1. 13강 복습
13강에서는 다양한 unsupervised learning 방법들인 PixelRNN/CNN, VAE, GAN에 대해서 알아봤다. Fully Visible Belief Network의 일종인 PixelCNN/RNN은 tractable한 density function을 정의해 현재의 pixel들을 예측하는 방법이었고, VAE는 autoencoder의 개념을 가져와 sampling을 통해 pixel들을 얻는 방법이었다. 이때, PixelRNN/CNN과는 다르게 VAE는 latent z를 사용해 intractable한 density function을 이용한다는 차이가 있었다. GAN은 density function을 explicit 하게 정의하는 것보다 sampling할 수 있는 능력만 얻는 것에 집중했다. generator/discriminator network를 정의해 이를 가능하게 만들었다. 이번 강의에서는 Reinforcement Learning에 대해서 배운다.
2. Reinforcement Learning (RL)
Reinforcement learning(강화 학습)은 environment, agent의 상호작용을 통해 이루어진다.

어떻게 학습이 진행되는지 자세히 알아보자.
1) environment가 agent에게 state를 전달한다. ()
2) agent는 action을 취한다. ()
3) environment는 action에 대한 reward를 제공한다. ()
4) environment가 agent에게 next state를 제공한다. ()
이때 와 은 특정 시간대를 나타내는 표현이다. 는 현재 time step, 이 다음 time step 정도로 생각하면 될 것 같다. 예시를 통해 자세히 알아보자.

위의 예시는 움직이는 카트에서 폴대를 오래 세우고 있는 것이 목적인 시스템이다. 이 시스템에서의 action, state, reward를 정의해보자. state는 상태를 의미하므로 각, 각속도, 위치, x축 방향의 속도 정도로 정할 수 있을 것이다. action은 카트에 가해지는 힘을 의미하고 , reward는 각 time step마다 폴대가 제대로 서 있다면 1씩 부여하는 방식으로 정의한다. 즉, 오래 폴대가 균형을 이룰수록 reward가 커지는 것이다. 이런 식으로 원하는 방향으로 reward를 설정할 수 있다.

하나의 예시를 더 살펴보자. 일종의 게임인데, state는 현재의 pixel input들, action은 게임 플레이어가 제어할 수 있는 방향 (왼쪽, 오른쪽, 위쪽, 아래쪽)을 뜻한다. reward는 게임 점수를 기준으로 한다.
이런 식으로 시스템의 state, action, reward 등을 정하는 것이다. 그런데 이를 수학적으로 모델링 해야 RL 문제를 정확히 해결할 수 있을 것이다.
2. Markov Decision Process (MLP)
앞으로 소개할 알고리즘들이 다 MLP이지만, 일단 MLP의 개념부터 알아보자. RL 문제를 수학적으로 공식화 한 것이 MLP이다. Markov property라는 용어가 하나 더 있는데, 이는 현재 state로부터 바로 다음 time step의 state는 현재 state의 영향만 받는 상태를 뜻한다. MDP는 이러한 Markov property를 만족한다.
사진 설명을 입력하세요.
위의 사진에 각종 문자이 나온다. S,A는 위에서 나온 state와 action이다.
i) R: (s,a) pair가 주어졌을 때 reward의 분포를 의미한다.
ii) P: transition probability를 의미한다. 즉, (s,a) pair가 주어졌을 때 다음 state에 대한 분포이다.
iii) discount factor: 과거, 현재, 미래의 reward 중에 무엇에 더 집중할지에 대한 factor이다. 우리는 최대한 빨리 많은 reward를 얻는 것이 좋기 때문에, 감마 값이 작을수록 과거의 reward에 중요성을 부여하는 것이고, 1에 가까울수록 모든 reward에 중요성을 다 부여하는 것이다.
이제 MLP에 대해 자세히 알아보자.

