문제를 생각하게 된 계기
현재 팀원이 refactoring을 거친 상품 상세 페이지의 커밋된 코드를 보다가 생각하게되었다.
추가로 현재 로직에서의 Entity 조회와 Dto조회에 대해서 고민을 하다가 작성을 한다.
(JPA 2편에서는 선 Entity를 추천했지만 우아한 테크에서는 조회시에는 Dto를 선택했다.)
현재 구조
현재 요약
1. 관련 모든 테이블을 Join 시켜서 한번의 쿼리로 Dto로 여러개의 데이터를 리스트형태로 가져온다.(QDto에 Expression으로 list를 못넣기때문)
2. 모든 리스트를 돌면서 UrlList에 들어갈 값들을 (platform, url) Map으로 바꾼다.
3. Tag도 같음
4. 그리고 다시 1번 데이터의 첫번째 값을 가지고와서 위에서 준비한 값들을 넣어서 완성
1번, DB
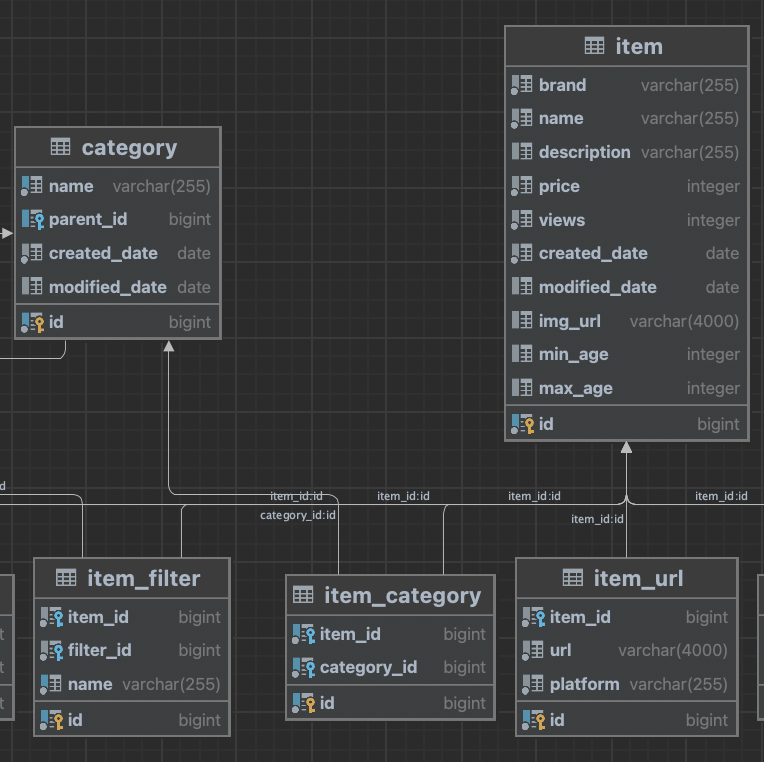
-
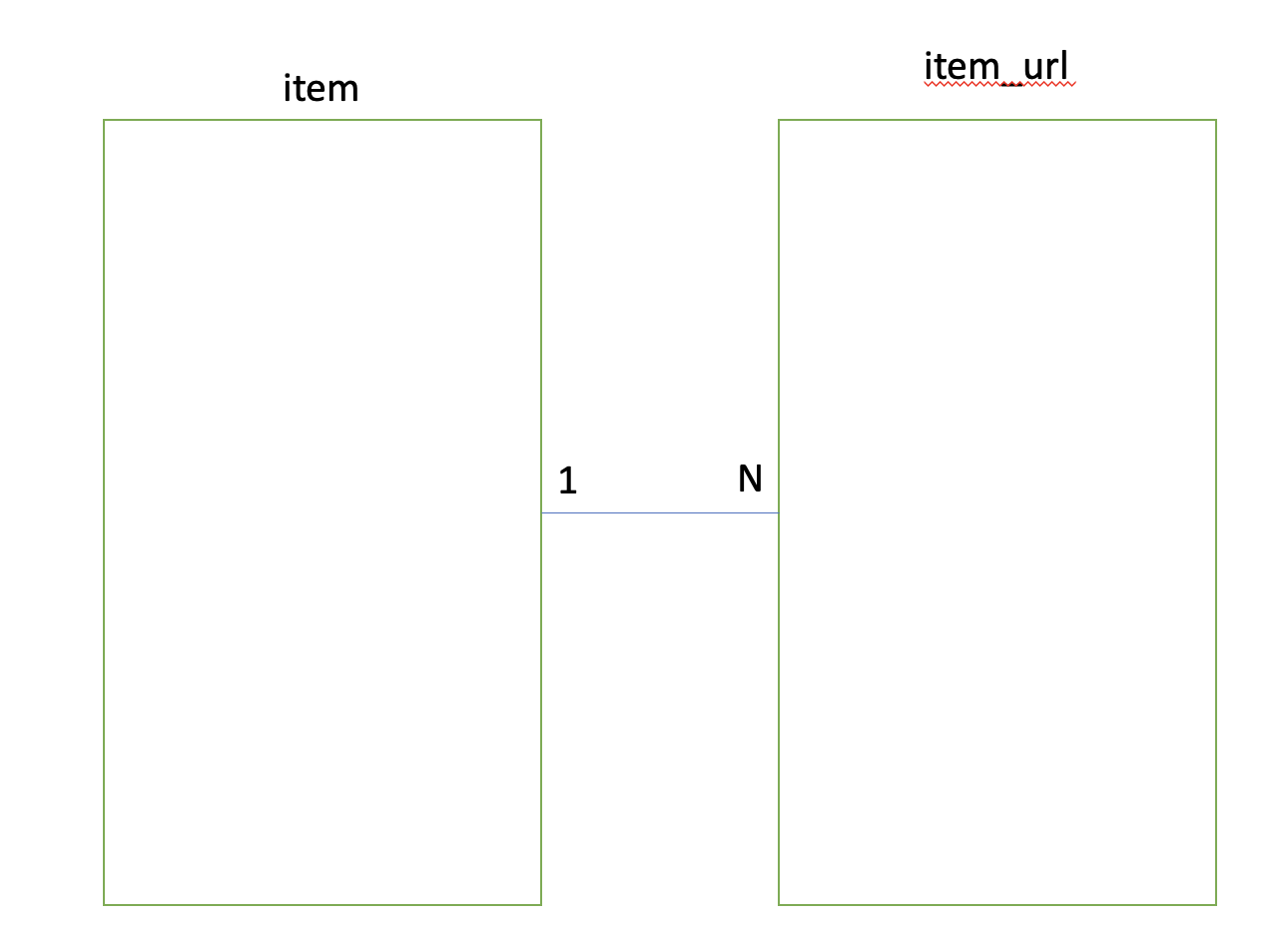
아이템과 item_url은 일대다 조인
-
item과 category는 item_category라는 중간 테이블을 두고 일대다,다대일 조인이다.
2번, 코드
- 반환 Dto
public class ItemInfoResponseDto {
private Long itemId;
private String name;
private String brand;
private String description;
private int price;
private String imgUrl;
private int views;
private String platform;
private String url;
private String filterTag;
private String categoryTag;
private boolean isLiked;
private Long memberId;
- Repository
public List<ItemInfoResponseDto> itemResponse(Long itemId, Member member) {
...
.innerJoin(qItemUrl).on(qItem.id.eq(qItemUrl.item.id))
.innerJoin(qItemCategory).on(qItem.id.eq(qItemCategory.item.id))
.innerJoin(qCategory).on(qItemCategory.category.id.eq(qCategory.id))
...
}memberId 와 itemId를 넣어서 상세 정보를 구한다.
여기서 item과 item_url을 일대다 조인을 하여 중복 데이터가 증가한 상태이다.
또한 카테고리 역시 join되었다.
