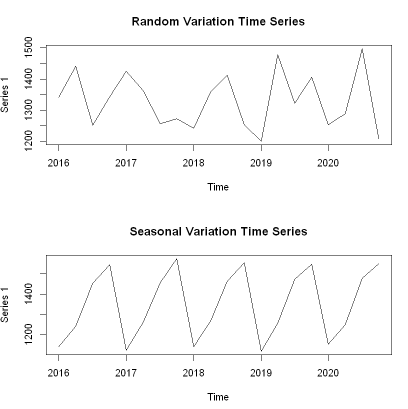
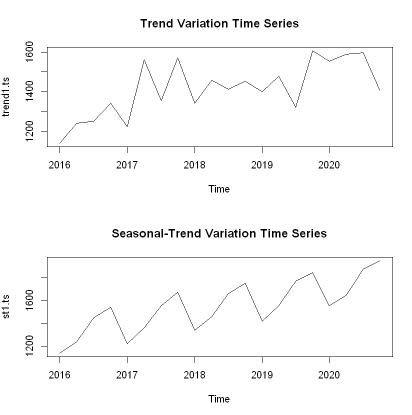
- 시계열 데이터의 형태로부터 시계열 데이터가 가지는 기본적인 속성들을 분류 해 볼 수 있습니다.
- 계절성(seasonal) : 주기적으로 반복되는 패턴
- 주기가 고정적이지 않은 경우엔 주기성(cycle)을 가진다고 표현합니다.
- 추세(trend) : 장기적으로 상승하거나 하락하는 패턴
- 불규칙요소(random, residual) : 예측 불가능한 임의의 변동성
- 설명될 수 없는 요인이나 돌발적인 요인에 의해 일어난 변화를 의미합니다.
- 일반적으로 계절성, 주기성, 추세를 뺀 나머지를 불규칙 요소라 정의합니다.
- 계절성(seasonal) : 주기적으로 반복되는 패턴
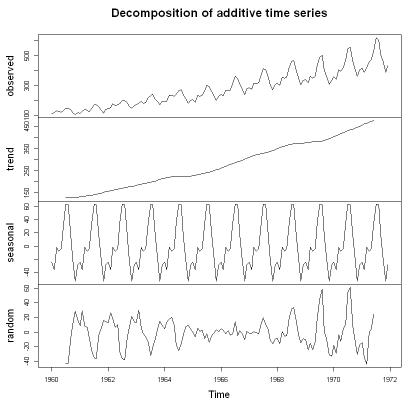
- 이러한 속성들을 분리해내는 과정을
시계열 분해(decomposition)이라 합니다.
3-3. 시계열 전처리 개요
- 우선 시계열이 시간에 상관없이 일정한 성질을 띄는 경우
정상성(Stationary)을 띄고있다고 표현합니다.- 정상성을 가지는 시계열이라는 것은 주기성이나 추세가 보이지 않는 시계열 데이터를 의미하는 것입니다.
- 좀 더 복잡한 정의로는 임의의 시점
t에 대한 기대값E(Xt),분산Var(Xt)등의 성질이 어느 시점에서 관측하더라도 변하지 않는 것을 의미합니다.
- 시계열 데이터를 전처리한다는 것은 비정상 시계열(추세, 계절성, 분산변동이 있는 시계열)을 정상시계열로 만들어주기 위한 과정을 의미하는 것입니다.
- 즉, 추세를 제거하거나(detrending) 계절성을 제거하거나(deseasoning) 분산을 일정하게 만들면 그 시계열은 정상성을 띄게 된다는 것입니다.
- 추세와 계절성을 제거한 나머지(residual)가 정상성을 띄도록 하는 것이 전처리의 주된 목적이라 볼 수 있습니다.
- 추세와 계절성을 제거하기 위한 방법으로는 대표적으로 다음의 세가지 방법이 있습니다.
