
시계열 데이터 분석에 필요한 개념들을 요약하여 정리하는 시리즈 - 2. 머신러닝과 지도학습 모델 편
머신러닝 (Machine Learning)
1. 머신러닝이란?
- 머신러닝(기계학습)은 데이터를 기반으로 학습이나 성능 향상을 구축하는데에 초점이 맞추어진 컴퓨터 알고리즘을 의미하며, 빅데이터의 등장과 함께 개발되고 발전되어온 인공지능(AI)의 하위 집합이기도 합니다.
- 머신러닝의 목표는 꾸준한 경험(데이터 및 학습)을 통해 어떠한 작업에 대한 성능을 높이는 것이라 볼 수 있고, 이러한 작업은 사람이 직접 수행하는 것이 아니라 컴퓨터가 실시하기 때문에 기계학습이라고도 불립니다.
- 머신러닝은 주로 해석 가능한 수학적 모델을 기반으로 하고있고, 주어진 입력의 특징(feature)를 벡터(vector)로 만들어서 특징 벡터의 기하학적인 관계를 기반으로 추론을 진행합니다.
- 최근들어 많은 화제가 되고 있는 딥러닝(Deep Learning)은 인경신경망을 기반으로 동작하는 머신러닝 기법으로, 머신러닝의 하위 개념 중 하나입니다.
2. 머신러닝의 학습
- 머신러닝은 학습은 종류에 따라 크게는 3가지로 나누어 볼 수 있습니다.
- 지도학습(Supervised Learning)
- 비지도학습(Unsupervised Learning)
- 강화학습(Reinforcement Learning)
- 여기에 추가적으로 준지도학습(Semisupervised Learning), 전이학습(Transfer Learning) 등 머신러닝에는 다양한 학습방법들이 존재합니다.
- 지도학습(Supervised Learning)
- 지도학습이란 각각의 입력(Feature, X)에 대해 정답(Label, y)을 달아 놓은 훈련 데이터를 컴퓨터에게 학습시키는 방법을 의미합니다.
- 머신러닝 알고리즘의 대부분은 지도학습의 형태이며, 학습 데이터 생성을 사람이 직접하기 때문에 정확도가 높은 데이터를 사용할 수 있다는 장점이 있습니다.
- 다만, 정답(label)을 사람이 직접 달아주는 라벨링(labeling)작업이 필요하다는 단점이 있고, 이로인해 학습방법에 한계가 생길 수 있습니다.
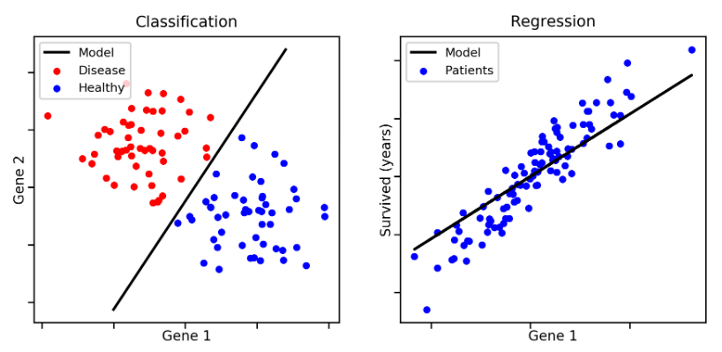
- 지도학습은 Label의 형태에 따라 분류문제와 회귀문제로 나뉠 수 있습니다.
- 분류(Classification) : Label인 y가 이산적(Discrete)한 경우를 의미합니다.
- 이산적이라는 것은 y값이 유한하게 구분 될 수 있는 경우를 뜻합니다.
- 일상에서 가장 접하기 쉽고, 연구가 많이 되어있으며, 가장 많은 관심이 집중되어 있는 분야이기도 합니다.
- 대표적인 기법들로는 로지스틱회귀법, KNN, 서포트벡터머신(SVM), 의사결정트리 등이 있습니다.
- 회귀(Regression) : Label인 y가 연속적(Continuous)인 경우를 의미합니다.
- 연속적이라는 것은 y가 실수의 값으로 표시한다는 것이고, 값의 수를 유한하게 셀 수 없음을 뜻합니다.