- Service
- 3.1 조회용 Service
@Transactional
public ItemInfoResponseDto findItemInfo(Long itemId, Member member) {
increaseViews(itemId);
List<ItemInfoResponseDto> itemResponses = itemRepository.itemResponse(itemId, member);
// platform과 url을 그룹핑하여 반환
Map<String, String> platforms = new HashMap<>();
for (ItemInfoResponseDto itemResponse : itemResponses) {
if (itemResponse.getPlatform() != null && itemResponse.getUrl() != null) {
platforms.put(itemResponse.getPlatform(), itemResponse.getUrl());
}
}
ItemInfoResponseDto itemInfoResponseDto = itemResponses.get(0);
itemInfoResponseDto.setUrl(platforms.toString());
itemInfoResponseDto.setPlatform(platforms.keySet().toString());
List<String> filterTags = itemResponses.stream()
.map(ItemInfoResponseDto::getFilterTag)
.distinct()
.limit(2)
.toList();
itemInfoResponseDto.setFilterTag(filterTags.toString());
return itemInfoResponseDto;3.2 아이템 조회수 업데이트 Service
@Transactional
public void increaseViews(Long itemId) {
Item item = em.find(Item.class, itemId);
item.increaseViews();
}3번,현재 나가는 쿼리 (하나의 아이템 상세정보 조회)
- Item entity 영속성 조회 쿼리(2-3.1에서 만들어짐)
select
i1_0.id,
i1_0.brand,
i1_0.created_date,
i1_0.description,
i1_0.img_url,
i1_0.max_age,
i1_0.min_age,
i1_0.modified_date,
i1_0.name,
i1_0.price,
i1_0.views
from
cherishu.item i1_0
where
i1_0.id=1003
2023-04-19T15:10:11.196+09:00 INFO 57660 --- [nio-8080-exec-1] p6spy : execution time: 17ms - Item view 증가 update 쿼리(2-3.1에서 만들어짐)
update
cherishu.item
set
brand='아로마티카',
description='라벤더, 베르가못, 패츌리 등 오일이 블렌딩된 필로우미스트에요. 아늑하고 포근한 아로마향으로 지친 몸과 마음에 안정을 선사해줘요.',
img_url=NULL,
max_age=30,
min_age=20,
modified_date='2023-04-19T00:00:00.000+0900',
name='로즈마리 스칼프 스케일링 샴푸 바 135G',
price=22000,
views=54
where
id=1003- Item 상세 정보 조회 쿼리 (2-2에서 만들어짐)
select
i1_0.id,
i1_0.name,
i1_0.brand,
i1_0.description,
i1_0.price,
i1_0.img_url,
i1_0.views,
i2_0.platform,
i2_0.url,
i6_0.name,
c1_0.name,
i8_0.member_id
from
cherishu.item i1_0
join
cherishu.item_url i2_0
on i1_0.id=i2_0.item_id
join
cherishu.item_category i4_0
on i1_0.id=i4_0.item_id
join
cherishu.category c1_0
on i4_0.category_id=c1_0.id
join
cherishu.item_filter i6_0
on i1_0.id=i6_0.item_id
left join
cherishu.item_like i8_0
on i1_0.id=i8_0.item_id
where
i1_0.id=1003
and i6_0.filter_id=5
and substr(cast(i1_0.id as text),1,1)=cast(c1_0.id as text)Entity 조회와 Dto 조회 정리
-
Entity조회는 현재 연관 필드가 전부 LAZY LODING 처리가 되어 있으므로
fetch join혹은 한번에 IN절로 가져오는BatchSize,deafult_batch_fetch_size등을 활용할 수 있다.
(영속성 컨텍스트에 올라감) -
Dto 조회는 원하는 값만 뽑아오는 것이기 때문에
innerjoin등 조인을 이용하여 원하는 값을 뽑아오면 된다. 추가로 원하는 필드만 선택해서 가지고올 수있다.(조회 성능 최적화)
(영속성 컨텍스트에서 관리가 되지 않음)
그렇다면 어느경우에 해당 방법들을 사용해야할까?
- Entity 조회 같은 경우 값이 실시간 변경이 있거나 필드의 값을 많이 활용 할때
- 주의 사항 : 조회하는 엔티티에 연관 엔티티를 올려 의도치 않은 지연로딩을 발생시키면 안된다.(우아한 테크)
- Dto 다량의 데이터를 조회할 경우 원하는 값만 뽑아오기에 최적화
- 단점: 직접 SQL을 짜는것과 비슷한 코드를 짜야함.
