
- 2024.05.13 복습용
테이블 데이터 관리
--테이블 강제 삭제(참조키와 연결된 경우)
--기본키와 참조키가 연결되어있으면 먼저 참조키 테이블을 삭제 후 기본키 테이블을 삭제할 수 잇음
drop table [테이블명] cascade constraints purge;
--데이터를 제외한 테이블 구조 복사
create table [새로 만들 테이블명] as select *from [데이터를 가져올 테이블명] where 0 = 1;테이블 구조를 복사하면 데이터는 비워지고 껍데기만 똑같은 테이블이 생성된다.
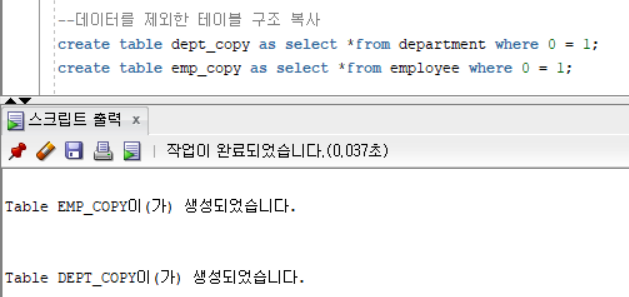

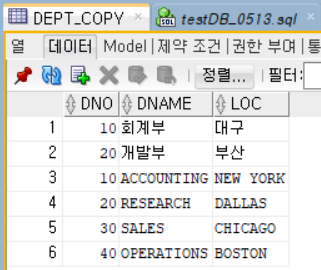
테이블의 구조만 가져온 상태이기 때문에 기본키, 참조키는 없는 상태이다. 그렇기에 아래와 같이 테이블에 데이터를 추가하는 것이 가능하다.
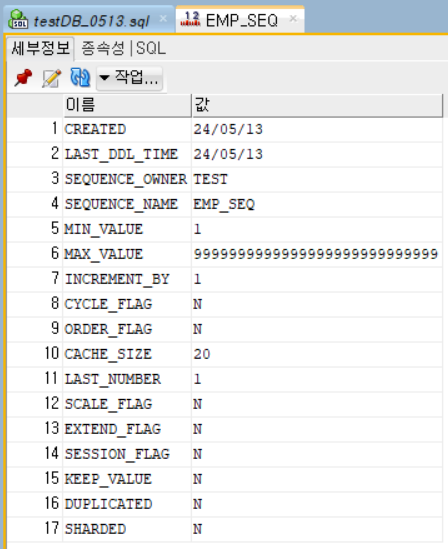
Sequence
일련의 숫자를 생성하는 객체로서 주로 고유 식별자(primary key) 값을 생성하는 데 사용된다. 시퀀스는 특정한 형태의 테이블에 연결되어 있지 않으며, 데이터베이스 전체에서 공유될 수 있다.
CREATE SEQUENCE [시퀀스명]
START WITH 1
INCREMENT BY 1
MAXVALUE [값]
MINVALUE [값];

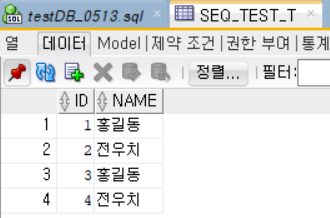
새로 생성한 테이블에 시퀀스를 사용해서 넣어주면, ID값이 알아서 1씩 올라가며 삽입됨을 알 수 있다. 이는 시퀀스를 사용해서 자동으로 값이 올라간 것이다. emp_seq.nextval은 시퀀스 emp_seq의 다음 값을 가져와서 해당 값을 삽입에 사용한다. 따라서 각 삽입 작업이 실행될 때마다 시퀀스 값은 1씩 증가하며, 테이블의 primary key로 사용되는 값이 된다.

실습_01
- 함수 실습
--입사한지 6개월 지난 사원
--add_months(date,n) -date에 n을 더함
select ename, hiredate, add_months(hiredate, 6) from employee;
--날짜 표시 : to char 함수
select ename, hiredate, to_char(hiredate, 'yy-mm'),
to_char(hiredate, 'yyyy/mm/dd') from employee;
--현재 날짜, 시간 표시
--dual : 함수를 사용해서 계산 결과값을 확인할때 사용
select to_char(sysdate, 'yyyy/mm/dd hh24:mi:ss') from dual;
--화폐기호 표시
--L : 지역별 통화 기호
--0 : 자리수가 맞지 않으면 '0'을 채움
--9 : 자리수가 맞지 않으면 빈자리 무시
select ename, to_char(salary, 'L999,999')from employee;
--case를 사용하여 이름, 부서명 출력
select ename, dno,
case
when dno = 10 then '회계부'
when dno = 20 then '홍보부'
when dno = 30 then '영업부'
when dno = 40 then '비서실'
else '알수없음'
end as "부서명"
from employee order by dno;
--decode() 를 사용하여 case 유사하게 출력
--부서명, 지역명, 사원수, 모든 사원의 평균 급여 출력
select
decode (dno, 10, '회계부', 20, '홍보부', 30, '영업부', 40, '비서실') "부서명",
decode (dno, 10, '대구', 20, '서울', 30, '부산', 40, '광주') "지역",
count (*) as "사원수", round(avg(salary)) as "평균급여"
from employee group by dno;
--view : 가상 테이블 (메모리 관리, 보안)
create or replace view join_test_v as
select e.ename, d.dname, e.salary, s.grade from
employee e, department d, salgrade s
where e.dno=d.dno and salary between losal and hisal;
연습_01
--1. department의 모든 데이터를 dept_copy2 테이블에 복사
create table dept_copy2 as select *from department;
--2. employee의 모든 데이터를 emp_copy2 테이블에 복사
create table emp_copy2 as select *from employee;
--3. 10번 부서의 지역명을 20번 부서의 지역명으로 변경(서브쿼리 이용)
update dept_copy2 set
loc=(select loc from dept_copy2 where dno = 20)
where dno = 10;
--4. 10번 부서의 부서명과 지역명을 30번 부서의 부서명과 지역명으로 변경(서브쿼리 이용)
update dept_copy2 set
dname=(select dname from dept_copy2 where dno = 30),
loc=(select loc from dept_copy2 where dno = 30)
--5. 영업부 사원 모두 삭제(서브쿼리 이용)
delete from emp_copy2 where
dno=(select dno from department where dname = 'SALES');
--6. 사원, 부서, 급여등급 테이블을 조인하여
-- 사번, 사원명, 급여, 담당업무, 입사일, 부서명, 근무지, 급여등급을
-- 출력하는 가상테이블 생성
create or replace view virtual_t as
select e.eno "사번", e.ename "사원명", e.salary "급여", e.job "담당업무",
e.hiredate "입사일", d.dname "부서명", d.loc "근무지", s.grade "급여등급"
from employee e
join department d on e.dno = d.dno
join salgrade s on e.salary between s.losal and s.hisal;
select * from virtual_t;
select "사번", "사원명", "부서명", "급여등급" from virtual_t;

_〆(。。)