- 회귀분석(Regression approach)
- 평활법(Smoothing)
- 차분(Differencing)
- 회귀분석은 이후에 머신러닝을 통해 다루어볼 것이고, 본 글에서는 차분과 평활법에 대해 살펴보도록 하겠습니다.
차분(Differencing)
차분(Differencing)이란 이어진 데이터들의 차이를 구하는 것입니다.- 한번의 차이를 구하는 것을 1차 차분이라하고, 1차 차분값을 다시 한번 차분하는 것을 2차 차분이라 합니다.
- 데이터 길이가 충분한 경우엔 여러번의 차분을 실시할 수 있지만, 2차 이상의 차분을 할 경우 데이터 소실이 커져서 설명력이 낮아질 수 있습니다.
- 일반적으로는 1차 차분만으로도 정상적인 시계열이 만들어지는 경우가 대부분이긴 합니다.
1차 차분:- t시점의 y값에서 t-1시점의 y값을 빼는 것
- 추세를 제거하기 위한 방법
계절성 차분:- t시점의 y값에서 t-m시점의 y값을 빼는 것 (m은 주기의 길이를 뜻합니다)
- 계절성을 제거하기 위한 방법
- 차분을 거치면 시계열이 정상적으로 변하는 이유 : 대부분의 비정상적 시계열은 값이 누적되는
누적과정(Integrated Process)이기 때문에 누적된 값을 빼줌으로써 정상적 시계열을 얻어 낼 수 있습니다.
- (실습) 차분
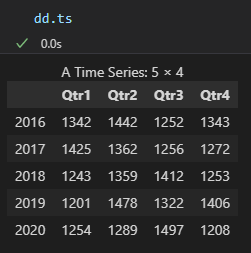
- 차분 실시
diff(data, lag)
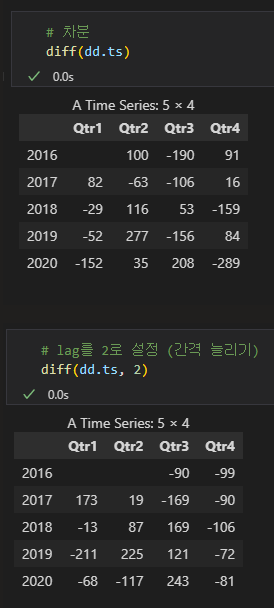
- 여기서 lag는 간격을 의미하고, lag를 2로 설정하는 것은 t-2시점의 데이터를 빼준다는 의미입니다.
- 즉, 계절성 차분의 m값을 의미하는 것입니다.
역차분(Inverse Difference)
- 차분과는 반대로 역차분(Inverse Difference)이라는 개념도 있습니다.
- 우리가 차분을 통해 추세와 계절성을 제거하는 이유는 분석이나 모델링에 정상성을 띄는 데이터를 입력해 주기 위함입니다.
- 그러나 데이터를 해석하기 위해선 전처리 과정을 거친 데이터를 역으로 계산해주는 과정을 통해 원래의 단위로 맞추어 줄 필요가 있습니다.
- 분석이나 모델링에 이용하기 위한 데이터로 전처리해주는 과정은
인코딩(부호화), 역으로 값을 되돌리는 과정은디코딩(복호화)라 표현하기도 합니다.- 정확한 의미에서 인코딩은 컴퓨터가 이해할 수 있는 언어로 변환시켜주는 과정을 의미하고, 디코딩은 컴퓨터가 이해할 수 있는 언어를 사람이 이해할 수 있는 언어로 변환시키는 과정을 의미합니다.
역차분:- t시점의 변화량을 t-1시점의 y값으로 더해 주는 것으로, 이는 t시점까지의 누적변화량을 의미한다고도 볼 수 있습니다.
