Lucene이란?
Lucene은 Apache Software Foundation에서 Java로 개발한 오픈소스 정보 검색 라이브러리이다. 핵심 기능은 문서 색인과 검색이다.
Lucene 주요 기능
1. 색인(Indexing)
문서를 분석하고 검색 가능한 형태로 변환하여 저장하는 과정
- 과정: 문서 수집 -> 텍스트 추출 -> 분석(토큰화, 필터링) -> 색인 저장
- 주요 구성 요소:
- Document: 검색의 기본 단위, 여러 Field로 구성
- Field: 이름과 값을 가진 Document의 구성 요소
- IndexWriter: 색인 생성 및 관리 담당
2. 역색인(Inverted Index)
용어가 원래 들어있던 텍스트에 용어를 매핑하는 데이터 구조
색인의 반대 개념으로, '단어' -> '문서' 매핑 구조를 가진다.
- 검색어가 포함된 문서를 빠르게 찾을 수 있다.
- 구성:
- 용어 사전: 모든 고유 단어 목록
- 포스팅 리스트: 각 단어가 등장하는 문서 ID 목록
3. 토큰화 및 분석(Tokenization & Analysis)
원문을 검색 가능한 토큰으로 분리 및 처리하는 과정
- 구성 요소
- 분석기(Analyzer): 전체 분석 과정 관리
- 토크나이저(Tokenizer): 텍스트를 개별 토큰으로 분리
- 토큰필터(TokenFilter): 토큰 변형 - 새 토큰으로 수정/삭제/추가, 필터링 등 처리
- 주요 기능:
- 소문자 변환: 토큰을 소문자로 변환
- 불용어 제거: 의미 없는 단어 제거
- 불용어는 텍스트에서 자주 등장하지만 검색이나 분석에 큰 의미가 없는 단어들을 말함
- 불용어를 제거 시 색인 크기가 크게 줄어들고, 처리할 데이터 양이 줄어 검색 속도가 개선됨
- a, an, the, is, 이, 그, 저, 으로 ,...
- 어간 추출: 파생어를 기본 형태로 변환
- running, runs, ran -> run :: 사용자가 running으로 검색해도 run이 포함된 문서를 찾을 수 있음
- 공부하다, 공부했다, 공부합니다 -> 공부하다 (또는 공부)
- 한글 형태소 분석: 복합어를 의미 단위로 분리
- '검색엔진입니다.' -> '검색' , '엔진' , '입니다' 로 분리
4. 검색(Searching)
색인에서 원하는 정보를 찾아내는 과정
- 구성 요소:
- IndexSearch: 색인에서 검색 수행
- Query: 검색 조건 표현 객체
- QueryParser: 사용자 입력을 Query 객체로 변환
5. 스코어링(Scoring)
검색 결과의 관련성 평가 및 순위 부여
- 알고리즘: TF-IDF(Term Frequency-Inverse Document Frequency)
문서 내 단어 빈도와 전체 문서에서의 희소성 고려
Lucene의 구조와 동작 과정
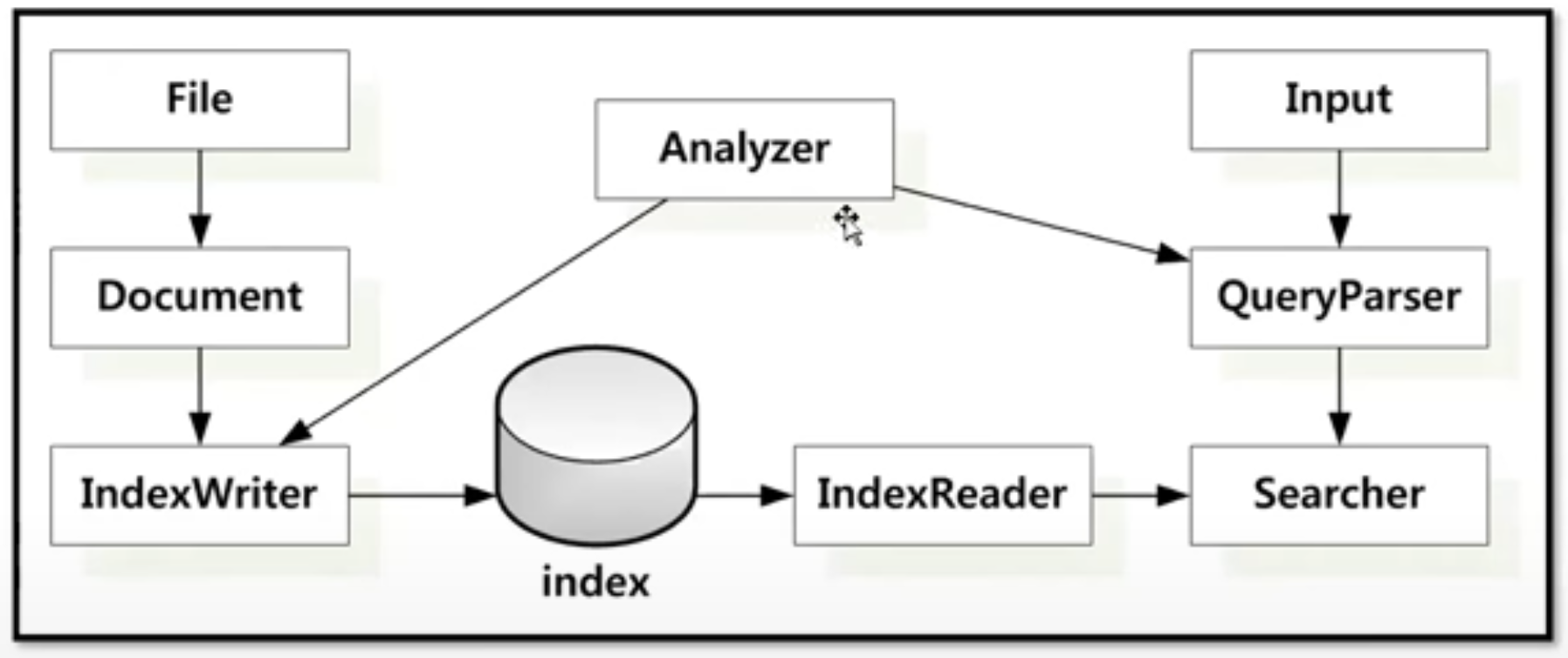
색인 과정
입력 문서로 File이 들어오면 IndexWriter가 해당 문서를 처리하여 Index DB를 생성한다.