i) 일때, environment는 state를 sampling을 통해 초기화한다.()
ii) 그리고 terminal state가 있을 때까지 loop를 돈다.
iii) agent는 action을 선택하고, environment는 R 분포에서 가 주어졌을 때의 reward를 sampling한다.
iv) 그리고, environment는 가 주어졌을 때의 next state도 고른다.
v) agent는 environment가 뽑은 reward와 next state를 받는다.
iii)~v)가 loop 안에서 반복되는 내용이다.
위의 사진을 보면 policy라는 개념이 등장한다. policy 는 state와 action을 mapping해 놓은 공식이다. policy를 통해 우리는 각 state에 맞는 action을 정할 수 있게 되는 것이다. 각 시스템마다 cumulative discounted reward를 최대화해주는 최적의 policy 를 찾는 것이 목표이다. 간단한 예시를 통해 개념을 더 정확히 이해해보자.
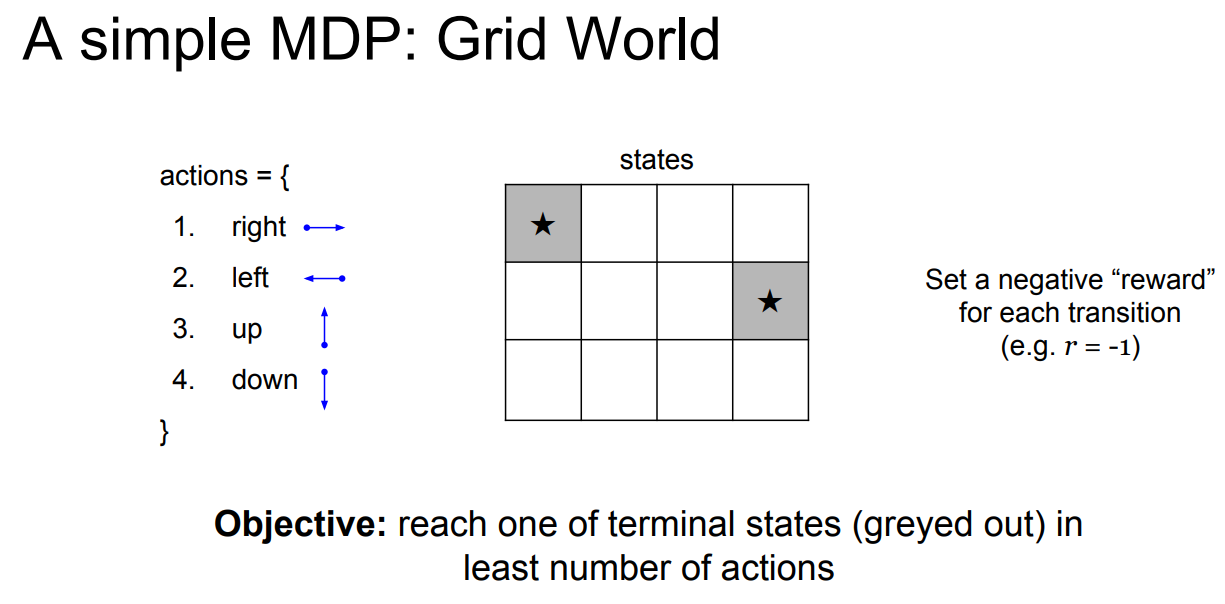
이 게임에서의 목표는 가장 짧은 거리로 회색 블럭에 가는 것이다. action은 상하좌우로의 움직임이 될 것이고, reward는 한 번 움직일 때마다 -1로 주어질 것이다. -1인 이유는 거리가 짧을수록 좋기 때문이다. 이 경우, 최적의 policy는 아래 사진과 같이 나타난다.
