문제 발생
문제 1번
현재 상황은 상품 상제 조회할때 쿼리가 10개가 나갔다.
그리고 한번의 최적화 후 4개로 줄어들었다.
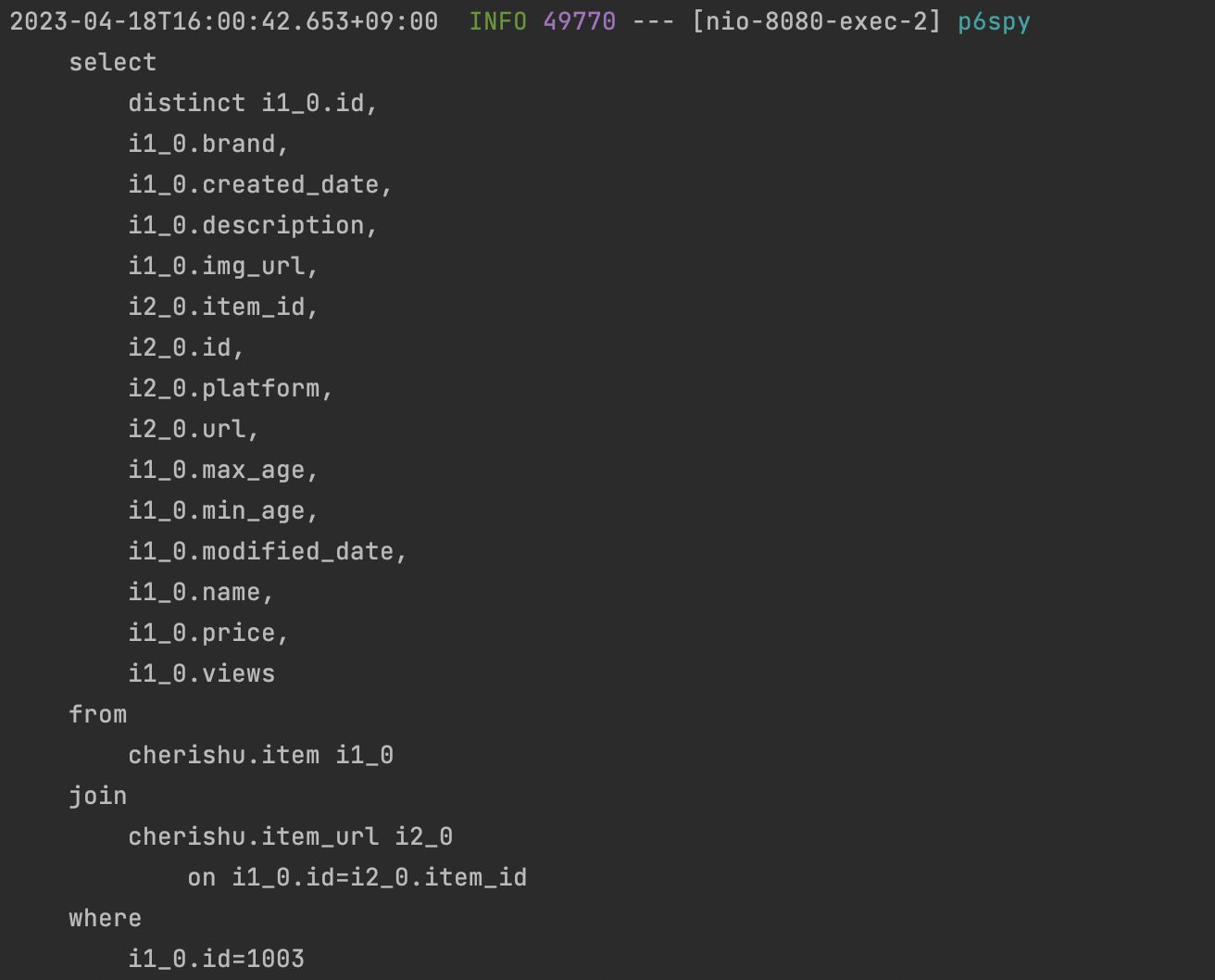
1. item view 증가를 위해 itemId를 통한 item 탐색
//Item item = itemRepository.findItemById(itemId);
select
i1_0.id,
i1_0.brand,
i1_0.created_date,
i1_0.description,
i1_0.img_url,
i1_0.max_age,
i1_0.min_age,
i1_0.modified_date,
i1_0.name,
i1_0.price,
i1_0.views
from
cherishu.item i1_0
where
i1_0.id=1003- update 문
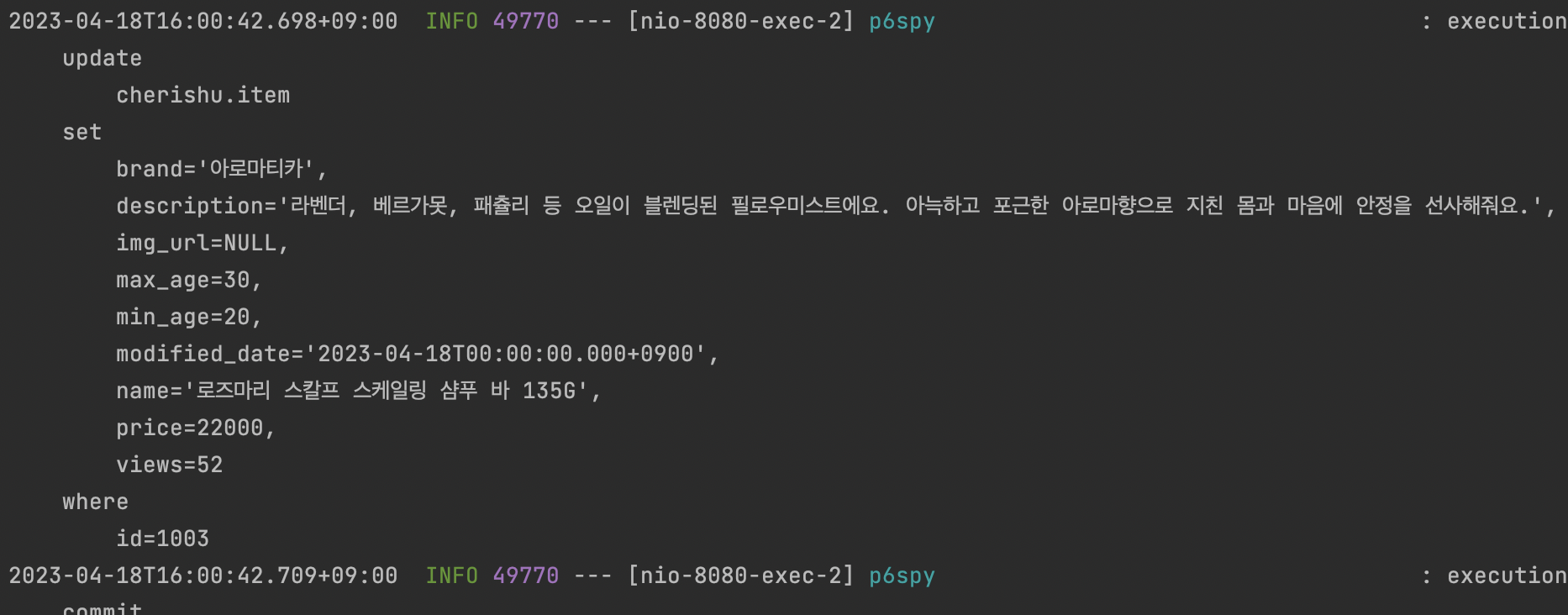
// 더티 체킹
update
cherishu.item
set
brand='아로마티카',
description='라벤더, 베르가못, 패츌리 등 오일이 블렌딩된 필로우미스트에요. 아늑하고 포근한 아로마향으로 지친 몸과 마음에 안정을 선사해줘요.',
img_url=NULL,
max_age=30,
min_age=20,
modified_date='2023-04-18T00:00:00.000+0900',
name='로즈마리 스칼프 스케일링 샴푸 바 135G',
price=22000,
