분산도
Keyword - 분산도, 범위, 사분위편차, 분산, 표준편차, 표준점수, 첨도
분산도 - 분포의 흩어진 정도
- 분포의 특성을 알기 위해서 중심경향값과 더불어서 고려되는 특성
- 중심경향값이 같더라도 흩어진 정도에따라 분포가 달라질수 있음
범위(Range)
- 가장 간단한 분산도
- 최고값과 최저값으로 파악
- 연속성을 위한 교정 : 범위 = 최고값의 상한계에서 최저값의 하한계를 뺀 값!
R = (H+u/2) - (L-u/2)
= (H-L) + u
H : 최고값
L : 최저값
u : 측정단위사분위 편차(Quartile deviation)
- 자료의 크기 순으로 4등분값(quartile)으로 구한 분산도
- 25%, 50%, 75% 되는 점의 값을 각각 ,,라 함
- 사분위 편차란, 값(Median)을 기준으로 계산되는 값
= - 이때 값을 사분위간 범위(IQR; Interquartile range)라 함.
- 정규분포에서는 가 성립함
분산(Variance)
- 모든 자료의 요소를 각각 고려하여 흩어진 정도를 나타낸 것
- 많은 통계에서 평균과 더불어 가장 많이 쓰이는 통계값
- 편차(Deviation)이란 각 점수가 평균에서 떨어진 정도를 뜻함
- 편차가 음수인 경우를 보완하기 위해 편차를 제곱 한 후 모두 더하여 총 사례수로 나눈값을 분산(Variance)라 함
- 모집단에서는 , 표본에서는 로 표기함
표준편차(Standard deviation)
- 분산에 제곱근을 취한 값
- 모수치는 σ로 표시하며, 표본통계치는 로 표기함
- (참고) 추리통계에서 표본의 분산 및 표준편차를 계산할때는 n 대신 n-1로 나눈 불편파추정치를 사용함
- 분산과 표준편차는 분포의 흩어진 정도를 가장 정확하게 설명해주는 통계값임!
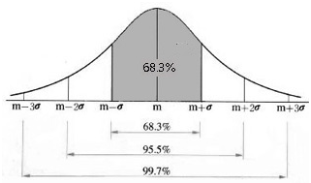
표준점수(Standard score)
- 얻어진 점수의 상대적 위치를 알려주는 점수
- Z점수, T점수 등이 있음!
- Z점수란, 편차를 표준편차로 나눈 값- 이때 점수의 평균은 0, 표준편차는 1인 정규분포라 가정함
- T점수란, 평균점수를 50, 표준편차를 10으로하는 표준 점수
- 이때 점수의 평균은 0, 표준편차는 1인 정규분포라 가정함
첨도(Kurtosis)
- 분포의 봉(꼭대기)의 뾰족한 정도를 나타냄
- 정규분포의 첨도는 0
- 정규분포보다 뾰족하면 급첨(leptokurtic), 첨도 +값(양수)
- 정규분포보다 평평하면 평성(platykurtic), 첨도 -값(음수)

일 때문에 포스팅은 잠시 쉬어요 ㅠ 바쁘다 바빠 모두들 화이팅! // Machine Learning (AI) Engineer & BackEnd Engineer (Entry)