- 현재 같이 한방 쿼리를 일대다 조인과 함께 만들었을 경우 페이징 불가능
추가적으로 Entity의 필드가 40~50개 정도면 차이가 나겠지만
요즘 DB 성능이 좋아서 엔티티를 조회해서 모든 필드값을 가지고 오는 것이 그렇게 크게 차이가 없다고함.(JPA 2편)
개발자가 힘들게 DTO를 만들어서 IN절 던지는 것과 결국 엔티티 조회방식의
BatchSize와 동일함
엔티티 조회에서 성능이 안나오면 많은 데이터를 조회하는 상황이므로 캐시(Redis) 등을 사용하는 것을 고려해야함.
추가로 한방 쿼리로 보내면 네트워크 부하가 덜 올수는 있지만 중복되는 데이터를 많이 전송하게 되어
결국은 네트워크 부하가 쿼리를 한방 더쏘는 것과 비슷하다.
최적화란?
최적화란, 말 그대로 가장 알맞은 상황으로 맞춘다는 말이다.
(나무위키)
최적화를 시키기 위해 다양한 Dto코드 혹은 리팩토링도 중요하다.
하지만 코드의 인식성과 간결성, 생산성을 생각하면 무작정 최적화를 하는 것도 안좋은 것 같다.
물론 대량의 데이터를 사용하기 위해 N+1을 막으려고 최적화를 할 수도 있다.
하지만 1개의 데이터를 조회하고 연관 필드가 1개밖에 없다면 BatchSize로 In절을 조절하거나 Dto로 원하는 값만 가져오는 최적화가 크게 빛을 못하고 가독성만 떨어뜨릴수 있다.
그래서 개인적으로 이번 쿼리를 보면서 최적화란알맞은 상황에 맞게 상황을 고려야하여 개발하는 것 같다.
어떤것이 더 좋을진 이후 테스트를 해볼 예정이다.
현재 나의 개발 방식 같은 경우
-
진짜 조회만 해야한다.
=> Dto를 쓰되 상황에 맞게 쪼개서 쿼리를 보낼 것 같다.
=> 중복 데이터를 피하고 역할과 반환값에 집중할 것 같다.
=> 데이터가 많아지면 1차 캐시 등 다른 최적화를 찾는다. -
실시간으로 변경이 있다.
=> **엔티티 조회 방식을 사용할 것 같다.
=>fetch join과BatchSize -
@OneToMany를 지양한다.
-
애매한 상황이다.
=> 엔티티 조회 방식으로 구성할 것 같다.
현재는 Dto 사용 방식
일단, 3번에서 보면 현재 Item 정보를 조회하는 쿼리가 중복으로 2번 호출이 된다.
(상세 정보, 영속화 엔티티)
그래서 Dto + 벌크성 수정 혹은 Item 엔티티를 조회해서 Dto로 반환 방식을 사용할 듯 하다.
하지만 나는 후자가 더 나은 듯하다.
두번째로, 현재 많은 데이터를 Dto 스펙에 맞춰서 가져오다보니
일부 필드만 달라지는데 다른 정보들까지 중복해서 가져오고 있다.
(join해서 가져왔기에)
(현재 그룹핑을 따로 진행하여 첫줄만 다시 들고온 후 덮어쓰기를 하는 방식이 사용되고 있다.)
해당 쿼리를 개인적으로
// Repository
@Override
public List<ItemInfo> itemReponse(Long itemId, Member member) {
}
@Override
public List<ItemUrlInfo> itemUrl(Long itemId) {
}
@Override
public List<ItemUrlInfo> itemTag(Long itemId) {
}
로 수정해서 Dto로 가져온뒤 수정을 할 것 같다.
해당 Item Entity 필드값을 거의 다 사용하고 있으니
Entity와 연관된 일대다에 IN절을 날려서 한번에 들고와서 인메모리에서 그룹핑을 해서 itemResponseDto로 줄 듯하다.
여기도 후자가 좋은듯하다.(item view update 시에도 영속성 컨텍스트에서 찾아오니 쿼리가 나가지 않는다.)