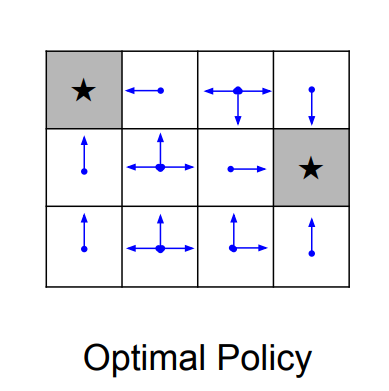
이런 식으로 optimal policy를 찾는다. 그런데 이것보다 훨씬 복잡한 문제들의 경우 policy를 찾을 때 initial state, transition probability 등 random하게 주어지는 값들의 영향이 커질 것이다. 이런 경우 어떻게 해결하는 것이 좋을까? expected reward의 합을 최대화 하는 것이 우리가 할 수 있는 최선이다.
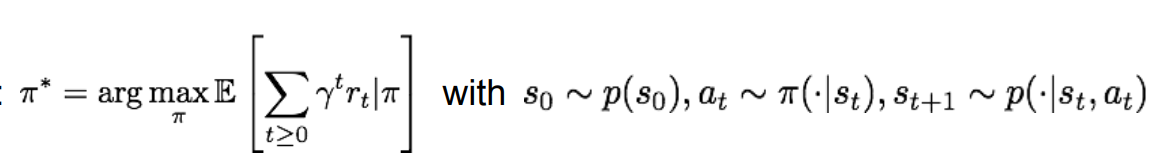
3. Value function & Q-value function
앞서 이야기한 optimal policy를 찾는 과정에서 value function과 Q-value function을 이용한다. 먼저 두 function의 개념에 대해 알아보자.
1) value function
state 로부터 policy를 따랐을 때의 expected cumulative reward를 계산한 값이다. 라고 표현한다.
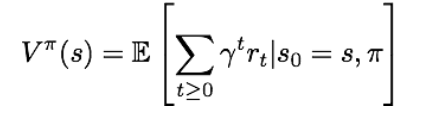
2) Q-value function
state 에서 action 를 수행하고 나서 policy를 따라가면 얻을 수 있는 expected cumulative reward를 계산한 값이다. 라고 표현한다.
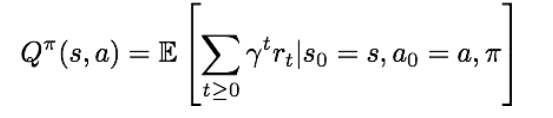
Value function을 통해 우리는 state가 얼마나 좋은지 평가할 수 있고, 마찬가지로 Q-value function을 통해 state-action pair가 얼마나 좋은지 평가할 수 있다.
3) Bellman Equation
optimal Q-value function, 즉 는 pair가 주어졌을 때 얻을 수 있는 expected cumulative reward의 최댓값이다.
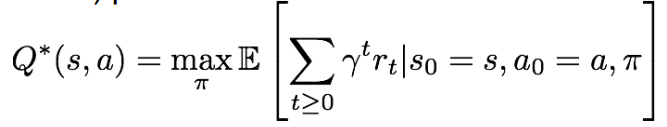
이때 는 bellman equation을 만족한다고 한다. Bellman Equation에 관해서는 나중에 정리해서 따로 올리겠다.
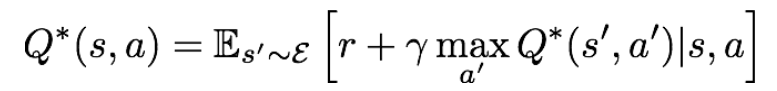
이 식에 대한 intuition을 살펴볼 필요가 있을 것 같다. 만약 다음 time step의 state-action value들인 이 주어져 있다면, 최적의 전략은 reward 에 을 더한 값을 최대화하는 action을 취하는 것이다. 즉, 현재 state의 reward와 미래에 할 action에 대한 reward를 더한 값을 최대화하는 것이다.
Optimal policy는 각 state에서 reward를 최대화하는 action을 취하는 것이고, 이는 가 정해준다. optimal policy를 구해보자.
4. Solving for the optimal policy
1) Value Iteration algorithm
: 위에서 본 bellman equation을 iterative update에 사용하는 것이다.