- (실습) 역차분
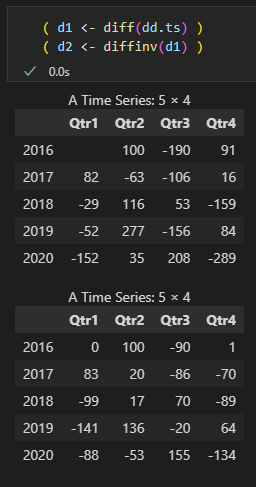
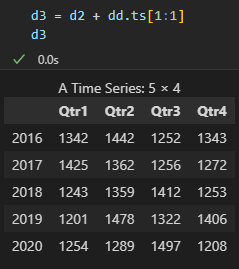
- 예시 : 2016년 3분기
- = -190
- = 100
- = = -190 + 100 = -90
- 역차분을 실시한 뒤에 모든 값에 첫 데이터값을 더해주면 최종적으로 원래의 데이터로 복원시킬 수 있습니다.
평활법(Smoothing)
- 과거의 데이터를 이용해 현재나 미래의 값을 추측하는 모델을 상태-공간 모형(state-space model)이라 하고, 추측하고자하는 값에 따라 다음과 같은 세가지의 작업으로 분류됩니다.
- -> 상태공간모형 -> 추정
- t 시점이 j 시점보다 미래시점 ( j < t ) : 예측 (Prediction, Forcasting)
- t 시점이 j 시점과 같은 현재시점 ( j = t ) : 필터링 (Filtering)
- t 시점이 j 시점보다 과거시점 ( t < j ) : 평활화(Smoothing)
- 평활화는 현재까지 수집한 관측데이터(~)를 활용하여 현재까지의 상태변수의 히스토리 (~) 전체를 재추정하는 것을 의미합니다.
- 누락 데이터(missing data)를 채우는 경우나 금융 분야의 팩터 모형(factor model)의 계수를 추정하는 경우 등 다양한 경우에 쓰입니다.
- 필터링은 현재까지 수집한 관측데이터(~)를 활용하여 현재시점의 상태변수 값 ()를 추정하는 것을 의미합니다.
- 필터링과 평활화는 정의상으로는 구분 되긴 하지만, 평활화 과정으로도 필터링 과정을 수행할 수 있기 때문에, 일반적으로는 평활화 개념에 필터링을 포함시켜서 정의하기도 합니다.
- 대표적인 예시로 칼만 필터가 있고, 이는 추후에 다시 다루어볼 예정입니다.
- 평활화의 주된 목적 중 하나는 시계열 자료의 무작위성(변동성, 분산)을 줄여주는 것이고, 이를 통해 좀 더 쉽게 추세를 파악할 수 있습니다.
- 다만 변동성을 줄임으로 인한 정보손실이 일어날 수 있다는 한계가 있습니다.
- 대표적인 평활화 기법은 다음과 같이 5가지 정도를 꼽아볼 수 있지만, 보통 고전적인 방법인 이동평균 평활법과 지수 평활법이 가장 많이 쓰입니다.