필드 수도 현재 최대 10개로 적은 편에 속한다.
참고
기본적으로 현재 방식도 원하는 값이 나오고 있다.
단지 더 좋은 방법, Dto조회 방식과 Entity 조회방식에서 차이점을 보기 위해 해당 글을 쓰고 리뷰를 하는 중이지 결과가 잘못된 것은 절대 아니다.
물론 json 형식에 수정이 조금 있어야하겠지만 원하는 내용의 값은 제대로 들어가고 있다.

수정된 성능 차이
현재 방식에서 Entity 조회를 사용했을 경우 성능을 비교하여 적어보려고 한다. (DB에서의 차이도 한번 보려고해서p6spy도 사용했다.)
사실 필드 갯수가 그렇게 많지 않아서 크게 성능 차이가 나올까 싶다.
이렇게
p6spy : execution time: 22ms
현재(Dto조회 한방 쿼리)
일단 현재 코드로 나온 실행시간이다.
1.INFO 65410 --- [nio-8080-exec-2] p6spy : execution time: 22ms
2.INFO 65410 --- [nio-8080-exec-2] p6spy : execution time: 25ms
3.INFO 65410 --- [nio-8080-exec-2] p6spy: execution time: 25ms
total: findItemInformation 실행 시간: 359ms (첫 실행기준)개선된 방식(Entity 조회)
1번 Item + ItemUrl(1:N) - fetchJoin 사용 , 카테고리는 쿼리 1방
total .findItemInformation 실행 시간: 182ms (3번)
(첫 실행 기준)
1.2023-04-20T17:51:34.796+09:00 INFO 66910 --- [nio-8080-exec-1] p6spy : execution time: 18ms
select
distinct i1_0.id,
i1_0.brand,
i1_0.created_date,
i1_0.description,
i1_0.img_url,
i2_0.item_id,
i2_0.id,
i2_0.platform,
i2_0.url,
i1_0.max_age,
i1_0.min_age,
i1_0.modified_date,
i1_0.name,
i1_0.price,
i1_0.views
from
cherishu.item i1_0
join
cherishu.item_url i2_0
on i1_0.id=i2_0.item_id
where
i1_0.id=1003
2.2023-04-20T17:51:34.839+09:00 INFO 66910 --- [nio-8080-exec-1] p6spy : execution time: 13ms
select
c1_0.name
from
cherishu.item_category i1_0
join
cherishu.category c1_0
on c1_0.id=i1_0.category_id
where
i1_0.item_id=1003
3. 2023-04-20T17:51:34.858+09:00 INFO 66910 --- [nio-8080-exec-1] p6spy : execution time: 13ms
update
cherishu.item
set
brand='아로마티카',
description='라벤더, 베르가못, 패츌리 등 오일이 블렌딩된 필로우미스트에요. 아늑하고 포근한 아로마향으로 지친 몸과 마음에 안정을 선사해줘요.',
img_url=NULL,
max_age=30,
min_age=20,
modified_date='2023-04-20T00:00:00.000+0900',
name='로즈마리 스칼프 스케일링 샴푸 바 135G',
price=22000,
views=65
where
id=1003
total .findItemInformation 실행 시간: 182ms (3번)
(첫 실행 기준)2번 Item + ItemUrl + ItemTag 모두 batch_fetch_size만 처리
total.findItemInformation 실행 시간: 236ms (쿼리 5방)
1. 2023-04-20T18:17:39.471+09:00 INFO 67329 --- [nio-8080-exec-2] p6spy : execution time: 15ms
select
i1_0.id,
i1_0.brand,
i1_0.created_date,
i1_0.description,
i1_0.img_url,
i1_0.max_age,
i1_0.min_age,
i1_0.modified_date,
i1_0.name,
i1_0.price,
i1_0.views
from
cherishu.item i1_0
where
i1_0.id=1003 fetch first 1 rows only
2. 2023-04-20T18:17:39.493+09:00 INFO 67329 --- [nio-8080-exec-2] p6spy : execution time: 9ms
select
i1_0.item_id,
i1_0.id,
i1_0.platform,
i1_0.url
from
cherishu.item_url i1_0
where