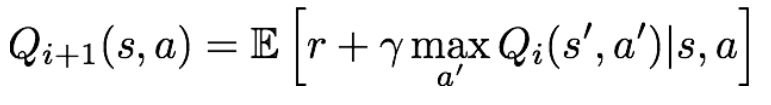
위의 식을 반복하다 보면, 는 에 수렴하게 될 것이다. 그러나 이러한 방식의 문제는 scalable하지 않다는 것이다. 일단 를 모든 pair에 대해 계산해야 된다는 것이 현실적으로 불가능하다. 예를 들어, 앞서 예시로 든 atari 게임의 경우, state가 pixel들이었기 때문에, 모든 state에 대한 를 계산하는 것으 힘들어 보인다. 그렇기 때문에 우리는 neural network와 같은 function approximator를 예측에 사용한다. 이것을 Q-learning이라고 한다.
2) Q-learning
: function approximator를 이용해서 action value function을 예측하는 것이다.
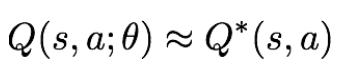
만약 function approximator가 deep neural network라면 deep Q-learning이라고 하고, 는 function parameter인 weight일 것이다. 여기서 기억해야 할 것은 bellman equation을 만족하는 Q-function을 찾아야 한다는 것이다. forward pass 부터 살펴보자.
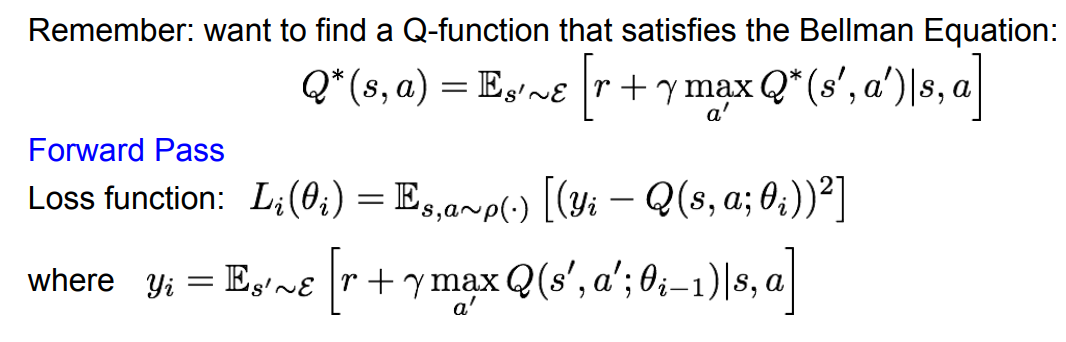
loss function의 bellman equation에 대한 error를 최소화 하는 것이 우리의 목표이다. 이때 는 와 같다.
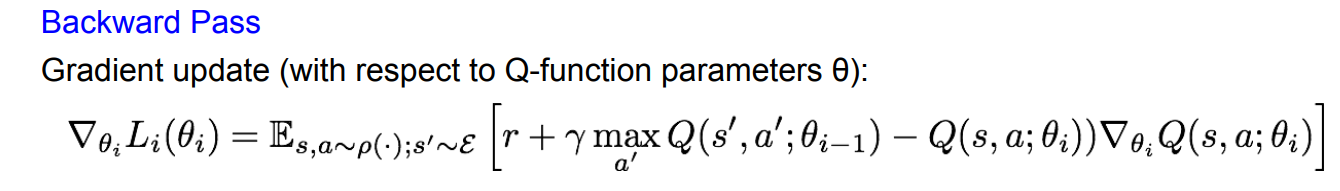
Backward pass에서 세타에 대한 미분을 통해 gradient update를 진행한다. 이 과정을 반복해서 Q-value를 target value 에 가깝게 하려는 것이다.
위에서 봤던 atari game 예시를 통해 Q-network architecture를 살펴보자.