- 데이터를 가장 잘 설명하는 직선, 곡선, 평면 등을 그려내어 y값을 예측하는 선형회귀 기법이 가장 대표적인 회귀 기법 중 하나입니다.
- 분류(Classification) : Label인 y가 이산적(Discrete)한 경우를 의미합니다.
- 지도학습이란 각각의 입력(Feature, X)에 대해 정답(Label, y)을 달아 놓은 훈련 데이터를 컴퓨터에게 학습시키는 방법을 의미합니다.
- 비지도학습(Unsupervised Learning)
- 비지도학습이란 레이블 되어 있지 않은 데이터에 대해 컴퓨터가 스스로 학습하는 것을 의미합니다.
- 비지도학습의 종류
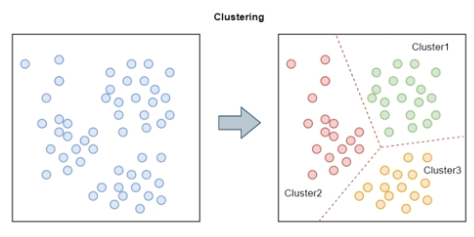
- 군집화(Clustering) : 데이터간 거리에 따라 데이터를 몇개의 군집으로 나누는 것으로 X값만을 가지고 학습 및 분류를 진행합니다.
- 대표적으로 K-Means Clustering 등이 있습니다.
- 분포 추정(Underlying Probability Density Estimation) : 군집화에서 더 나아가서 데이터들이 어떠한 확률 분포에서 나온 샘플인지를 추정합니다.
- 차원축소 : 차원 수가 많아지면 경향성을 파악하거나 데이터를 시각화하기 어려워질 수 있는 차원의 저주 문제를 해결하기 위한 방법으로 데이터간의 관계를 유지하면서 차원을 줄이는 방법을 의미합니다.
- 대표적으로 주성분분석(PCA, Principle Component Analysis) 등이 있습니다.
- 군집화(Clustering) : 데이터간 거리에 따라 데이터를 몇개의 군집으로 나누는 것으로 X값만을 가지고 학습 및 분류를 진행합니다.
- 대부분의 데이터들은 레이블이 없는 형태를 가지고 있기 때문에 이러한 데이터를 좀 더 효율적으로 분석할 수 있는 비지도학습에 대한 연구가 기계학습이 나아갈 방향이라고 보는 추세입니다.
-
강화학습(Reinforcement Learning)
- 강화학습은 현재의 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 학습하는 것을 의미합니다.
- 행동을 취할 때마다 외부 환경에서 보상(Reward)을 주고, 이러한 보상을 최대화하는 방향으로 학습이 진행됩니다.
- 바둑 프로그램 알파고의 학습방식으로도 많이 알려져 있습니다.
-
준지도학습(Semisupervised Learning)
- 지도학습과 비지도학습의 방법을 결합한 형태의 학습 방법으로, 레이블이 있는 데이터와 없는 데이터를 모두 활용하여 학습을 진행합니다.
- 대부분의 경우 약간의 레이블 있는 데이터로 다수의 레이블 없는 데이터를 보충하여 반복적으로 학습시키는 방식으로 진행됩니다.
- 사람 대신 컴퓨터가 직접 레이블을 실시하도록 하는 경우는 자가지도 학습(Self-supervised Learning)이라는 용어로도 불리는데, 이에 대한 대표적인 예로는 오토인코더 등이 있습니다.
- 지도학습과 비지도학습의 방법을 결합한 형태의 학습 방법으로, 레이블이 있는 데이터와 없는 데이터를 모두 활용하여 학습을 진행합니다.
-
전이학습(Transfer Learning)
- 전이학습은 사전에 대량의 데이터로 미리 학습시켜놓은 모델을 활용하여 머신러닝의 성능을 극대화하는 학습을 의미합니다.
- 자연어처리, 컴퓨터비전 분야에서 특히 많이 쓰이는 방법이고, 사전에 학습된 모델을 가져오고 목적에 맞게 모델을 재구성하는 방식으로 진행되며, 이러한 재구성 단계를 Fine-Tuning이라고 부릅니다.
3. 지도학습 모델 - 선형회귀
- 이번 글에서는 다양한 머신러닝 기법들 중에서도 지도학습 모델들에 대해 살펴볼 것입니다.
