
- 2024.05.08 복습용
테이블 생성
가장 간단하고 기초적인 테이블 생성이다. 표를 만들어서 그 안에 데이터를 입력할 수 있도록 한다.
sql developer를 열고, 이전에 만들어둔 실습용 계정에 접속한다. 나는 마지막으로 만들어둔 test 계정을 이용할 예정이다. 워크시트를 열고 아래와 같이 일단 적어보자.
--create table [테이블명]
create table customer(
name VARCHAR2(20),
age NUMBER(5),
gender CHAR(1),
reg_date DATE DAFAULT sysdate
);순서대로 명령어를 보겠다.
- customer 라는 테이블을 생성
- 최대 20자의 문자를 저장할 수 있는 문자열 name 열 생성
- 최대 5자리의 숫자를 저장할 수 있는 공간의 age 열 생성
- 문자 하나를 저장하는 gender 열 생성
- DATE 타입의 reg_date 열 생성
데이터 이름 뒤에는 데이터의 타입, 저장크기가 순서대로 입력되어있는 형태이다. 이렇게 입력하고 f5를 눌러서 스크립트를 전체로 잘 돌렸다면, 테이블 생성에 성공하였을 것이다.
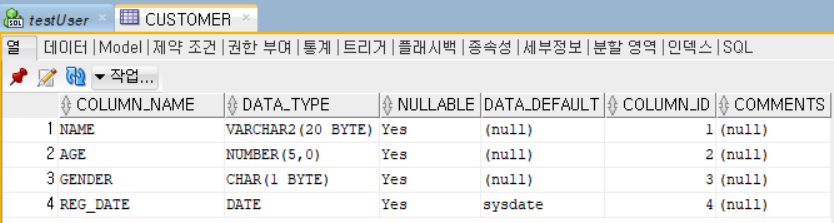
실습_01
이제 테이블에 데이터를 넣어보자. 아래와 같은 명령어를 사용하여 데이터를 넣을 수 있다.
--insert data
insert into customer(name, age, gender, reg_date)
values('홍길동', 100, 'M', sysdate);insert into는 데이터를 입력하는 명령어이다. customer라는 테이블에 name, age, gender, reg_date의 값을 입력하겠다는 것이다. values로 그 값을 입력해준다. sysdate는 시스템의 날짜를 의미한다. 참고로 데이터베이스에서는 문자와 문자열의 구분이 명확하지 않다. 데이터를 표시할 때는 ' '가 꼭 필요하다.
이렇게 데이터를 입력하였다면, 제대로 들어갔는지 확인할 필요가 있다.
select * from [테이블명];위의 명령어 테이블명으로 customer를 적으면, customer 테이블의 모든 데이터를 확인할 수 있다. * 을 입력하면 모든 데이터를 뜻하며 이것 대신에 name, age를 입력하면 이에 해당하는 데이터만 확인할 수 있다.

참고로 입력한 명령어에 커서를 놓고 ctrl+enter를 누르면 그 부분의 명령어만 실행이 가능하다.
실습_02
테이블을 생성하고 데이터를 입력하는 간단한 실습을 해보았다. 또다른 워크시트를 열고, 이번에는 다른 테이블을 생성하여 실습해보겠다.
create table student_t (
id VARCHAR2(10) primary key,
name VARCHAR2(20),
age NUMBER,
tel VARCHAR(30)
);여기서 primary key는 데이터 중복을 방지하기 위함이다. 컴퓨터는 이 데이터가 겹쳐도 되는지 안되는지 구분을 하지 못한다. 그런 컴퓨터에게 primary key를 사용하여 이 데이터는 겹치면 안된다고 알려주는 용도이다.