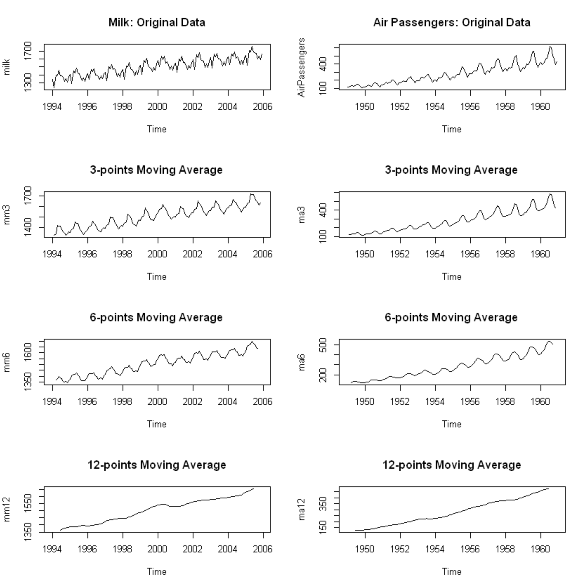
- 이동평균 평활법 (Moving Average(MA) Smoothing)
- 과거로부터 현재까지의 시계열 자료를 대상으로 일정 기간별 이동 평균을 계산하고 이들의 추세를 통해 다음 기간을 예측하는 방법
- 지수 평활법 (Exponential Smoothing)
- 모든 시계열 자료를 사용하여 평균을 구하고, 시간의 흐름에 따라서 최근 시계열에 더 많은 가중치를 부여하여 미래의 값을 예측하는 방법
- OLS Smoothing(회귀모형 평활법)
- Holt-Winters Smoothing
- Kernel Smoothing
- 이동평균 평활법 (Moving Average(MA) Smoothing)
- (예시) 이동평균 평활법
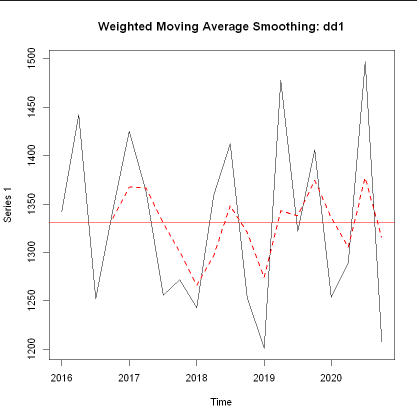
- (예시) 지수평균 평활법
3-4. 시계열 데이터 EDA 개요
- 시계열 자료는 우연변동, 추세변동, 계절변동, 주시변동 등 다양한 변동들이 중첩되어 있기 때문에 시계열 자료에서 추세와 주기를 파악하는 것은 분석에서 중요합니다.
- 분석이나 모델링을 위해 데이터의 구조나 특징들을 파악하는 과정을 EDA(탐색적 데이터 분석, Exploratory Data Analysis)라 하며, 이러한 EDA 과정은 시계열 데이터 뿐 아니라 모든 형태의 데이터에 대해서 필수적으로 실시해주어야하는 과정입니다.
- 데이터 사이언스 프로젝트의 과정 중 전처리와 EDA과정이 80%이상의 시간을 차지한다는 말이 있을 정도로 전처리와 EDA는 상당히 중요한 의미를 가지는 과정입니다.
- 시계열 데이터 분석에서 가장 대표적인 EDA방법으로는 시계열 데이터의 요소를 분해하는 요소분해(Decomposition)가 있습니다.
요소분해(Decomposition)
- 요소분해란, 시계열 자료를 추세변동, 주기변동, 우연변동으로 구분하여 각 요소로 분해하는 과정을 의미합니다.
- 중접된 변동 요인들을 분해하는 목적은 추세와 주기를 제거함으로써 남은 잔차(residual) 시계열 데이터를 정상시계열(Stationary Time Series)로 만들기 위함입니다.
- 대부분의 시계열 자료들은 추세변동과 주기변동을 제외하는 경우에 잔차 시계열은 정상 시계열이 됩니다.
- 만약 잔차 시계열이 정산 시계열이 되지 않는 경우에는 더욱 정밀한 추가분석이 필요할 수도 있습니다.
- 요소분해(Decomposition)는 시계열 데이터()를 추세 및 주기변동(), 계절변동(), 우연변동()으로 구분하여 성분을 추출하며, 분해 방법에 따라 가법모형(Additive)과 승법모형(Multiplicative)으로 나뉠 수 있습니다.
- 가법 모형 (덧셈 분해, Additive decomposition)
- 선형적으로 구성된 방법이며, Trend와 Seasonal이 서로 독립적이라 가정할 수 있는 경우에 이용됩니다.
- 승법 모형 (곱셈 분해, Multiplicative decomposition)
- 비선형적으로 구성된 방법이며, Trend에 따라서 Seasonal이 변화한다 볼 수 있는 경우에 이용됩니다.