views=53
where
id=1003- dto 조회문
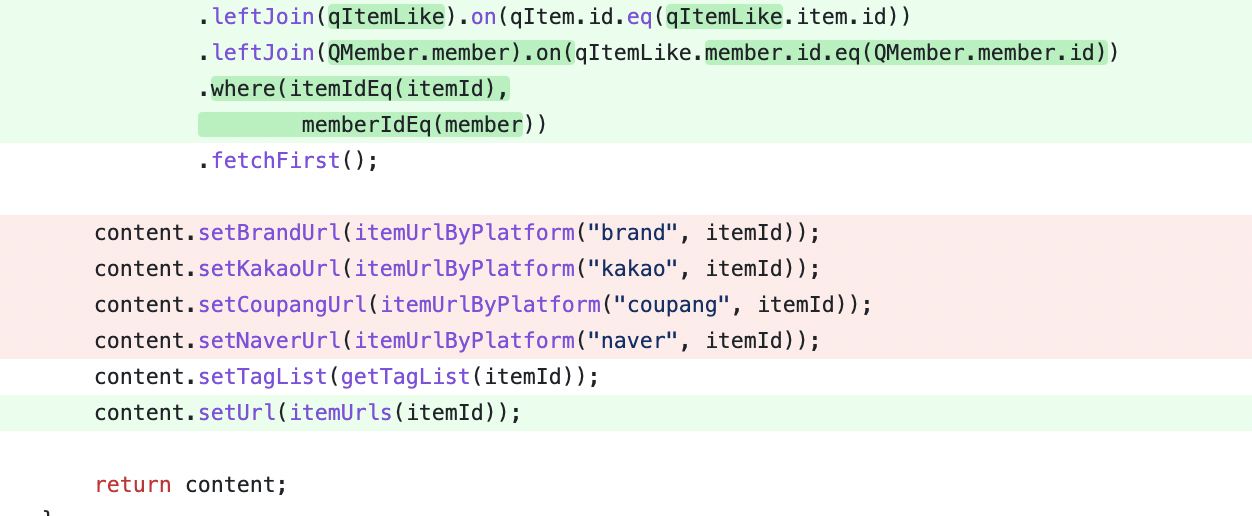
ItemInfoResponseDto content = queryDslConfig.jpaQueryFactory() .select(Projections.constructor(ItemInfoResponseDto.class, qItem.id.as("itemId"), qItem.name.as("name"), qItem.brand.as("brand"), qItem.description.as("description"), qItem.price.as("price"), qItem.imgUrl.as("imgUrl"), qItem.views.as("views"), isLiked.as("isLiked"), QMember.member.id)) .from(qItem) .leftJoin(qItemFilter).on(qItem.id.eq(qItemFilter.item.id)) .leftJoin(qItemLike).on(qItem.id.eq(qItemLike.item.id)) .leftJoin(QMember.member).on(qItemLike.member.id.eq(QMember.member.id)) .where(itemIdEq(itemId), memberIdEq(member)) .fetchFirst();
select
i1_0.id,
i1_0.name,
i1_0.brand,
i1_0.description,
i1_0.price,
i1_0.img_url,
i1_0.views,
case
when (i4_0.id is not null) then cast(true as boolean)
else false
end,
m1_0.id
from
cherishu.item i1_0
left join
cherishu.item_filter i2_0
on i1_0.id=i2_0.item_id
left join
cherishu.item_like i4_0
on i1_0.id=i4_0.item_id
left join
cherishu.member m1_0
on i4_0.member_id=m1_0.id
where
i1_0.id=1003 fetch first 1 rows only- item url 조회문
select
i1_0.platform,
i1_0.url
from
cherishu.item_url i1_0
where
i1_0.item_id=1003문제 2번
그리고 현재 Repository 하나의 메소드에서 모든 repository의 메소드와 연관을 가지고 Dto생성을 하고 있다.
나의 문제 생각
2번 문제에 대해
1번 (선호하는 방식)
현재 플로우 방식달라야 한다고 생각한다.
- Controller 에서 요청이 들어온다.
- Service 단에서 해당 아이템 정보가 들어 있는 ItemInfo , 해당 아이템 url List , 해당 아이템 Tag 를해서 결합한다.