- 우선 Label인 y가 연속적(Continuous)인 회귀 방법 중에서 대표적으로 선형회귀(Linear Regression)에 대해 살펴보도록 하겠습니다.
선형회귀(Linear Regression)의 정의
-
선형회귀(Linear Regression)란 종속 변수 y와 한 개 이상의 독립 변수 (또는 설명 변수) X와의 선형 상관 관계를 모델링하는 회귀분석 기법을 의미합니다.
- 즉, 주어진 데이터로부터 y 와 x 의 관계를 가장 잘 나타내는 직선을 그리는 일을 뜻합니다.
-
일반적으로 라는 수식으로 나타낼 수 있고, b는 절편을 의미하고, error는 오차항을 의미합니다.
-
처럼 특성(feature)가 늘어나는 경우를 다중회귀(multiple regression)라고 부릅니다.
-
처럼 차원수가 2차항 이상으로 높아지는 경우엔 다항 회귀(Polynomial Regression)라 부릅니다.
-
-
선형 회귀를 실시하는 경우 다음과 같은 가정들을 최대한 만족해야하며, 이러한 가정들을 만족하는 최선의 경우를 BLUE(Best Linear Unbiased Estimator)라 부릅니다.
- 가정 1: 종속변수는 독립변수의 계수와 선형관계이다 (선형성)
- 가정 2: 독립변수 사이에 선형관계가 없다
- 가정 3: 독립변수는 오차항과 상관이 없다
- 가정 4: 오차항은 서로 독립적이며 서로 연관되어 있지 않다
- 가정 5: 오차항의 평균은 0이다
- 가정 6: 오차항의 분산은 일정하다
선형회귀의 오차함수와 평가지표
-
선형회귀에서는 y 와 x 의 관계를 가장 잘 나타내는 직선을 그리기 위해 예측 직선과 실제값과의 차이를 줄이는 방향으로 기울기와 절편을 조정하게 되고, 이때 대표적으로 오차의 제곱을 통해 추정(Least Squares Estimation)하는 방법으로 조정이 이루어집니다.
-
선형회귀 모형의 성능을 평가하는 지표로는 다양한 지표들이 있지만, 대표적으로는 MAE, MSE, RMSE, R Squared 등이 있습니다.
- MAE(Mean Absolute of Errors) 평균절대오차 : 예측값 - 관측값들의 절대값을 통해 음수를 처리한 뒤, 이들의 평균을 통해 구할 수 있습니다.
- MSE(Mean Square of Errors) 평균제곱오차 : 예측값 - 관측값의 제곱값들의 합을 잔차제곱합(RSS)이라하며, 잔차제곱합(RSS)의 평균을 통해 구할 수 있습니다.
- RMSE(Root Mean Square of Errors) 평균제곱오차제곱근 : MSE는 제곱으로인해 이상치에 매우 민감하기 때문에, 이에 제곱근을 통해 값이 지나치게 커지는 것을 방지할 수 있습니다. 이러한 평가지표를 RMSE라 합니다.
- (R Squared Score) 결정계수 : 설명력이라고도 표현되며, 0~1까지 수로 나타내어지며 1에 가까울수록 설명력이 높다고 부릅니다.

- 수식으로 쉽게 표현하면 으로 표현할 수 있습니다.
선형회귀의 과적합 방지 (규제화)
- 선형회귀에서 y 와 x 의 관계를 가장 잘 나타내는 직선을 그리고자하는 경우 모델이 학습 데이터에 최대한 최적화하려다 보면 모델의 복잡도가 상승하게 되는데, 이러한 최적화가 심해지면 학습데이터에만 적합하고 일반화 가능성은 떨어지는 과적합(Overfitting)문제가 발생할 수 있습니다.
- 이러한 과적합 문제를 피하거나 줄이기 위해서 MSE 등과 같은 오차함수에 규제항을 추가해줄 수 있는데, 이를 Regulation(규제화)이라고 부릅니다.
- Regulation(규제화)의 방법이 적용된 선형회귀 기법에는 대표적으로 3가지가 있습니다.
- Lasso (L1) Regression
- Ridge (L2) Regression
- Elastic-Net (L1 + L2)
- 이와 관련한 내용은 추후에 딥러닝을 다루는 글에서 자세히 다룰 예정입니다.