- 승법 모형에서 Log 변환을 실시하면 곱하기 형태가 더하기 형태로 변하기 때문에 가법 모형의 식으로 변환시킬 수 있습니다.
- 다만 주의할 점은 데이터에 어떠한 경우에도 0이 존재해서는 안됩니다. (다른 값에 관계없이 결과가 0이 되기 때문)
- 가법 모형 (덧셈 분해, Additive decomposition)
-
(예시) 가법모형 vs 승법모형
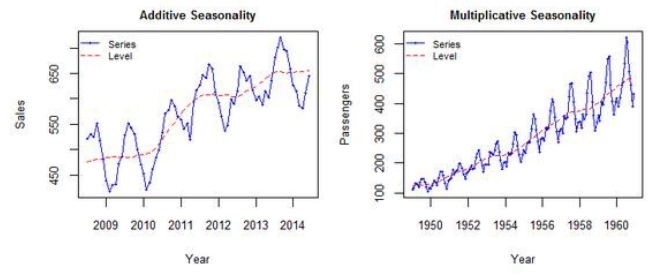
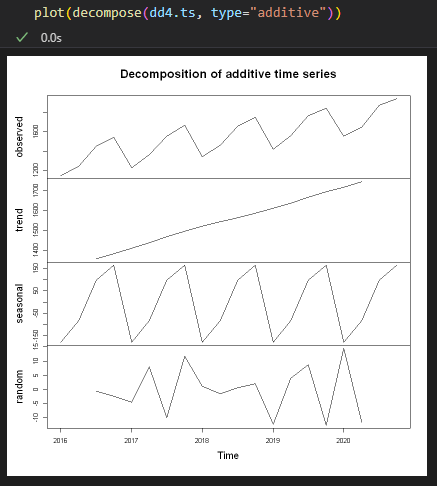
- 왼쪽 처럼 시간이 지남에 따라 변동폭이 일정한 경우엔 Additive(가법)모형을 쓰는 것이 적절하고, 오른쪽 처럼 시간이 지남에 따라 변동폭이 증가하는 경우엔 Multicative(승법)모형을 쓰는 것이 적절합니다.
-
(실습) 계절적 추세변동 시계열의 요소분해
- 가법 모형(Additive)
- 승법 모형(Multiplicative)
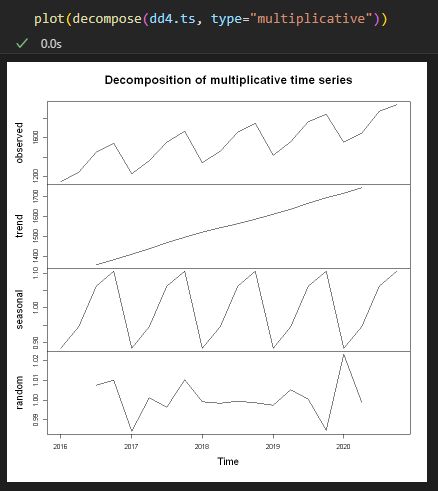
마무리
시계열 데이터에 관한 정리
-
시계열 데이터는 동일한 대상을 여러 시점에 걸쳐서 관측한 일련의 기록입니다.
- 시계열 데이터가 일반적인 데이터와 다른 접근 방식을 가지는 이유는 시계열 데이터가 가지는 통계적인 특성 때문입니다.
- 일반적인 데이터의 추론 문제에서는 개별 데이터간의 독립성을 기본적으로 전제하여 분석이 진행되지만, 시계열 데이터에서는 관측 시점에 따른 자기상관성(autocorrelation)을 보이기 때문에 일반적인 데이터 분석과는 다른 방향으로 접근해야 합니다.