5. Q-network Architecture
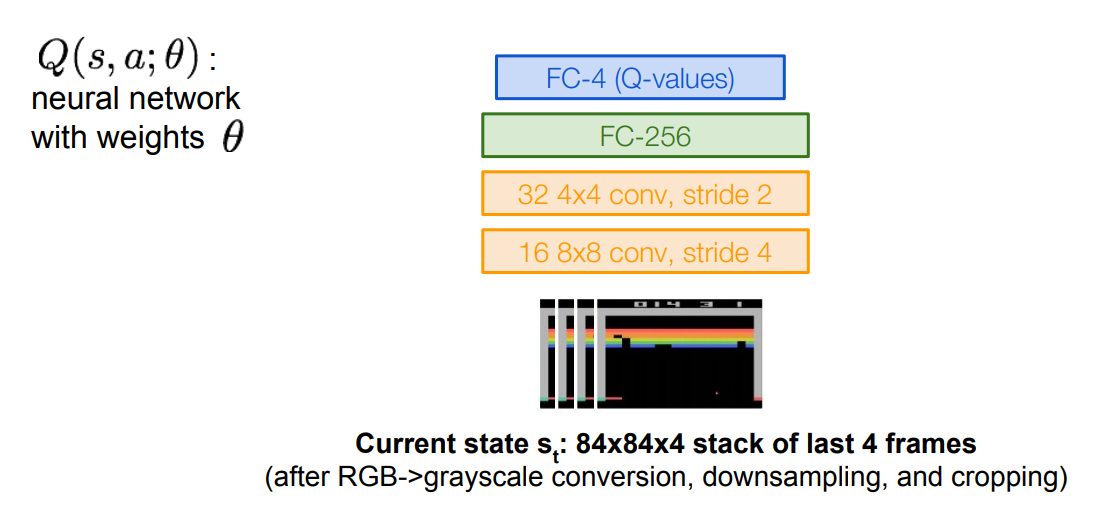
이 경우에는 action의 개수가 output dimension이 된다. 여기선 4d로 설정했기 때문에 FC-4의 output layer가 있는 것이다. 이 architecture를 이용하면 한 번의 feed forward pass 만으로 모든 action들의 Q-value를 계산할 수 있어 효율적이다. input은 state 이다. 는 이전 4개의 프레임만 grayscale로 바꾸는 등 전처리 과정을 거친후 Conv layer에 들어가게 된다. 마지막 FC-4는 4개의 action이 있다고 했으므로 그 output들은 각각 에 해당하는 값이다.
6. Training Q-network
Q-network를 훈련시킬 때는 Experience Replay라는 개념을 이용한다. 이 방법은 연속적인 sample을 담은 batch 단위로 학습하는 것의 문제점을 극복하기 위해 고안되었다. batch 단위의 학습을 할 경우, 크게 2개의 문제점이 있다.
i) sample들이 correlated 되어 있어 학습의 효율성이 떨어진다. 여기서 correlation이 높다는 것은 이미지 픽셀간의 유사도가 높다는 것이다.
ii) 현재 Q-network parameter들이 다음 training sample을 결정한다. 이게 왜 문제인지 의문이 들 수 있다. 예를 들며 설명하겠다. 만약 현재 state에서 최적의 action이 왼쪽으로 이동하는 것이라면, 앞으로의 training sample들은 왼쪽으로 이동했을 때의 sample들로만 국한될 것이다. 이렇게 action이 미리 정해지기 때문에 제대로 된 피드백을 얻기 힘들 것이다.
이러한 문제점들을 experience replay라는 방법을 통해 해결한다. 이 방법은 replay memory를 계속 업데이트해서 기억해놓는다.

얻은 replay memory를 training에 이용한다. 이전에 consecutive sample들을 통해 training을 진행한 것과 다르게, replay memory에서 random minibatch들을 만들어서 훈련에 이용한다. 이렇게 하면 효율성이 이전 방법보다 올라가게 된다. 이제 자세한 알고리즘을 의사코드를 통해 알아보자.