4. 지도학습 모델 - 분류 모델
- 분류 모델은 크게 선형모델과 트리형모델로 나뉠 수 있습니다.
선형 분류 모델
- 선형적인 관계를 통해 분류를 수행하는 모델로써 대표적으로 다음과 같은 모델들이 있습니다.
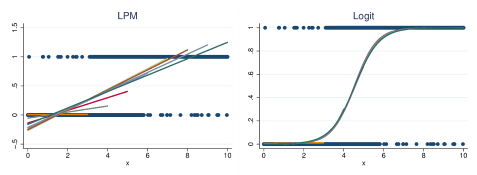
- Linear Probability Model (선형확률모델)
- Logistic Regression
- 0~1사이의 확률값(logit)을 통해 분류를 진행하는 선형모델로써, Logistic Regression은 주로 이진분류문제(binary classification)에서 많이 쓰입니다.
- 다중분류문제의 경우엔 Logistic Regression을 활용한 Softmax Classifier를 이용하게 됩니다.
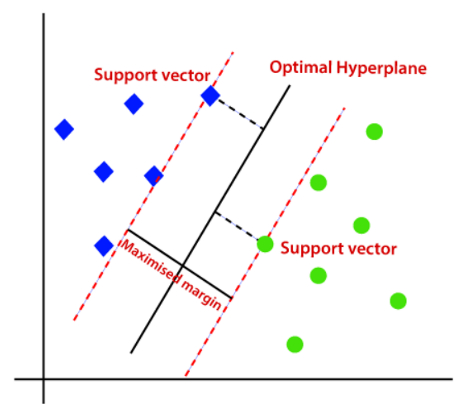
- SVM(Support Vector Model)
- 데이터간의 거리가 어느정도 떨어져있다 가정할 때 이를 분리하는 벡터인 hyperplane을 찾는 것을 통해 분류를 수행하는 모델입니다.
- 다차원인 경우에도 유연하게 그릴수 있다는 장점이 있지만, 데이터 수가 많은 경우엔 성능이 좋지 않고 시간도 상대적으로 오래걸린다는 단점이 있습니다.
트리형 분류 모델
- 컴퓨터 과학에서의 자료구조 중 하나인 트리형 자료구조를 통해 분류를 수행하는 모델입니다.
- 가장 기본적인 트리형 분류 모델로 의사결정나무(Decision Tree)가 있고, 데이터를 특정 기준을 통해 분기함으로써 분류작업을 수행하게 됩니다.
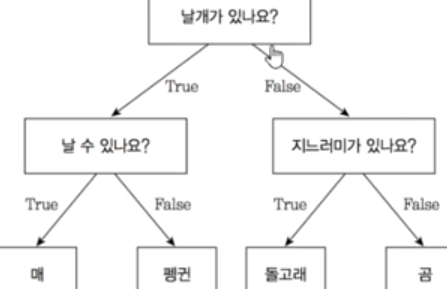
- Decision Tree의 기본적인 아이디어는 sample이 가장 섞이지 않은 상태로 완전히 분류되도록 하는 것, 다시 말해서 엔트로피(Entropy) 혹은 지니 계수 (Gini Index)를 낮추도록 만드는 것입니다.
- 엔트로피는 쉽게 말해서 무질서한 정도를 정량화(수치화)한 값이고, 지니 계수 (Gini Index)는 불순도를 측정하는 지표로 데이터의 통계적 분산정도를 정량화(수치화)한 값입니다.
앙상블 트리 모델
- 의사결정나무의 과적합과 과소적합을 줄이고 성능을 높이기 위해 개발되고 발전되어온 앙상블 트리 모델들이 있습니다.
- 앙상블 모델의 기본적인 아이디어는 약한 학습기(Weak Learners)도 모이면 강력한 학습기(Strong Learners)가 될 수 있다는 것입니다.
- 앙상블 모델은 크게 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking) 모델이 있으며, 각자의 앙상블 모델들이 가지는 장단점들이 존재합니다.

- 배깅(Bagging)
- 배깅은 부트스트랩(복원추출)을 통해 트리모델을 각각 형성하고, 이들의 예측 결과를 종합하는 방식으로 집계(Aggregating)를 하는 방식입니다.
