모집단과 표본
Keyword - 모집단분포, 표본분포, 표집분포, 중심극한정리, 편파추정치, 불편파추정치, 자유도
모집단분포,표본분포
- 모집단의 분포(population distribution)
- 일반적으로 평균이 μ, 표준편차가 σ인 정규분포를 나타냄
Population∼N(μ,σ2)
- 모수치 (Parameter)
- 평균 : μ
- 분산 : σ2
- 표준편차 : σ
- 사례수 : N
- 모비율 : p
- 표본집단의 분포(sample distribution)
- 일반적으로 평균이 Xˉ, 표준편차가 s인 분포를 나타냄
- 표본분포는 항상 정규분포가 되는것은 아님!
- 표본크기 n이 커질수록 정규분포에 가까워질순 있음
- 통계치 (statistics), 추정치(estimate)
- 평균 : Xˉ or m
- 분산 : s2
- 표준편차 : s
- 사례수 : n
- 표본비율 : p^
표집분포(sampling distribution)
- 가설검정을 위해 필요한 가상의 분포, 이론적분포라고도 불림
- 표집분포란, 표본의 크기가 n인 표본을 반복추출한 후, 표본들의 평균으로 그린 분포
- 즉, 표본평균[Xˉ1,Xˉ2⋯Xˉk−1,XˉK], 혹은 표본표준편차[s1,s2⋯sk−1,sk]의 분포
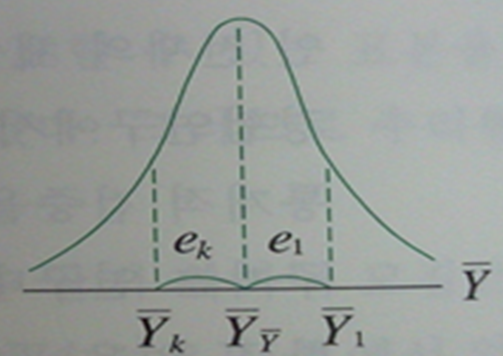
- 표집오차(표본오차)(sampling error) : 표본의 평균과 모집단의 평균의 차이
ek=Yˉk−μY
- 표준오차(standard error) : 표집오차들의 표준편차, 즉 표집분포의 표준편차
σe=σYˉ
- (증명)
σe=KΣ(ek−eˉ)2
eˉ=0 이므로
σe=KΣek2=KΣ(Yˉk−μY)2=σYˉ
중심극한정리(Central Limit Theorem)
- 큰수의 법칙(law of large number) : 표본집단의 크기(n)이 커질수록 표집분포의 통계값이 모집단의 모수에 가까워진다. 즉, 예측에대한 정확도가 오른다.
- 중심극한정리(central limit theorem) :
- 표집분포의 평균은 모집단의 평균과 같고
- 표집분포의 분산은 모집단의 분산을 표본의 크기로 나눈 것과 같으며
- 표본크기(n)가 충분히 클때(일반적으로 n>30) 모집단의 분포와 관계없이 표본평균의 분포는 정규분포가 된다.
xˉxˉ=μx
σxˉ2=σe2=nσx2
σxˉ=nσx
xˉ∼N(μx,nσx2)
- (참고)증명
- 평균
xˉxˉ=E(xˉ)=E(Σxi/n)
=E[nx1+x2+⋯+xn]=n1E[x1+x2+⋯+xn]
=n1⋅[E(x1)+E(x2)+⋯+E(xn)]
=n1⋅n⋅μx=μx
- 분산
σxˉ2=Var(xˉ)=Var(nx1+x2+⋯+xn)
=n21⋅Var(x1+x2+⋯+xn)
=n21⋅[Var(x1)+Var(x2)+⋯+Var(xn)]
=n21⋅n⋅σx2=nσx2
편파추정치(Biased estimates)
-
편파추정치(biased estimates) : 모집단을 추정하기 위해 계산된 표본의 분산 sy2의 기댓값은 모집단의 분산 σy2보다 작은 값을 추정하게 되는데, 이를 모집단 분산의 편파추정치라 한다.
-
증명과정
-
E(sy2)
- E(sy2)
=E(nΣ(yi−yˉ)2)
=E(nΣ(yi2−2Yiyˉ+yˉ2))
=E(nΣyi2−2nyˉ2+nyˉ2)
=E(nΣyi2)−E(yˉ2)
- 따라서 E(nΣyi2)과 E(yˉ2) 를 알아야함
-
E(nΣyi2)
-
σy2=NΣ(yi−μy)2
=NΣyi2−μy2=E(yi2)−μy2
따라서 E(yi2)=σy2+μy2
-
E(nΣyi2)=n1⋅ΣE(yi2)
=n1⋅Σ(σy2+μy2)
(σy와 μy는 상수이므로)
=n1⋅n(σy2+μy2)
-
E(nΣyi2)=σy2+μy2
-
E(yˉ2)
- σyˉ2=E(yˉ2)−[E(yˉ)]2
(중심극한정리에의해 E(yˉ)=μy)
=E(yˉ2)−μy2
- E(yˉ2)=σyˉ2+μy2
-
다시 E(sy2)로 대입
E(sy2)=E(nΣyi2)−E(yˉ2)
=(σy2+μy2)−(σyˉ2+μy2)
=σy2−σyˉ2
(중심극한정리에의해 σyˉ2=nσy2)
=σy2−nσy2
=σy2(1−n1)
=σy2(nn−1)
-
따라서 E(sy2)=σy2(nn−1)
-
모집단의 분산을 추정하기 위해서는 표본의 분산값인 sy2를 그대로 사용하면 안된다!
불편산추정치(Unbiased estimates)
- 정확한 모집단의 분산을 추정하기 위해선 E(sy2)으로 E(nΣ(yi−yˉ)2)을 사용하면 안되고, E(n−1Σ(yi−yˉ)2)을 사용해야함.
- 이를 분산의 불편차추정치(unbiased estimates)라 부른다.
- 편파추정치인 s2와 구분하기 위해 s′2, su2, δ2,σn−1등으로 표기하긴하지만...
일반적으로 s2이라하면 불편산추정치를 의미함.
자유도(Degree of freedom)
- 불편차추정치를 위한 표본의 분산 계산 공식의 분모 (n-1)을 자유도라 지칭함.
- 기호로는 df 또는 υ으로 표기함.
- 자유도란 통계적 추정을 할때 표본이 되는 자료 중 모집단에 대한 정보를 주는 독립적인 자료의 수를 말함. 즉, n-1값
- 예를 들어, 표본의 크기가 4인 표본에서 3개는 어떤 점수라도 가질수 있지만, 나머지 1개의 값은 편차의 합이 0이 되게 하기 위해서는 어떠한 값도 자유롭게 가지지 못하고 고정된 값을 가짐.
따라서 크기가 4인 표본의 자유도는 3이 된다.
- 또 다른 예로 4개 집단의 피험자들이 각각 30명씩 random하게 배치됐을때, 자유도는 다음과 같음.
- 전체자유도 : dftotal=(4×30)−1=119
- 집단내 자유도 : dfwithin=4×(30−1)=116
- 집단간 자유도 : dfbetween=4−1=3