i) replay memory와 Q-network를 초기화한다.
ii) 게임의 episode들을 플레이한다. (iii)~vii)의 내용은 for i,M 문의 내용)
iii) 각 episode의 시작마다 state를 초기화해준다.
iv) 각 time step마다 작은 probability를 가진 random한 action을 고르거나 현재의 policy를 통해 최적의 action을 고른다. (v)~ vii)는 for t=1,T 반복문 내용)
v) action을 취하고, reward와 next state를 관찰한다.
vi) transition 내용을 replay memory에 담는다.
vii) experience replay: replay memory로부터 random한 minibatch를 sampling해서 gradient descent를 진행한다.
7. Policy Gradient
위의 Q-learning은 복잡하다는 단점이 있다. Policy Gradient는 이를 해결한 방법이다. 예시를 들어서 살펴보자.

로봇이 물체를 잡는 경우를 생각해보자. 움직임의 복잡도가 굉장히 높기 때문에 그 모든 state,action pair를 배우기에는 어려움이 있을 것이다. 이런 문제 때문에 policy를 직접 배울 수는 없을까?' 라는 접근을 한 것이다. 그리고 배운 여러 개의 policy들 중에서 최고의 policy를 뽑을 수 있다면, 좋은 해결책이 될 것이다. 먼저 policy를 아래와 정의하자.

는 policy의 value를 정의한다. 식을 보면 cummulative discounted reward의 기댓값을 의미하는 것을 알 수 있다. 여기서의 목표는 이 value를 최대화하는 (optimal policy parameter)를 찾는 것이다. 이것은 이전에도 소개되었듯이, gradient ascent를 통해 얻을 수 있다.
8. REINFORCE Algorithm
위에서 말한 과정을 자세히 살펴보자. 수학 기호 는 trajector(경로)를 뜻한다. 은 reward, 는 policy에서 sampling한 경로의 확률을 뜻한다.
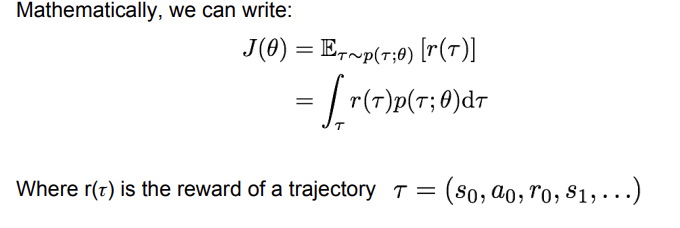
위의 식으로 정의하면, 는 Expected reward가 되는 것이다. gradient ascent를 진행하기 위해 이를 에 대해 미분하자.
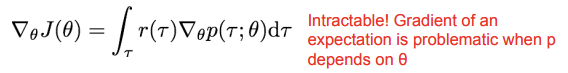
이때, 가 에 의존적이기 때문에 계산하기 복잡하다는 문제가 있다. 분자 분모에 똑같은 값을 곱해서 식을 변형하자.

를 미분하면 를 얻을 수 있다. 그렇기 때문에 를 이용해 를 표현할 수 있다.
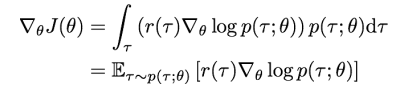
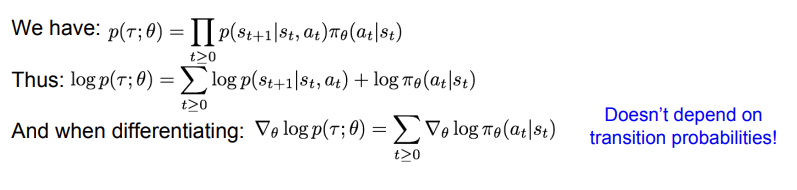
그 결과 위의 사진과 같이 를 얻을 수 있다. 위의 값들을 보면, transition probability의 영향을 받지 않는다는 것을 알 수 있다. 따라서, 우리는 를 아래의 식으로 추정할 수 있다. 이를 gradient estimator라고도 한다.