i1_0.item_id=1003
3.2023-04-20T18:17:39.511+09:00 INFO 67329 --- [nio-8080-exec-2] p6spy : execution time: 9ms
select
i1_0.item_id,
i1_0.id,
i1_0.category_id
from
cherishu.item_category i1_0
where
i1_0.item_id=1003
4. 2023-04-20T18:17:39.526+09:00 INFO 67329 --- [nio-8080-exec-2] p6spy : execution time: 9ms
select
c1_0.id,
c1_0.created_date,
c1_0.modified_date,
c1_0.name,
c1_0.parent_id
from
cherishu.category c1_0
where
c1_0.id in(53,107,54,55,108,1)
5.2023-04-20T18:17:39.575+09:00 INFO 67329 --- [nio-8080-exec-2] p6spy : execution time: 11ms
update
cherishu.item
set
brand='아로마티카',
description='라벤더, 베르가못, 패츌리 등 오일이 블렌딩된 필로우미스트에요. 아늑하고 포근한 아로마향으로 지친 몸과 마음에 안정을 선사해줘요.',
img_url=NULL,
max_age=30,
min_age=20,
modified_date='2023-04-20T00:00:00.000+0900',
name='로즈마리 스칼프 스케일링 샴푸 바 135G',
price=22000,
views=80
where
id=1003
2023-04-20T18:17:39.586+09:00 INFO 67329 --- [nio-8080-exec-2] p6spy : execution time: 9ms
commit
2023-04-20T18:17:39.587+09:00 INFO 67329 --- [nio-8080-exec-2] c.b.i.controller.PublicItemController :
total.findItemInformation 실행 시간: 236ms (쿼리 5방)
해당 방법은 조회할 데이터가 많을 때 좋을 것 같다.
하나의 상세페이지를 조회하기엔 IN절의 효과를 극대화하지 못하는 것 같다.
그래서 성능을 보기 위한 2개의 상세페이지와 1개만 조회수 증가(사용하진 않을 예정)
1. 2023-04-20T19:01:25.951+09:00 INFO 68002 --- [nio-8080-exec-2] p6spy : execution time: 15ms
select
i1_0.id,
i1_0.brand,
i1_0.created_date,
i1_0.description,
i1_0.img_url,
i1_0.max_age,
i1_0.min_age,
i1_0.modified_date,
i1_0.name,
i1_0.price,
i1_0.views
from
cherishu.item i1_0
where
i1_0.id=1003 fetch first 1 rows only
2. 2023-04-20T19:01:25.978+09:00 INFO 68002 --- [nio-8080-exec-2] p6spy : execution time: 11ms
select
i1_0.id,
i1_0.brand,
i1_0.created_date,
i1_0.description,
i1_0.img_url,
i1_0.max_age,
i1_0.min_age,
i1_0.modified_date,
i1_0.name,
i1_0.price,
i1_0.views
from
cherishu.item i1_0
where
i1_0.id=1004 fetch first 1 rows only
3. 2023-04-20T19:01:25.993+09:00 INFO 68002 --- [nio-8080-exec-2] p6spy : execution time: 11ms
select
i1_0.item_id,
i1_0.id,
i1_0.platform,
i1_0.url
from
cherishu.item_url i1_0
where
i1_0.item_id in(1003,1004)
4.2023-04-20T19:01:26.011+09:00 INFO 68002 --- [nio-8080-exec-2] p6spy : execution time: 12ms
select
i1_0.item_id,
i1_0.id,
i1_0.category_id
from
cherishu.item_category i1_0
where
i1_0.item_id in(1003,1004)
5. 2023-04-20T19:01:26.030+09:00 INFO 68002 --- [nio-8080-exec-2] p6spy : execution time: 12ms
select
c1_0.id,
c1_0.created_date,
c1_0.modified_date,
c1_0.name,
c1_0.parent_id