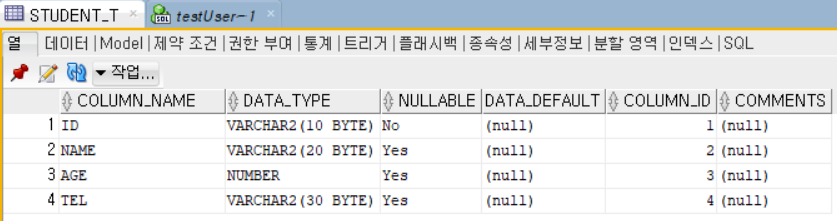
이제 여기에도 데이터를 입력하고, 확인해보겠다.
insert into student_t (id, name, age, tel)
values('st0001', '홍길동', 20, '010-1111-1234');테이블에 학번, 이름, 나이, 전화번호 데이터를 입력받도록 하였다. 이 데이터 입력을 2번 입력하면 오류문구가 뜬다. primary key로 이미 저장된 id가 중복된 id를 저장하지 못하도록 막기 때문이다.

primary key를 다르게 설정하면 이렇게 테이블에 데이터가 잘 들어가는 모습을 확인할 수 있다. 이름과 전화번호는 같아도 상관이 없는데, 이 부분은 primary key를 설정하지 않아서이다.

여태까지 했던 것과는 다르게 id, name만 입력을 해보겠다. 이러면 age, tel의 값은 들어가지 않은 상태이다. 테이블을 확인해보면 age, tel은 (null)로 표기되어있는데, 데이터가 누락되었다는 뜻이다.

만일 데이터를 확인하였는데, 이렇게 누락이 되어있으면 곤란한 상황이 생긴다. 그렇기에 애초에 누락이 되지 않도록 설정을 해줘야 한다.
create table student_t (
id VARCHAR2(10) primary key,
name VARCHAR2(20) not null,
age NUMBER not null,
tel VARCHAR(30)not null
);not null을 이렇게 추가하면, null을 받아들이지 않겠다는 뜻이다. 이렇게 하면 데이터가 누락되지 않아야만 데이터를 저장할 수 있다.
drop table [테이블명];실습을 위해 테이블을 한 번 지우고(ctrl+enter), 테이블 생성 명령어를 다시 실행해준다. 이제 id, name만 입력된 데이터를 다시 저장해주려고 한다면, 오류 문구가 뜰 것이다.
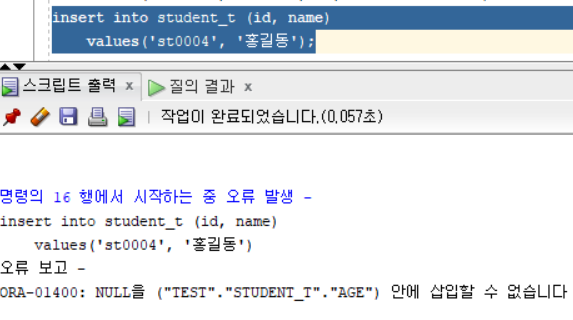
나는 이렇게 쿼리문을 작성하고, 필요한 명령어 부분만 ctrl+enter로 명령문 실행하였다. f5는 전체 스크립트 실행이니, 이렇게 쿼리문을 적고 f5를 누르면 테이블 또는 뷰가 없다는 오류문구가 뜰 가능성이 있다.
create table student_t (
id VARCHAR2(10) primary key,
name VARCHAR2(20) not null,
age NUMBER not null,
tel VARCHAR(30)not null
);
drop table student_t;
insert into student_t (id, name, age, tel)
values('st0001', '홍길동', 20, '010-1111-1234');
insert into student_t (id, name, age, tel)
values('st0002', '홍길동', 20, '010-1111-1234');
insert into student_t (id, name, age, tel)
values('st0003', '홍길동', 20, '010-1111-1234');
insert into student_t (id, name)
values('st0004', '홍길동');
select * from student_t;
워크시트를 열면 나오는 이 작은 아이콘들이 위에 있을텐데, 왼쪽 초록 세모가 명령문 실행(ctrl+enter)이고 오른쪽 메모표시와 같이 있는 아이콘이 스크립트 실행(f5)이다.
연습_01
1. person_t 테이블 생성
2. 주민등록번호, 이름, 나이, 전화, 주소를 입력받는 칼럼
3. 주민등록번호를 중복되지 않게 처리
4. 모든 컬럼의 값은 null값을 허용하지 않음
5. 데이터 3개 이상 추가
6. 전체 데이터 실행create table person_t (
id VARCHAR2(14) primary key not null,
name VARCHAR2(20) not null,
age NUMBER(5) not null,
tel VARCHAR(30)not null,
addr VARCHAR2(50)not null
);
insert into person_t (id, name, age, tel, addr)
values('000000-1111111', '홍길동', 20, '010-1111-1234', '대구 동구 신천3동');
insert into person_t (id, name, age, tel, addr)
values('111111-2222222', '김철수', 44, '010-1232-5555', '대구 달서구 월성동');
insert into person_t (id, name, age, tel, addr)
values('333333-4444444', '이영희', 15, '010-7645-4567', '대구 북구 침산동');
select * from person_t;
실습_03
delete from [테이블명];이 명령어는 해당 테이블의 모든 데이터를 삭제하는 명령어이다. 사용하면 이전에 넣어둔 데이터가 삭제되었다는 문구를 확인할 수 있다.
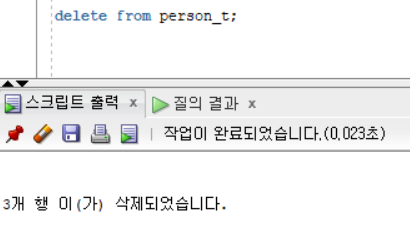
update [테이블명]
set [열1] = [새 값1],
[열2] = [새 값2];이 명령어는 테이블의 데이터를 변경할 수 있는 명령어다. 아래와 같이 사용하면 모든 데이터가 같은 값으로 변경이 된다.