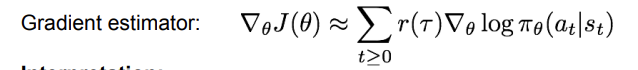
이 식은 이 높으면 사용한 action의 확률을 높이고, 낮으면 사용한 action의 확률을 낮춘다는 intuition을 가진다. trajectory에 대한 reward가 높으면, gradient가 가 좋으면 지나온 모든 action의 확률을 높이는게 무식한 방식으로 보일 수 있지만, 결과적으로는 average out 된다고 한다. 정확히 왜 그런지는 잘 모르겠다. 그런데, 이 식은 high variance 문제가 있다고 한다. 어떤 action이 좋은 trajectory를 만들었는지 알아내기 힘들다는 뜻이다. 그렇기 때문에 variance reduction을 진행한다. reduction을 위해서 3가지 정도의 아이디어가 있다.
9. Variance Reduction
1) 현재 state 기준, 미래의 cumulative reward만 고려해서 action의 확률을 높여주는 방법
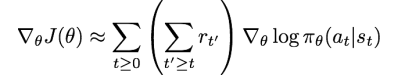
첫 번째 방법은 전체의 reward를 생각하는 것이 아니고, 현재 time step 기준으로 미래의 reward만을 고려해서 action의 확률을 조정하는 방법이다. 그렇기 때문에 식에서도 t이상일 때에만의 cumulative reward를 반영한다.
2) discount factor를 이용해 delayed effect를 무시하는 방법
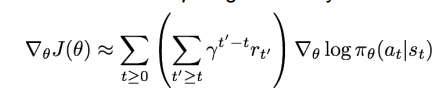
두 번째 방법은 지연된 reward에 대한 discount를 적용하는 방식이다. 그런데 이러한 방법은 문제가 존재한다. trajectory의 raw value는 사실상 그렇게 큰 의미가 있진 않다. 예를 들어, 만약 reward가 계속 양수라면, action의 확률은 계속 올라갈 것이다. 그런데 사실 중요한 것은, 우리가 기대한 reward보다 계산한 reward가 높은지 낮은지이다. 우리가 최소한으로 원하는 값 이상의 reward를 얻고 싶은 것이다. 이런 생각으로 고안된 것이 baseline이다.
3) baseline
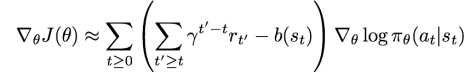
baseline을 적용한 의 식은 위와 같다. baseline 식 는 정하기 나름인데, 일단 간단한 방식의 baseline 부터 살펴보자. 이 식은 지금까지 경험한 모든 trajectory reward의 moving average를 계산한다. 이러한 variance reduction 테크닉을 쓰는 방식을 vanilla REINFORCE라고한다.
위의 방식도 좋지만, 그것보다 더 좋은 방식을 찾아보자. (특정 state로부터의 expected reward)< (특정 state에서 action을 통해 얻은 reward) 인 경우 action의 확률을 높이는 방법도 좋은 접근이 될 수 있다. 이러한 접근을 Q-function과 Value function에 적용해 볼 수 있다.
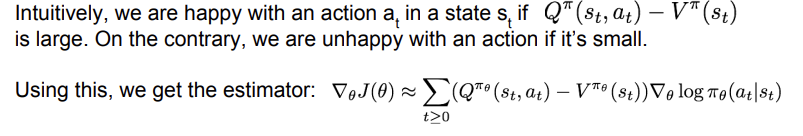
위의 사진의 식과 같이, Q-V 값이 크다면 좋은 action인 것이다. Q-function은 s-a pair에 대한 term이고, value function은 state에 대한 term이다. 만약 이 둘의 차이가 크다면 action이 미치는 영향이 크다고 직관적으로 이해할 수 있다. 이를 이용해 estimator 식을 새로 쓸 수 있다. r자리에 Q-V가 들어가는 것이다.