from
cherishu.category c1_0
where
c1_0.id in(53,107,54,55,108,60,57,59,109,110,58,1)
6.2023-04-20T19:01:26.109+09:00 INFO 68002 --- [nio-8080-exec-2] p6spy : execution time: 12ms
update
cherishu.item
set
brand='아로마티카',
description='라벤더, 베르가못, 패츌리 등 오일이 블렌딩된 필로우미스트에요. 아늑하고 포근한 아로마향으로 지친 몸과 마음에 안정을 선사해줘요.',
img_url=NULL,
max_age=30,
min_age=20,
modified_date='2023-04-20T00:00:00.000+0900',
name='로즈마리 스칼프 스케일링 샴푸 바 135G',
price=22000,
views=84
where
id=1003
2023-04-20T19:01:26.122+09:00 INFO 68002 --- [nio-8080-exec-2] p6spy : execution time: 11ms
commit
total. findItemInformation 실행 시간: 271ms (6번)2개 조회를 해야하니 2번 엔티티 조회를 위한 추가 쿼리 1개 이외에 변동 사항없고 실행 시간도 IN로 인한 최적화
3번. 각각 테이블에서 조회를 따로 따로 해서 합치기
(4번은 각각 Dto로 조회해와서 합칠려고했으나 이후 수업 때문에 엔티티로만)
total. findItemInformation 실행 시간: 360ms (4번)
1. 2023-04-20T18:27:12.487+09:00 INFO 67484 --- [nio-8080-exec-1] p6spy : execution time: 19ms
select
i1_0.id,
i1_0.brand,
i1_0.created_date,
i1_0.description,
i1_0.img_url,
i1_0.max_age,
i1_0.min_age,
i1_0.modified_date,
i1_0.name,
i1_0.price,
i1_0.views
from
cherishu.item i1_0
where
i1_0.id=1003 fetch first 1 rows only
2. 2023-04-20T18:27:12.554+09:00 INFO 67484 --- [nio-8080-exec-1] p6spy : execution time: 13ms
select
i1_0.url
from
cherishu.item_url i1_0
where
i1_0.item_id=1003
3. 2023-04-20T18:27:12.574+09:00 INFO 67484 --- [nio-8080-exec-1] p6spy : execution time: 13ms
select
c1_0.name
from
cherishu.item_category i1_0
join
cherishu.category c1_0
on c1_0.id=i1_0.category_id
where
i1_0.item_id=1003
4. 2023-04-20T18:27:12.606+09:00 INFO 67484 --- [nio-8080-exec-1] p6spy : execution time: 14ms
update
cherishu.item
set
brand='아로마티카',
description='라벤더, 베르가못, 패츌리 등 오일이 블렌딩된 필로우미스트에요. 아늑하고 포근한 아로마향으로 지친 몸과 마음에 안정을 선사해줘요.',
img_url=NULL,
max_age=30,
min_age=20,
modified_date='2023-04-20T00:00:00.000+0900',
name='로즈마리 스칼프 스케일링 샴푸 바 135G',
price=22000,
views=81
where
id=1003
total. findItemInformation 실행 시간: 360ms (4번)결론
- 컬렉션 최적화에서 페이징을 쓰지 않는다면 1번 방식을 사용한다.
- 페이징을 사용한다면 2번 방식을 통해 최적화를 진행한다.
쿼리문 숫자에 관한 고찰
단점
- 한방쿼리의 치명적인 단점은 전체 프로세스를 모른다면 수정하기가 너무 버겁다.
- 문제 해결에만 몰두하여 매우 비효율적인 쿼리문을 작성하게된다.
- 생산성이 낮아진다.
장점
- 하지만 네트워크 사용을 최소화 할 수 있다.
- 리소스를 적게 먹어서 장점이 극대화 된다.
- 한번에 데이터가 원하는대로 뽑혀서 나온다.
결론
- 조회만을 필요로하면 Dto 조회(쿼리 수 최소화)
- join 활용
- 사실상 sql
- 변경점이 존재하면 Entity조회 (쿼리 수 1번에 비해 많음)
- 컬렉션 값 조심
fetchJoin과batch_fetch_size활용
- 쿼리는 자주 나가서도 안되지만 생산성이 낮아질 수 있기 때문에 적당한 선에서 타협
- 네트워크 상태와 리소스 상태에 따라 선택
현재는 엔티티를 조회해서 페이징 여부가 없는 페이지인 상황으로 진행.