- 병렬적(Parallel)으로 진행되고, 각 트리는 서로 독립적입니다.
- 회귀문제(연속형)의 경우엔 평균을, 분류문제(범주형)의 경우엔 최빈값을 기준으로 집계를 합니다.
- 과적합을 줄이는데 특화되어 있습니다.
- 대표적인 배깅 알고리즘으로는 랜덤 포레스트(Random Forest)가 있습니다.
- 배깅은 부트스트랩(복원추출)을 통해 트리모델을 각각 형성하고, 이들의 예측 결과를 종합하는 방식으로 집계(Aggregating)를 하는 방식입니다.
- 부스팅(Boosting)
- 부스팅은 배깅과는 다르게 순차적으로 트리를 형성하는데, 이전 분류기의 학습 결과를 토대로 다음 분류기의 학습 데이터의 샘플 가중치를 조정해 학습을 진행하는 방법입니다.
- 과적합에는 취약한 편이지만, 모델의 성능은 대체적으로 높게 나타납니다.
- 대표적인 예로는 Gradient Boosting Model(GradientBoostingClassifier), XGBoost, LightGBM (LGBMClassifier) 등이 있습니다.
- XGBoost는 트리를 만들때 level-wise하게 만들기 때문에 시간도 오래걸리고 과적합이 일어날 가능성이 높습니다.
- LightGBM은 XGBoost모델의 단점을 개선시킨 모델로 트리를 만들때 leaf-wise하게 만들기 때문에 시간도 적게 걸리고 성능면에서는 XGBoost와의 큰 차이가 없어서 현재로써는 가장 효율적인 부스팅 모델로 주목받고 있습니다.
- 다만 아직은 다른 프로그래밍 언어와의 호환성이 조금 떨어지고 MLOps와 결합할때 최적화가 다소 힘들다는 단점이 있습니다.
- 부스팅은 배깅과는 다르게 순차적으로 트리를 형성하는데, 이전 분류기의 학습 결과를 토대로 다음 분류기의 학습 데이터의 샘플 가중치를 조정해 학습을 진행하는 방법입니다.
- 스태킹(Stacking)
- 스태킹은 크로스 벨리데이션(Cross Validation) 기반으로 서로 상이한 모델들을 조합하는 방식입니다.
- 데이터를 교차검증 방식으로 쪼개어 Base Learner들을 만들어 학습하고 예측한 데이터들을 다시 meta data set으로 사용해서 학습하는 방식으로 진행됩니다.
- 성능은 높게 나오는 편이지만 과적합이 일어날 가능성이 높습니다.
분류모델의 평가지표
-
분류모델의 평가지표는 실제 레이블과 예측 레이블이 얼마나 일치하는지를 통해 계산됩니다.
-
분류모델의 평가지표는 실제값과 예측값에 대한 오차행렬(Confusion Martix)을 통한 값들을 통해서 계산될 수 있으며, 계산 방법에 따라 다양한 종류의 평가지표들이 존재합니다.
-
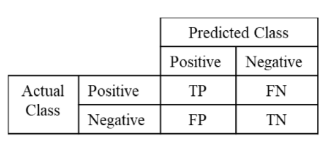
오차행렬(Confusion Martix)
- True(T) or False(F) : 실제값과 예측값이 일치하는지 여부를 의미합니다.
- Positive(P) or Negative(N) : 특정값(보통은 0,1 중 1을 의미)에 대한 예측결과를 의미합니다.
- 레이블이 Positive(P) 나 Negative(N) 일 때
- TP(True Positive) : 실제값이 P일때 예측값이 P인 경우
- FP(False Positive) : 실제값이 N일때 예측값이 P인 경우
- FN(False Negative) : 실제값이 P일때 예측값이 N인 경우
- TN(True Negative) : 실제값이 N일때 예측값이 N인 경우
- 영가설과 대립가설의 관점에서의 오류(Error) 타입
- FP는 실제값이 N (영가설이 참)일때 예측값이 P인 경우로써, 1종 오류에 해당합니다.
- 예시1 : 실제로는 수술이나 투약이 필요 없는데, 수술이나 투약이 필요하다 판단하는 경우
- 예시2 : 실제로는 정상메일인데, 스팸메일로 분류하는 경우
- FN은 실제값이 P (영가설이 거짓)일때 예측값이 F인 경우로써, 2종 오류에 해당합니다.
