이번 과제가 cs231n 과제의 마지막이다. 드디어 과제가 끝나서 기쁘다. 그래도 과제를 하며 코딩 실력이 늘긴 한 걱 같아 기쁘다. 특히 과제3은 내가 들은 2017 강의 버전이랑 다른게 꽤 있어서 해당 부분을 혼자 배워야 했다. 그래서 조금 더 어렵게 다가왔던 같다. 이번 과제는 점수를 주진 않지만, 해결할 시 extra credit이 주어지는 과제이다. 물론 난 정식으로 수업을 듣진 않기 때문에 상관없지만, 어쩄든 해결했다.
이번 과제는 LSTM을 이용해서 Image Captioning을 구현하는 것이다. 구현이 어렵진 않지만, 성능이 좋지 않다. 트랜스포머의 위력을 다시 한 번 느끼게 되었다.
1. LSTM 구조
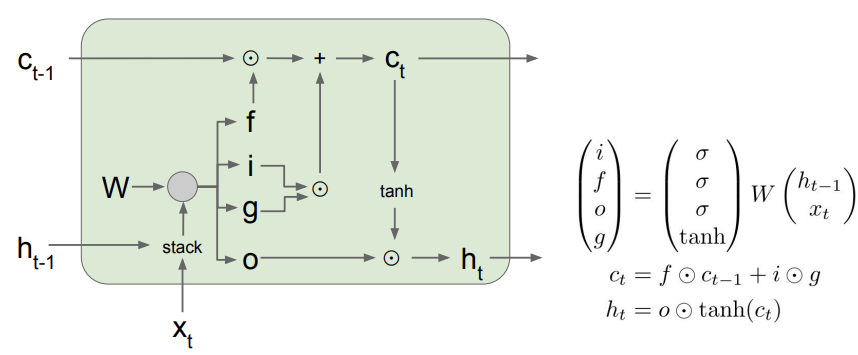
이전에 cs231n 강의 글에서도 정리했듯이, 위의 사진이 LSTM의 기본적인 구조다. 4개의 gate를 통해서 이전의 정보를 얼마나 기억할 지 정하는 것이다. sequence의 길이가 길어지면 성능이 떨어지는 RNN의 단점을 어느 정도 해결할 수 있다.

위의 gate들을 계산하는 과정을 과제에서는 조금 다르게 계산한다. a를 계산한 후, a의 0~H-1번째 열까지는 , H~2H-1열까지는 , 2H~3H-1열까지는 , 나머지 열은 에 해당한다. a를 4개의 gate로 나누어주는 것이다. 를 아래 사진과 같이 sigmoid와 에 먹여주면 위의 구조도에서 본 gate를 얻을 수 있다.

2. Implementation
1) lstm_step_backward()
def lstm_step_backward(dnext_h, dnext_c, cache):
"""Backward pass for a single timestep of an LSTM.
Inputs:
- dnext_h: Gradients of next hidden state, of shape (N, H)
- dnext_c: Gradients of next cell state, of shape (N, H)
- cache: Values from the forward pass
Returns a tuple of:
- dx: Gradient of input data, of shape (N, D)
- dprev_h: Gradient of previous hidden state, of shape (N, H)
- dprev_c: Gradient of previous cell state, of shape (N, H)
- dWx: Gradient of input-to-hidden weights, of shape (D, 4H)
- dWh: Gradient of hidden-to-hidden weights, of shape (H, 4H)
- db: Gradient of biases, of shape (4H,)
"""
dx, dprev_h, dprev_c, dWx, dWh, db = None, None, None, None, None, None
#############################################################################
# TODO: Implement the backward pass for a single timestep of an LSTM. #
# #
# HINT: For sigmoid and tanh you can compute local derivatives in terms of #
# the output value from the nonlinearity. #
#############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
prev_h, prev_c, next_c, i, f, o, g, x, Wx, Wh=cache
dnext_c+=dnext_h*o*(1-np.square(np.tanh(next_c))) #since h_t=o*tanh(c_t) from the forward pass, we need to add this to the gardient of c_t.
dai=dnext_c*g*i*(1-i)
daf=dnext_c*prev_c*f*(1-f)
dao=dnext_h*np.tanh(next_c)*o*(1-o)
dag=dnext_c*i*(1-np.square(g))
da=np.hstack((dai,daf,dao,dag))
dx=da.dot(Wx.T)
dprev_h=da.dot(Wh.T)
dprev_c=dnext_c*f
dWx=x.T.dot(da)
dWh=prev_h.T.dot(da)
db=da.sum(axis=0)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
return dx, dprev_h, dprev_c, dWx, dWh, db 처음 구현할 때, 함수를 실행한 후 과제에서 준 정답값과 비교했을 때, error가 너무 크게 나왔다. 여기서 내가 잘못했던 부분은 dnext_c에 추가적으로 더해주어야 할 것을 더해주지 않은 것이다. c_t는 h_t를 계산할 때도 사용되기 때문에, 여기서 얻는 gradient 값도 더해주어야 한다. 내가 이해한 LSTM의 backprop 과정은 아래와 같다.

위의 적은 gradient들은 upstream gradient를 빼놓고 적은 것이기 때문에, 코드에 적용할 때는 upstream gradient까지 곱해주어야 한다. 이를 바탕으로 lstm_forward와 lstm_backward를 구현하면 된다. RNN을 구현했던 것과 비슷하다.
내가 이번 과제에서 어려웠던 부분은 이 정도인 것 같다. RNN을 할때 구현 해놓은 코드도 어느 정도 사용하기 때문에 구현할 게 그렇게 많진 않았다. 이제 과제가 끝났으니, 최신 논문들을 많이 읽어야 할 것 같다.
내 과제 풀이:
