Azure AI Search에서 제공하는 검색 방식으로, 전통적인 키워드 검색과 시맨틱 검색(의미 기반 검색)을 결합한 방식이다.
HybridSearch 구성 요소
아래 3가지 검색 방식을 단일 검색 요청에 조합한다.
이때 RRF(Reciprocal Rank Fusion) 알고리즘이 각 방식에서 도출된 결과를 병합하고 순위를 지정한다.
1. 전체 텍스트 검색: 키워드 매칭을 통한 전통적인 검색 방식(QueryType.FULL)
- BM25(Best Matching 25) 랭킹 알고리즘을 사용하여 텍스트 필드 내 키워드 출현 빈도, 희소성, 문서 길이 등을 고려해 관련성 점수를 계산
- 특징:
- 형태소 분석, 동의어 매핑, 언어별 텍스트 분석기 지원
- 불리언 연산자(AND, OR, NOT), 와일드카드, 퍼지 검색 지원
- 필터링, 패싯, 정렬 등 전통적인 검색 기능과 통합
- 예시:
- '맛있는 초코 쿠키 레시피' 검색시 관련 단어가 많이 포함된 문서를 찾음
- '쿠키'가 제목에 있으면 높은 점수, 본문에 여러번 나오면 중간 점수, 한 번만 언급되면 낮은 점수를 부여
- '초코칩 쿠키 만드는 방법', '크리스마스 쿠키 레시피' 같은 문서가 검색 결과로 나옴
- '저당 디저트 만들기'와 같이 쿠키나 초코란 단어가 없으면 검색되지 않음
2. 벡터 검색: 텍스트를 벡터로 변환하여 의미적 유사성을 찾는 방식(임베딩 벡터 기반)
- 텍스트의 의미를 숫자 배열(벡터)로 변환하고, 이들 간의 '거리'나 '방향의 유사성'을 계산해서 AI가 의미상 가까운 문서를 찾음
- 특징:
- 키워드가 정확히 일치하지 않아도 의미적으로 유사한 컨텐츠 검색 가능
- 벡터 필드는 텍스트, 이미지, 오디오 등 다양한 데이터 타입의 임베딩 저장 가능
- 예시:
- '자동차 구매 방법'으로 검색했을 때, 정확하게 이 단어가 없어도 '새 차 살 때 꿀팁'같은 의미적으로 관련된 문서를 찾음
3. 시맨틱 랭킹: 검색 결과의 의미론적 관련성을 평가하여 순위를 매기는 방식
- 딥러닝 기반 언어 모델을 활용하여 쿼리와 문서 간의 의미적 관련성 평가
- 단순 키워드 매칭을 넘어 문맥과 의도를 고려한 순위 결정
- 특징:
- 자연어 처리 기반으로 사용자 의도를 더 정확히 파악
- 기본 BM25 결과 집합을 재순위화하여 관련성 높은 결과를 상위로 배치
- 예시:
- '감기에 좋은 음식'을 검색했을 때
- 일반 순위: 단순히 위 단어들이 많이 포함된 문서
- 시맨틱 순위: '면역력 강화에 도움되는 음식', '감기 증상 완화를 위한 차 레시피'등 실제 도움이 될 정보가 상위에 배치됨
벡터 검색과 시맨틱 랭킹의 차이
시맨틱 랭킹은 전체 텍스트 검색을 아래로 내리고 벡터 검색을 위로 올리는건가?
- 벡터 검색: 쿼리와 의미적으로 유사한 문서를 찾는 것
- 시맨틱 랭킹: 이미 찾은 문서들 중에서 사용자 의도에 가장 적합한 문서를 상위로 배치
즉, 시맨틱 랭킹은 단순히 벡터 검색을 위로 올리는게 아니라 검색된 모든 결과에 대해 사용자의 의도와 유용성을 가지고 재평가하는 과정이다.
하이브리드 검색은 각자의 강점을 활용한다.
1. 전체 텍스트 검색으로 관련 키워드가 포함된 문서를 찾고(BM25 알고리즘 사용)
2. 벡터 검색으로 의미적으로 유사한 문서를 찾고(HNSW, eKNN 알고리즘 사용)
3. 찾은 문서들 중 사용자 의도에 가장 적합한 것을 상위로 정렬! (딥러닝 언어 모델 사용)
그리고 마지막으로 RRF 알고리즘을 사용해 결과 병합..!
HybridSearch의 장점
- 정확도 향상: 키워드 매칭 + 의미 기반 매칭으로 더 관련성 높은 결과를 제공
- 시맨틱 이해:동의어, 관련 개념, 맥락 등을 이해하여 사용자 의도에 더 가까운 검색이 가능
- 다양한 쿼리 처리
- 키워드 중심 쿼리 예) 코틀린 함수형 프로그래밍
- 자연어 쿼리 예)코틀린에서 함수형 프로그래밍을 어떻게 구현해?
- 복합 쿼리: 사용자가 어떤 방식으로 질문하든 관련성 높은 결과 제공 가능
- 예시: 한국에서 판매하는 30만원 미만의 방수 기능이 있는 블루투스 이어폰
- 지역 필터: 한국에서 판매하는
- 가격 범위 필터: 30만원 미만의
- 기능 필터: 방수 기능이 있는
- 제품 카테고리: 블루투스 이어폰
HybridSearch 구현 워크플로
0. Azure AI Search 서비스 생성
Azure Portal > AI Search > Create
- Project Details
- Subsctiption 설정: 비용이 청구될 구독 계정
- Resources group: Azure 리소스를 관리할 논리적 컨테이너
- 리소스란? Azure에서 생성하는 모든 서비스나 자원을 의미
예) Azure AI Search 서비스, 가상 머신, DB, 스토리지 계정...
- 리소스란? Azure에서 생성하는 모든 서비스나 자원을 의미
- Instance Details
- Service name: 전역적으로 고유한 서비스 이름 (엔드포인트 URL의 일부가 됨)
- Location: AI Search 서비스를 호스팅할 지역
- Pricing tier: 서비스 레벨과 비용 결정
1. 인덱스 생성
Azure Portal > AI Search > Select service > Add index
- Index name: 인덱스의 고유 이름. API 호출에서 사용됨
- Encryption: 인덱스 데이터를 암호화하는 방법. 기본적으로 Microsoft-managed keys가 선택되어 있음.
- Field
- Retrievable: 검색 결과에 필드 포함 여부(기본값 true)
- Filterable: 필드 기준으로 필터링 가능 여부
- Sortable: 필드 기준으로 정렬 가능 여부
- Facetable: 필드에 대한 패싯 탐색 가능 여부
- Searchable: 필드의 콘텐츠 검색 허용 여부
- Analyzer: 검색 가능한 필드에 대해 사용할 텍스트 분석기 지정
- Standard: 기본 분석기로 일반적인 텍스트 처리를 수행
- Language: 특정 언어에 최적화된 분석기
- Pattern: 정규식 패턴을 기반으로 토큰화 수행
- Custom: 토크나이저, 토큰 필터, 문자 필터를 조합하여 맞춤형 분석기 제작
- Dimension: 벡터 필드의 경우 벡터 차원 지정
인덱스 필드 구조를 설계할때 id, content, metadata는 필수 필드이다. 하이브리드 검색을 위해서는 벡터 필드도 설정해야한다.
패싯 탐색
검색 결과를 효과적으로 필터링하고 탐색할 수 있도록 돕는 기능이다.
- 검색 결과를 여러 카테고리(패싯)로 그룹화하여 보여준다.
- 사용자가 검색 결과를 세분화하고 정제할 수 있는 필터 메커니즘을 제공한다.
- 검색 결과에 대한 계층적인 탐색과 드릴다운(사용자가 점차 더 세부적인 정보로 이동할수 있는 탐색 방식)을 가능하게 한다.
- 예) '컴퓨터' 카테고리 선택 > '노트북' 유형 선택 > 'LG' 브랜드 선택 > '14인치' 화면 크기 선택 :: 이런 방식으로 단계별로 검색 결과를 좁혀나가는 기능
2. 시맨틱 구성 설정
Azure Portal > AI Search > Select Service - Search management > Indexes > Index - Semantic configurations
시맨틱 구성은 인덱스별로 생성해줘야 한다. 각 인덱스는 서로 다른 필드 구조를 가질 수 있고, 같은 이름의 필드라도 인덱스마다 의미적 역할이 다를 수 있고, 각 인덱스의 데이터 특성에 맞게 최적의 시맨틱 검색 설정이 다를 수 있기 때문이다.
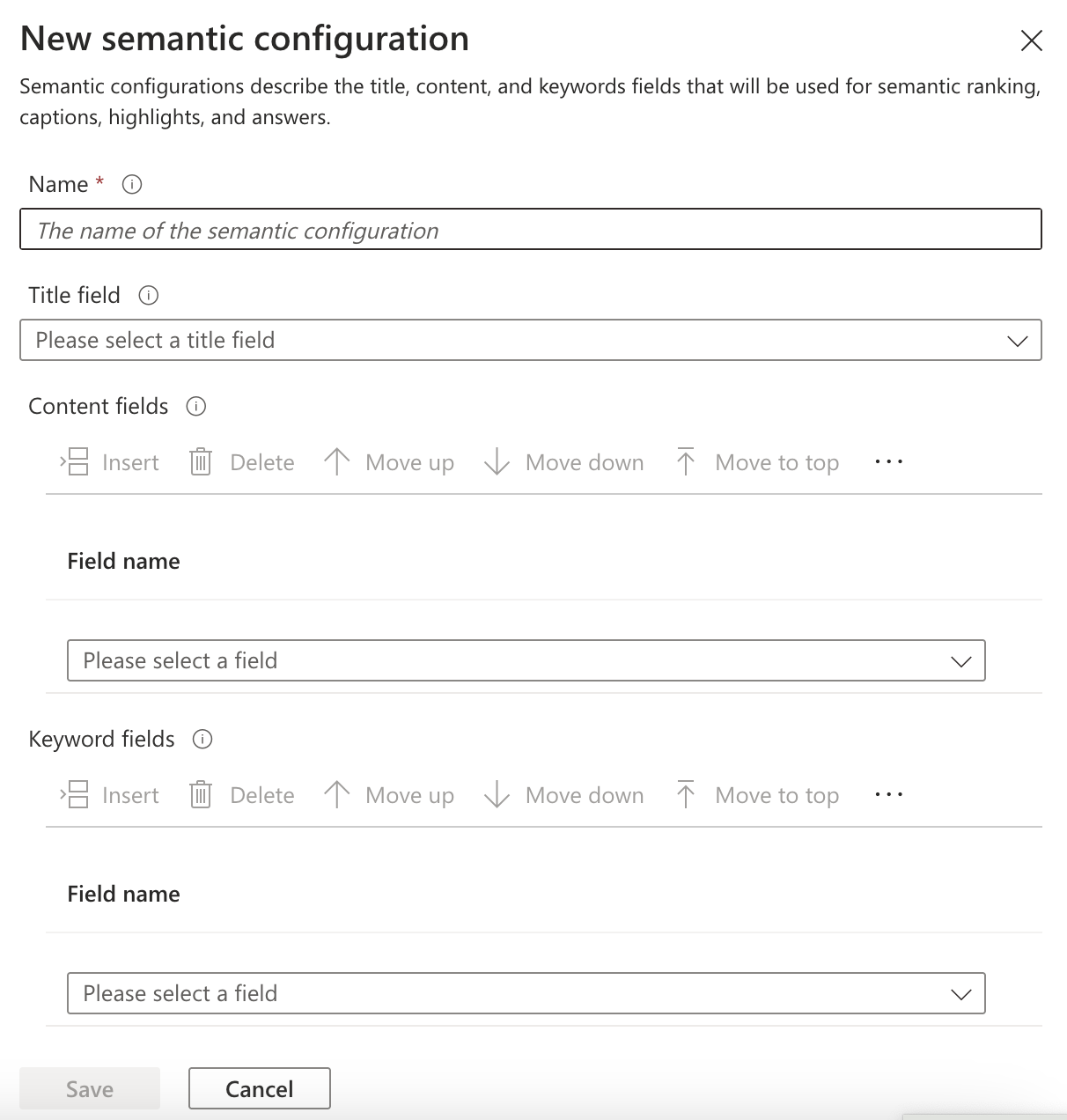
- Title Field
- 문서의 본문 내용을 담음
- 검색 결과 랭킹에 큰 영향을 미침
- 각 시맨틱 구성에서 하나의 필드만 제목 필드로 지정
- 예) 제품명, 문서 제목
- Content Fields
- 문서의 본문 내용을 담음
- 시맨틱 검색 알고리즘이 주로 분석하는 텍스트 소스
- 여러 필드를 콘텐츠 필드로 지정 가능, 이 필드들의 내용을 기반으로 의미적 유사성을 계산함
- 예) 제품 설명, 기사 본문
- Keyword Fields
- 문서의 핵심 키워드나 태그를 포함하는 필드
- 검색 관련성을 높이는 보조적 역할
- 짧은 단어나 구문으로 구성, 시맨틱 검색의 정확도 향상에 도움
- 예) 태그, 카테고리, 분류 키워드
3. 데이터 수집
외부 API를 연결해서 데이터를 가져오고, Azure AI Search 인덱스에 맞게 변환 후 벡터 임베딩을 생성해 인덱스에 업로드한다!
4. 하이브리드 검색 구현
/**
* 하이브리드 검색 수행 - 키워드, 시맨틱, 벡터 검색 결합
*/
fun searchByHybrid(query: String, limit: Int = 50): List<SearchDocument> {
if (query.isBlank()) return emptyList()
// 쿼리 텍스트의 임베딩 생성
val embedding = generateEmbedding(query)
// 벡터 쿼리 설정
val vectorQuery = VectorizedQuery(embedding.toFloatArray()) // 벡터 쿼리 생성
.setKNearestNeighborsCount(limit) // 벡터 공간에서 가장 근접한 Limit개 항목 찾고
.setFields("content_vector") // 벡터 표현이 저장될 필드 지정
// 시맨틱 검색 옵션 설정
val semanticOptions = SemanticSearchOptions()
.setSemanticConfigurationName("default-semantic-config")
// 하이브리드 검색 옵션 설정
val options = SearchOptions()
.setIncludeTotalCount(true)
.setTop(limit)
.setQueryType(QueryType.SEMANTIC) // 시맨틱 검색 활성화
.setSemanticSearchOptions(semanticOptions) // 시맨틱 검색 옵션 설정
.setVectorSearchOptions(VectorSearchOptions().setQueries(listOf(vectorQuery))) // 벡터 검색 활성화
.setSearchFields("title", "content", "category", "tags") // 키워드 검색 필드 지정
.setSelect("id", "title", "content", "category", "tags", "rating")
// 하이브리드 검색 실행
val results = searchClient.search(query, options, Context.NONE)
return results.map { it.document }
}검색 옵션 설정
val searchOptions = SearchOptions()
.setQueryType(QueryType.FULL)
.setSemanticSearchOptions(SemanticSearchOptions().setSemanticConfigurationName("semantic-search-config"))- setQueryType(QueryType.FULL)
- 전통적인 키워드 기반 검색(MB25) 활성화
- 검색의 '키워드 기반' 부분을 담당
- setSemanticSearchOptions()
- 시맨틱 검색 레이어 활성화
- 검색의 '의미 기반'부분을 담당
- setSemanticConfigurationName()
- 시맨틱 구성 참조해 시맨틱 검색이 수행됨
- setVectorSearchOptions()
- 벡터 검색 레이어 활성화
- 검색의 '유사도 기반' 부분을 담당
- VectorSearchOptions 객체로 구체적인 벡터 검색 매개변수 설정
- VectorizedQuery
- 벡터 검색을 위한 쿼리 정의
- setKNearestNeighborsCount(limit)
- 상위 limit 개의 가장 유사한 벡터를 검색
- setFields
- 벡터 검색을 수행할 필드 이름 지정
https://learn.microsoft.com/ko-kr/azure/search/hybrid-search-overview