10. Actor-Critic Algorithm
위의 Q-function과 Value function을 이용하는 것은 좋은 접근으로 보인다. 그러나 우리가 식을 모른다는 문제점이 있다. 식은 actor-critic 알고리즘을 적용하면 배울 수 있다. 이는 policy와 Q-learning의 개념을 접목한 것으로, policy가 actor역을, Q-function이 critic 역을 수행한다고 비유할 수 있다. 적용 과정은 아래와 같다.

actor가 action을 취하면 critic이 이에 대한 피드백을 주는 방식이다. 이전과는 다르게 policy에 대한 만 배우면 되므로 더 효율적이다. 위에서 배웠던 Experience replay와 같은 방법도 적용할 수 있다. 또, Q-V를 advantage function(위 사진에서의 )으로 정의해서 action이 기대보다 얼마나 뛰어난지에 대한 기준을 만들기도 했다.

참고로, 한 때 유명했던 알파고도 Policy gradient를 이용한 알고리즘 중 하나이다.
11. Recurrent Attention Model (RAM)
RAM은 REINFORCE가 어떻게 실제로 적용되는지에 대한 예시이다.

예시는 많이 봤던 MNIST dataset을 이용해 Image Classification하는 문제이다. state는 이제까지 본 glimpse들이고, action은 다음에 살펴볼 glimpse의 정중앙 좌표이다. reward는 마지막에 제대로 classification이 이루어지면 1, 아니면 0으로 주어진다. 이전에는 glimpse를 특별한 policy 없이 살펴봤다면, 이제 policy를 통해 어떻게 glimpse를 살펴볼지 구조화 했다는 것에 의의가 있다. 여기에 RNN 모델을 이용해 state, action을 모델링한다.
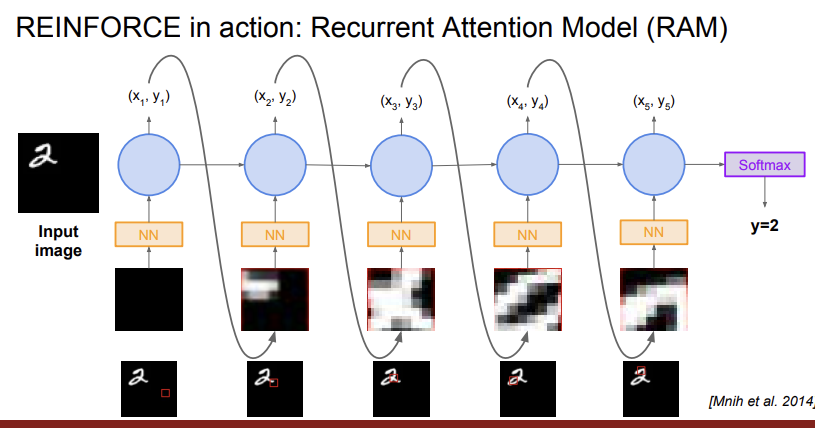
위의 과정을 살펴보면 점점 숫자에 가깝게 glimpse를 가져가며 숫자의 각 부분들을 살펴본다는 것을 알 수 있다.
12. 정리

다음 두 강의는 초빙 강의(?)라 따로 블로그를 정리하진 않을 것 같다. 그 말은! cs231n 강의 1회독이 완료 되었다는 뜻! 이제 강의 내용을 다시 복습하면서 중간에 이해되지 않았던 내용들도 깊게 파보고, 등장하는 주요 논문들도 한 번 읽어볼 생각이다. 강의에서 내주는 과제를 하기 싫음 이슈로 인해 거의 안했기 때문에 그것도 병행해보려고 한다.
강의가 막판에 가서 좀 어려워진 것 같다. 물론 내가 기초 학문에 구멍이 많아서 그렇다. 확통이나 정보 이론 관련해서 모르는 부분은 다시 한 번 정리해봐야 될 것 같다. 그래서 이후 블로그 포스팅은 아마
강의 과제 내용
부족한 기초 학문 개념 정리
딥러닝 논문 리뷰
정도가 될 것 같다.
그럼 그때까지 안녕