- 예시1 : 실제로는 암이 있는데, 암이 없다고 판단하는 경우
- 예시2 : 실제로는 스팸메일인데, 정상메일이라 분류하는 경우
- FP는 실제값이 N (영가설이 참)일때 예측값이 P인 경우로써, 1종 오류에 해당합니다.
-
분류 모델의 평가지표
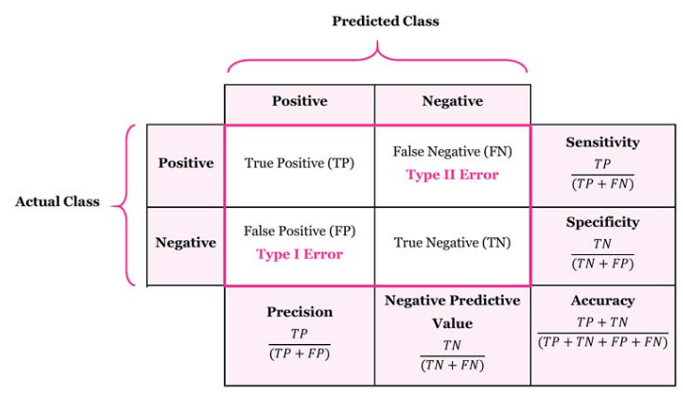
- Accuracy(정확도)
- 실제와 예측이 일치(True)하는 비율
- Accuracy = =
- 일반적으로 가장 기본적으로 쓰이는 지표이지만, 타겟 불균형이 심해질 수록 값이 높아질수 있어서 보통은 다른 평가지표들을 함께 고려하여 성능을 평가합니다.
- Precision(정밀도)
- Positive라 예측한 데이터 중 실제로 Positive인 데이터의 비율
- Precision =
- FP를 고려하기 때문에 1종 오류와 관련이 있는 지표입니다.
- Recall(재현율), Sensitivity(민감도)
- 실제값이 Positive인 데이터 중 Positive라 예측한 데이터의 비율
- Recall =
- FN를 고려하기 때문에 2종 오류와 관련이 있는 지표입니다.
- TPR(True Positive Rate)라고도 불립니다.
- Specificity(특이도)
- 실제값이 Negative 데이터 중 Negative라 예측한 데이터의 비율
- Specificity =
- FP를 고려하기 때문에 1종 오류와 관련이 있는 지표지만, 보통 1종오류가 중요한 경우엔 Precision(정밀도)이 주로 쓰입니다.
- FPR(False Positive Rate)라고도 불립니다.
- F1 score
- Precision(정밀도)과 Recall(재현율)의 조화평균(비율의 평균)
- F1 = =
- Precision(정밀도), Recall(재현율) 모두를 종합적으로 고려할 때 이용되는 지표이고, 특히 타겟의 불균형이 매우 심할 경우에 주로 쓰이는 지표입니다.
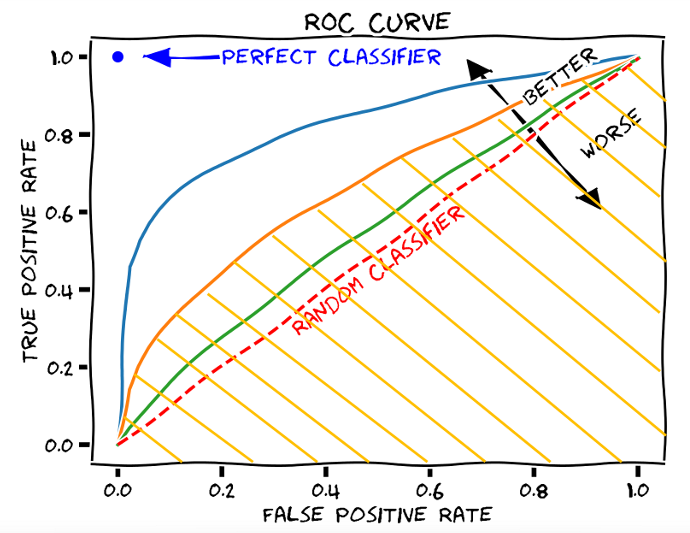
- AUC score (Area Under ROC curve)
- ROC curve는 x축을 FPR(특이도), y축을 TPR(재현율,민감도)로 놓고 Threshold에 따라서 그린 곡선을 의미합니다.