-
시계열 데이터에서 자기상관(autocorrelation)이란, 특정 시점 t 에서의 관측값이 이전 시점 (t-1, t-2, ...)의 관측값과 상관관계가 있다는 것을 의미하고, 현재 데이터가 과거 데이터에 의해 얼마나 영향을 받았는지를 기억(Memory)라는 개념으로 표현합니다.
- 다시말해 시계열 모델링의 기본은 현재 데이터를 설명하는 데 있어서 과거 시점 데이터를 얼마나 활용하는지에 따라 달라질 수 있음을 의미합니다.
- 이러한 개념은 LSTM(Long Short Term Menmory), GRU와 같은 딥러닝의 장단기 기억모형에서 중요하게 쓰이는 개념입니다.
-
시계열 데이터에는 금융데이터, 센서데이터, 제조데이터, 기상데이터 등 다양한 분야에서 각자의 특성에 알맞게 발전해온 모델들이 있습니다.
- 일반적으로 시계열 데이터의 분석 방법론은 시간 도메인(time domain)과 진동수 도메인(frequency domain)으로 나뉩니다.
- 특히 진동수 도메인(frequency domain)은 신호처리 분야에서 주로 사용되고 있고, 이러한 분야에서는 진동수의 노이즈를 제거하는 방법에 많은 관심을 두고 있습니다.
- 하지만 일반적으로는 시계열 데이터는 일정하고 이산적인 시간 간격을 전제로 하고 있고, 이러한 경우엔 시간 도메인(time domain)이 주로 이용하게 됩니다.
- 일반적으로 시계열 데이터의 분석 방법론은 시간 도메인(time domain)과 진동수 도메인(frequency domain)으로 나뉩니다.
-
일반적으로는 시계열 데이터는 일정하고 이산적인 시간 간격을 전제로 하는 시간 도메인(time domain)영역에서는 이러한 시계열 데이터를 하나의 연속된 배열(시퀀스)로 보기도 하며, 이러한 시퀀스 기반의 분석이 가장 많이 활용되는 분야가 GPT, BERT와 같은 자연어처리(NLP) 분야임
키워드 정리
- 데이터 분석 통계 기초
- 1-1. 통계 분석의 범위
- 기술통계 (Descriptive Statistics)
- 추론통계 (Inferential Statistics)
- 표본(sample), 모집단(population)
- 표집분포(sampling distribution)
- 1-2. 통계적 가설검정
- 귀무가설,영가설(Null hypothesis)
- 대립가설(Alternative hypothesis)
- 1종오류 (Type I Error), 유의수준(significant level)
- 2종오류 (Type II Error)
- p-value (Probability-value)
- 예측모델과 시계열모델
- 2-1. 예측모델
- 회귀모델 (Regression)
- 분류모델 (Classification)
- 이진분류 (Binary Classification)
- 다중분류 (Multi-Class Classification)
- 2-2. 시계열 모델
- 자기상관(autocorrelation)
- 예측(Prediction, Forcasting)
- 시계열 분석 기초
- 3-1. 시계열 데이터 만들어보기
- R, Python
- R 시계열 라이브러리
- ts, tseries, TSA, forcast
- 3-2. 시계열 데이터의 주요 형태
- 우연변동 시계열 (Random Variation Time Series)
- 불규칙요소(random, residual)
- 계절변동 시계열 (Seasonal Variation Time Series)
- 계절성(seasonal)
- 추세변동 시계열 (Trend Variation Time Series)
- 추세(trend)
- 계절적 추세변동 시계열 (Seasonal Trend Variation Time Series)
- 우연변동 시계열 (Random Variation Time Series)
- 3-3. 시계열 전처리 개요
- 정상성(Stationary)
- detrending, deseasoning
- 회귀분석(Regression approach)
- 평활법(Smoothing)
- 차분(Differencing)
- 차분(Differencing)
- 1차 차분, 계절성 차분(lag)
- 역차분(Inverse Difference)
- 인코딩(부호화), 디코딩(복호화)
- 평활법(Smoothing)
- 상태-공간 모형(state-space model)
- 예측 (Prediction, Forcasting)
- 필터링 (Filtering)
- 평활화 (Smoothing)
- 이동평균 평활법 (Moving Average(MA) Smoothing)
- 지수 평활법 (Exponential Smoothing)
- 상태-공간 모형(state-space model)
- 3-4. 시계열 데이터 EDA 개요
- EDA(탐색적 데이터 분석, Exploratory Data Analysis)
- 요소분해(Decomposition)
- 가법 모형 (덧셈 분해, Additive decomposition)
- 승법 모형 (곱셈 분해, Multiplicative decomposition)
간단 회고 및 마무리
- 머신러닝 엔지니어로써 첫 출근을 앞두고 미리 공부하고 정리할 만한 것이 무엇이 있을지 고민하던 중 센서데이터를 주로 다루는 기업이기에 시계열 데이터에 대한 이해가 필요하다 생각이 들어서 시계열 데이터에 대한 공부를 시작하게 되었습니다.