- 문서 입력: 텍스트 파일, 웹 페이지 등 다양한 형태로 문서 입력
- Document 객체 생성: 각 문서는 Lucene의 Document 객체로 변환
- Analyzer 처리: 문서 텍스트의 토큰화 및 필터링
- IndexWriter에 의한 처리: 역색인 구조 색성, Segment 관리
- 색인 저장: 생성된 색인은 파일 시스템이나 DB에 저장
검색 과정
사용자가 Query를 입력하면 QueryParser가 해석을하고, Searcher를 통해 Index DB에서 적합한 결과를 IndexReader가 검색한다.
- 쿼리 입력: 사용자가 검색어 입력
- QueryParser 처리: 입력 문자열을 Lucene의 내부 쿼리 객체로 변환
- IndexSearcher 실행: 쿼리 객체를 받아 실제 검색을 수행
- IndexReader의 역할: 색인 파일 접근 및 정보 제공
- 스코어링 및 랭킹: 검색 결과 관련성 점수 계산 및 정렬
- 결과 반환: 정렬된 검색 결과 반환
Azure AI Search 와 Lucence의 관계
Azure AI Search는 내부적으로 Lucene을 기반으로 하며, Lucene의 검색 기능을 클라우드 서비스로 제공한다.
Azure AI Search에서 QueryType.FULL을 지정하면 Lucene 쿼리 구문을 사용한다는 의미이다. 아래의 Lucene 쿼리 구문의 기능을 활용해 보다 정교한 검색을 구현할 수 있다.
fun searchWithLucene(searchClient: SearchClient, queryString: String) {
val searchOptions = SearchOptions()
.setQueryType(QueryType.FULL) // Lucene 쿼리 구문 활성화
.setIncludeTotalCount(true)
.setSelect("id", "title", "content")
.setOrderBy("score desc")SearchOptions의 QueryType
검색 쿼리를 처리하는 방식을 결정하는 이넘 타입
1. SIMPLE
- default 쿼리 유형
- +, *, \"\"와 같은 기호를 허용하는 간단한 쿼리 언어로 해석
- 와일드카드, 정규식, 부스팅 등 고급 기능 미지원
2. FULL
- Lucene 쿼리 구문을 사용
- 복잡한 검색 조건을 표현할 수 있는 다양한 기능 제공
- 필드 검색, 와일드카드 등 고급 기능 지원
3. SEMANTIC
- 의미 기반 검색을 활성화
- 자연어 처리(NLP) 모델을 사용하여 검색 결과의 관련성을 향상시킴
- 의미적으로 관련성이 높은 결과 우선 제공
Lucene 쿼리 구문의 주요 기능(QueryType.FULL)
1. 필드 지정 검색
filedName:value 형식으로 특정 필드에서만 검색
title:"Azure Search" // title 필드에 Azure Search가 포함된 문서를 검색
title:"Azure Search" AND author:"Microsoft" // 여러 필드 검색 2. 와일드카드 검색
*(다중 문자), ?(단일 문자)를 사용한 패턴 매칭
Az*re // Azure, Azre 등 매칭
Azu?e // Azure 매칭 :: Azu로 시작하고 e로 끝나며 중간에 한 글자가 있는 단어 검색3. 퍼지 검색
~ 연산자를 사용해 철자가 유사한 단어 검색
azur~ // azure, azul 등 유사한 단어 매칭4. 근접 검색
~n 을 사용해 단어 간 거리가 n 이하인 경우를 검색
"azure cloud"~2 // azure와 cloud 사이에 최대 2개 단어까지 허용5. 부스팅
^n을 사용해 특정 용어나 구문의 중요도를 높임
azure^2 cloud // azure를 cloud보다 2배 중요하게 처리6. 불리언 연산자
AND, OR, NOT(+,-)을 사용한 복합 검색
azure AND cloud // azure 와 aws 모두
azure OR aws // azure 또는 aws 중 하나
azure NOT aws // azure는 포함하지만 aws는 제외
+azure -aws // azure는 반드시 포함, aws는 제외7. 그룹화
괄호를 사용해 쿼리를 그룹화
(azure OR microsoft) AND cloud // azure 또는 microsoft 중 하나를 포함하고, cloud도 포함하는 문서 검색8. 범위 검색
숫자나 날짜 등의 범위 검색
price:[100 TO 200] // 100 이상 200 이하, []는 경계값 제포함
date:{2023-01-01 TO 2023-12-31} // 2023년(양 끝 제외), {}는 경계값 제외https://lucene.apache.org/
https://learn.microsoft.com/ko-kr/azure/search/query-lucene-syntax
오픈소스 검색엔진 Lucene
https://learn.microsoft.com/ko-kr/dotnet/api/azure.search.documents.models.searchquerytype?view=azure-dotnet