- AUC score는 약자의 의미 그대로 ROC curve의 아래 면적을 의미하고, x축에서 0부터 1까지의 적분연산을 통해 값을 구하게 됩니다.
- 모든 예측값을 하나의 클래스로 분류하는 경우엔 AUC score는 0.5로 가장 좋지 않은 성능을 보인다 해석하고, ROC curve가 (0,1)값 쪽으로 근접하는 경우 최대값이 1로 가장 좋은 성능을 보인다 해석합니다.
- Precision(정밀도), Recall(재현율) 모두를 종합적으로 고려할 수 있고 타겟 불균형 여부에 관계없이 사용할 수 있는 지표로써 성능을 평가하고 비교분석하는 경우에 가장 많이 쓰이는 지표 중 하나이지만, 각 threshold별로 계산하고 이에 대한 적분계산을 해주어야해서 연산시간이 다소 길어질 수 있다는 단점이 있습니다.
5. 머신러닝 특성 중요도
-
모든 연산 과정을 입증하고 설명할 수 있는 일반적인 과학분야의 연구방법(통계기반 연역적 연구방법)과는 달리 머신러닝을 비롯한 인공지능 모델들의 큰 단점은 모델이 복잡해질 수록 연산과정을 명확하게 설명하기 어려운 블락박스 문제(blackbox machine learning)있다는 것입니다.
- 이를 어느정도 보완하기 위해 설명가능한 AI(eXplainable Artificial Intelligence, XAI)의 연구가 활발하게 이루어지고 있고, 머신러닝 분야에서는 회귀계수와 특성중요도를 통해서 특정 변수가 얼마나 큰 영향력을 가지고 있는지를 확인할 수 있습니다.
-
머신러닝 모델에서 변수의 영향력을 계산하는 방법들
- 1) 선형 모델의 회귀계수(Coefficients)
- Feature(X)에 따라 Target(y)의 변량을 수치화한 값
- Feature(X)에 대한 가중치의 값으로도 표현할 수 있습니다.
- 장단점
- 변수 영향력의 방향(+는 긍정, -는 부정)을 알수 있고, 수치적으로 영향력을 설명할 수 있다는 장점이 있습니다.
- 변수의 스케일의 영향을 상당히 많이 받는다는 단점이 있어서 스케일을 맞추어주는 작업이 매우 중요합니다.
- Scikit-Learn에서 선형모델 학습 후
.coef_메서드를 통해 확인할 수 있습니다.
- 2) 트리 기반 모델의 MDI 기반 중요도
- MDI : Mean Decrease Impurity
- 특정 Feature가 모델에 적용될 때 분류 결과의 불순도(Impurity)를 얼마나 감소시켰는지를 측정하고 이에 대한 평균으로 특성의 중요도를 측정합니다.
- 불순도의 측정은 주로 Entropy나 Gini 불순도를 이용합니다.
- 모델이 분류를 잘하는 데에 Feature가 중요하게 작용할수록 값이 크게 나타납니다.
- 장단점
- 빠르고 간편하게 계산이 가능하다는 장점이 있습니다.
- high cardinality 특성에 높은 값을 부여하는 문제가 발생할 수 있습니다.
- Scikit-Learn에서 트리모델 학습 후
.feature_importance_메서드를 통해 확인할 수 있습니다.
- 3) Drop-Column Importance
- 각 특성을 사용하지 않고(drop하고) 모델을 학습한 후, 평가 성능을 모든 특성을 사용한 모델의 평가 성능과 비교합니다.
- 특성을 제거하였을 때 평가 성능이 크게 하락했다면 해당 특성이 매우 중요한 특성이 됩니다.
- 이론적으로는 가장 좋은 방법이지만 매 특성을 drop한 후 fit을 다시 해야 하기 때문에 매우 느리다는 단점이 있습니다.
- 각 특성을 사용하지 않고(drop하고) 모델을 학습한 후, 평가 성능을 모든 특성을 사용한 모델의 평가 성능과 비교합니다.
