Hypothesis Test_AI_day06
내용
기술 통계치(Descriptive Statistics).
데이터를 의미있는 수치로 표현하고 시각화 한다.
예를 들어 평균값, 중앙값, 최소,최대 값 등등.
여러 시각화 plot 이 있다. (box-plot, violin-plot, etc)
추리 통계치(Inferential Statistics).
Population. 대상 집단을 모두 즉, 전수조사 하기에는 비용과 시간 등 resource가 많이 들어간다.
효율적으로 전체 집단의 통계치를 도출해 내기 위해 표본 집단(Sample)을 선별하여 통계를 낸다.
1. Simple Random Sampling : 무작위로 선별.
2. Systematic Sampling : 특정 규칙(순서)를 가지고 선별.
3. Stratified Random Sampling : 어떠한 기준으로 그룹을 나누고 그룹별로 선별.
4. Cluster Sampling : 어떠한 기준으로 그룹을 나누고 그룹전체를 대상으로 선별.
가설 검정
가설의 진위 여부를 확인.
표본 평균의 표준 오차 ( Standard Error of the Sample Mean )
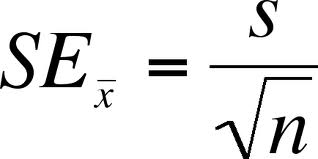
s (우측) = 표본의 표준편차 (sample standard deviation)
n = 표본의 수 (sample size)
표본의 수가 더욱 많아질수록, 추측은 더 정확해지고 (평균) 높은 신뢰도를 바탕으로 모집단에 대해 예측.
Student T-test
One Sample t-test
T-test Process
1) 귀무 가설 (Null Hypothesis)
2) 대안 가설 (Alternative Hypothesis)
3) 신뢰도를 설정 (Confidence Level)
4) P-value를 확인
5) 이후 p-value를 바탕으로 가설에 대해 결론을 내림
(tail / direction)
One-side test : 크다. 작다. 비교하려는 대상의 평균값. 가설의 평균값.
Two-side test : 같다. 다르다. 비교하려는 대상의 평균값. 가설의 평균값.
Two Sample T-test : 두 개의 샘플을 대상으로 가설을 증명한다.
사용한 코드
pd.read_table(data) : text 파일을 불러온다.
df.replace(to_replace=r',', value='', regex=True) : 데이터프레임의 모든 열에서 해당하는 문자를 바꿔준다.
df.iloc[0] : []안에 있는 숫자는 행을 가르킨다. 행을 선택한다.
df.apply(pd.to_numeric, errors='ignore') : object를 숫자로 바꿔준다. errors 가 나면 무시한다.
df.loc[:,['자치구','이팝나무']] : :, 표시는 열을 뜻한다. []은 리스트이다. 해당 열을 선택한다.
from scipy import stats : 테스트를 진행하기 위해 라이브러리를 불러온다.
stats.ttest_1samp(df, 400) : df 이름을 가진 데이터프레임에 t-test 를 하나의 샘플을 대상으로 진행한다. ()안 숫자는 증명하려는 평균값을 의미한다.
.astype(int) : ()안의 형식으로 해당 열의 type을 바꿔준다.
stats.ttest_ind(df1,df2) : 두개의 샘플로 t-test를 진행한다.
stats.ttest_ind(df1,df2, alternative = 'less') : alternative parameter 로 one or two- side test 를 진행할 수 있다.
'less' = df1 < df2
'greater' = df1 > df2
Reflection
많은 데이터를 효율적으로 다루기 위해 sampling 을 하여 여러가지 의미있는 통계를 도출해 낼 수 있다.
p-value 값은 가설의 힘을 나타내는 것과 같다. 그렇기 때문에 가설이 맞을 수 있는 힘을 이야기 하는 것이지 맞다, 틀리다 라고 정의 할 수는 없다. 그 이유는 오차 범위, sampling 등등 여러가지 요인으로 통계가 다르게 나올 수 있고 무엇보다 전수조사를 시행하는 것이 아니기 때문이다.