- 패스트캠퍼스의 시계열 분석 강의를 통해 학습과 실습을 진행하였는데, 이번 파트에서 R을 처음 써보게 되었는데 여태까지 Python을 쭉 써와서 아직은 R에 대한 사용법이 익숙하지 않아서 그런지 생각보다 R 코드를 이해하는게 쉽지는 않았었고, python언어가 왜 직관적이라 하는지를 더 이해할 수 있었던 시간이었습니다.
- 강의에서 실습은 Colab을 통해 진행되었지만 Colab을 그다지 선호하지 않았기에 그동안 써왔던 IDE인 VSCode에서 Jupyter와 R을 사용할 수 있게끔 세팅하는 작업을 먼저 진행했었습니다. 이 과정에서 상당히 시행착오를 많이 겪었었는데 이에 관련한 내용은 Linux 기반의 명령어처리, 가상환경, 환경변수 설정 등 다뤄야할 내용이 너무 많고 복잡하기도해서 언젠가 시간이 나면 정리해보도록 하겠습니다..
- 그 다음 과정부터는 Python으로 본격적인 머신러닝과 딥러닝 분석 방법을 배울 예정이고, 어느정도는 아는 개념들이 많아서 이번 파트보다는 다소 수월하게 진행할 수 있을 것 같습니다. 이번 기초 파트가 워낙 중요하다 생각해서 다소 내용들이 많아지고 복잡해지긴 했지만 이후에 배우게 될 내용들은 최대한 간단하게 정리하는 식으로 글을 작성해보고자합니다.
- 첫 출근까지는 기간이 얼마 안남아 있긴하지만, 최대한 힘을 내서 강의 내용 정리를 마치고 좀 더 수월하게 직무에 적응 할 수 있기를 바래보고 다짐해봅니다! 모두들 화이팅!

3개의 댓글

It is essential to have a fundamental knowledge of statistics and time series, as it is used practically everywhere. Although a little technical in nature, if you are studying law, you may be able to relate and think on a basic level about data and it's interpretation or analyze it. For academic assistance, there are always students that might consider something along the lines of https://lawassignmenthelper.co.uk/.

I like to read your content, which is impressive and thoughtful!
Do you want Law Assignment Help UK? At casestudyhelp.com, you can get the best university assignment help. We also provide AI-free content and customize assignment writing help for students.
https://casestudyhelp.com/uk/law-assignment-help.html
안녕하세요?
시계열 분석 내용을 잘 정리가 되어있어서 도움이 많이 되네요..
감사드립니다.
간략한 소개를 보니 AI 엔지니어라도 되어있네요..
관련업체에 근무를 하시나요?
혹시
시계열 데이터를 활용한 AI 모델을 구축 할려고 하고 있습니다.
관심이 있으시면 yoon3255@daum.net 메일주세요!!