- 4) 순열(Permutation) 중요도
- 치환 기반 중요도라고도 불리며, 특정 Feature에 노이즈를 주었을 때(Random한 값으로 변환) 원래의 모델보다 예측 에러가 얼마나 커지는 지를 측정합니다.
- 노이즈를 주는 가장 간단한 방법이 그 특성값들을 샘플들 내에서 섞는 것(shuffle, permutation)입니다.
- 장단점
- 재학습이 필요없고 모든 모델에 범용적으로 적용가능하다는 장점이 있고, MDI 기반 중요도보다 high cardinality 특성에 덜 치우친 결과가 나타난다는 장점이 있습니다.
- 변수간의 강한 상관관계가 있는 특성들이 존재할 때, 잘못된 값(과대추정,과소추정)을 낼 수 있다는 단점이 존재합니다.
- Scikit-Learn의
permutation_importance메서드, eli5의PermutationImportance메서드를 통해 확인할 수 있습니다.
- 치환 기반 중요도라고도 불리며, 특정 Feature에 노이즈를 주었을 때(Random한 값으로 변환) 원래의 모델보다 예측 에러가 얼마나 커지는 지를 측정합니다.
- 5) LightGBM의 분기 기반 중요도
- LightGBM에서는 모델이 결정을 내리기까지 각 Feature로 split(분기)한 횟수를 통해 중요도를 기본적으로는 계산합니다.
- 파라미터 설정을 바꾸면 각 분기에서 얻은 정보이득(gain)의 총합으로 나타낼 수도 있습니다.
- MDI처럼 Scikit-Learn에서
.feature_importance_메서드를 통해 확인할 수 있습니다.- 이경우엔 LGBMClassifier나 LGBMRegressor를 통해 Scikit-Learn에 최적화된 모델링을 실시해야합니다.
- LightGBM에서 직접 모델링을 진행한 경우엔
plot_importance메서드를 통해 확인할 수 있습니다.
- LightGBM에서는 모델이 결정을 내리기까지 각 Feature로 split(분기)한 횟수를 통해 중요도를 기본적으로는 계산합니다.
- 6) 게임이론 기반 Shapely 값
- 순열(Permutation) 중요도와 비슷하게 노이즈를 주었을때의 pay-off를 측정합니다.
- 장단점
- 변수간의 상호의존성(강한상관관계, 다중공선성)에 영향을 받지 않고, 계산할 때마다 값이 달라지지 않으며, 변수 영향력의 방향성(+/-)을 확인할 수 있다는 장점이 있습니다.
- 학습결과가 아닌 원래의 데이터에의해 결정되기 때문에 이상치(outlier)에 취약하고, 계산이 오래걸린다는 단점이 있습니다.
- shap의
shap_values메서드를 사용하여 확인할 수 있습니다.
- 1) 선형 모델의 회귀계수(Coefficients)
-
각 방법들의 장단점이 뚜렷하고 계산방식도 다르기 때문에 어떠한 방법으로 머신러닝 모델의 특성중요도를 평가할지 결정할 때는 상활에 맞게 적용하는 것이 중요합니다.
마무리
- 이번 글에서는 머신러닝의 정의와 머신러닝의 다양한 모델들에 대해서 살펴보았고, 각 모델들의 평가지표와 특성중요도에 대해서 간략하게 살펴보았습니다.
- 파이썬 코드를 통한 머신러닝 전처리 및 교차검증에 대한 내용도 포함시키고자했지만 내용이 너무 방대해지고 구성이 너무 복잡해져서 포함시키지 않았습니다만, 이는 추후에 내용을 업데이트 하거나 따로 글을 작성하여 머신러닝에 대한 세부적인 내용들을 다루어보도록 하겠습니다.
- 머신러닝 모델과 평가지표에 대해선 더 자세히 다뤄볼 수 있는 내용들이 있긴 하지만, 최대한 요점만 정리하는 방향으로 글을 작성하였고, 내용에 대한 세부적인 내용들은 추후에 좀 더 공부하여 업데이트해 나갈 예정입니다.
- 이후의 글에서는 본격적으로 시계열 데이터에 특화된 통계적 기법과 머신러닝 기법들에 대해서 다루어 보도록 하겠습니다.
- 화이팅 !!