- Repository 에서는 아이템 상세정보는 상세 정보에 집중 , url List 는 urlList 에 집중
뭔가 안맞는다 라고 생각이 든 부분은 현재 Service 가 종합해야하는 내용을 Repository가 종합을 하는 것 같다.
아마 이 1,2,3 번 플로우로 가면 Repository에서 조회한 결과값을 Service 단에서 합치는 형태가 될 것 같다.
1번 문제에 대해
처음에는 Transaction 범위 때문인가 생각을 하였다.
하지만 관리되는 Entity를 들고온것이 아니라 Dto를 조회한 것이라 영속성 컨텍스트에서 관리가 되지 않으니 Transaction 범위는 아니였다.
그 다음은 한 메소드에 한번에 조회하는 방법을 해보았다.
하지만 결국 List를 Dto에 넣어야하는데 Expression으로 List를 fetch 하지 않고 하는 방법은 없는 것 같다. (추후 다른 팀원의 의견을 들어보려고한다.)
결국은 해당 방법으로 쿼리를 줄였다.
하지만 현재 ItemUrl만 적용한 내용으로 한방 쿼리를 하였다.,
이후 "일 대 다" 인 Tag를 적용할 경우
hibernate.default_batch_fetch_size= 500 를 사용해서 한방 쿼리는 불가능 할 듯하다.
총 나오는 쿼리를 분석했다.
-
item view 를 올리기위한 영속성 컨텍스트에 없는 item 재 조회
해결방법 : -
fetch join으로 차라리 엔티티 영속후 DTO변환
=> 이유 : 사실 상품 상세페이지 정보에서는 안쓰는 필드값이 없기때문에 영속성 컨텍스츠에서 재 사용하는 것이 나을듯함. => 그렇게 되면 삭제 -
현재와 동일한 Dto조회 사용 + update문 벌크 연산 처리
-
update 쿼리 => 일단 현재 더티체킹 사용이 안되고 있습니다. 수정해야할듯합니다.
1-1번의 연장선으로
@Transactional
public ItemInfoResponseDto findItemInfo(Long itemId) {
Item item = itemRepository.itemResponse(itemId);
// dto 변환 로직
item.increaseViews();
return new ItemInfoResponseDto(); // 여기는 데이터 바인딩 하시면 됩니다. 200 볼려고 넣었습니다.
}- Item 엔티티 조회 =>현재 상품 상세페이지니 페이징 필요없음 fetch join 해서 엔티티 영속화
Item item = queryDslConfig.jpaQueryFactory()
.select(qItem)
.from(qItem)
.join(qItem, qItemUrl.item).fetchJoin()
.fetchFirst();어차피 git stash로 날릴 예정이라 다 해보지는 않았습니다만 itemUrl과했을 때 (엔티티 조회 + 업데이트문) 총 2건이 나오는 것 까지 확인했습니다.
10개 -> 4개 -> 2개
- 조회 1번
- view update 한번
추가 사안
fetch join이 쿼리 최적화에 한방 쿼리로 좋긴하지만 컬렉션 fetch join을 사용하면 페이징이 불가능하다는점이 있다.
위 상황은 페이징을 사용하지 않으니 사용하였다.
하지만 최적화된 hibernate.default_batch_fetch_size 옵션을 활용해 1개의 쿼리(BatchSize 미만일 경우)를 더 보내는 것이 좋다고 합니다.(페이징 가능)
- 페치 조인 방식과 비교해서 쿼리 호출 수가 약간 증가하지만, DB 데이터 전송량이 감소한다.
결론
결국엔 최적화를 해도 계속한 "다 대 일" 조인이 아닌이상 BatchSize 로 In 절 나가는(+1) 쿼리가 필수적이다.
현재는 Url을 가지고만(1개의 일대다) 테스트를 진행하였다. 총 2개까지 줄였다.
이후 Tag도 일 대 다 인 상황에서 계속되는 상황이면 fetch join은 불가능하지만 hibernate.default_batch_fetch_size 를 통해 최적화를 이룰 수 있다.