데이터베이스를 이용할 때, 이렇게 조건도 없이 데이터를 변경하거나 전체를 삭제하는 등의 행위는 사용할 일이 거의 없다고 봐도 무관하다. 그렇기 때문에 조건거는 법을 알아야 한다.
--조건을 이용한 조회
select * from [테이블명] where [조건];--조건을 이용한 삭제
delete from [테이블명] where [조건];--조건을 이용한 수정
update [테이블명] set [열] =[새로운 값] where [조건]--person_t의 모든 값 중 age가 22인 값 검색
select * from person_t where age = 22;
--person_t의 모든 값 중 name이 '홍길동'인 값 조회
select * from person_t where name = '홍길동';
--person_t의 모든 값 중 name이 '홍길동'이거나 age가 22인 값 조회
select * from person_t where name = '홍길동' or age = 22;
--person_t의 모든 값 중 name이 null인 값 조회
select * from person_t where name is null;
--person_t의 모든 값 중 name이 null이 아닌 값 조회
select * from person_t where name is not null;
--person_t의 모든 값 중 name에 '길'이 포함된 값 조회
select * from person_t where name like '%길%';
--person_t의 값 중 name의 값이 '홍길동'인 열 삭제
delete from person_t where name = '홍길동';
--person_t에서 name 값이 '이영희'인 열의 name을 '이유리'로 변경
update person_t set name = '이유리' where name = '이영희';연습_02
--1. 사원의 급여가 2000~3000 사이에 포함되고 부서번호가 20 또는 30인
-- 사원명, 급여, 부서번호 출력(이름 기준 내림차순)
select ename as "사원명", salary as "급여", dno as "부서번호" from employee
where salary in(2000, 3000) and dno = 20 or dno = 30 order by ename desc;
--2. 1981년도 입사한 사원명, 입사일, 출력(입사일 기준 오름차순)
select ename as "사원명", hiredate as "입사일" from employee
where SUBSTR(hiredate, 1, 2) = '81' order by hiredate asc;
--3. 관리자가 없는 사원명, 담당업무 출력
select ename as "사원명", job as "담당업무" from employee where manager is null;
--4. 상여금을 받는 사원명, 급여, 상여금 출력(급여기준 내림차순)
select ename as "사원명", salary as "급여", commission as "상여금" from employee
where commission > 0 order by salary desc;
--5. 이름의 3번째 문자가 'R'인 모든 사원명 출력
select ename as "사원명" from employee where ename like '__R%';
--6. 이름에 A와 E를 모두 포함하는 사원명, 급여, 담당업무 출력
select ename as "사원명", salary as "급여", job as "담당업무" from employee
where ename like '%A%' and ename like '%E%';
--7. 담당업무가 사무원 또는 영원사원이면서 급여가 950, 1300, 1600 이 아닌
-- 사원명, 담당업무, 급여 출력하기(사원명 내림차순)
select ename as "사원명", job as "담당업무", salary as "급여"from employee
where (job = 'CLERK' or job = 'SALESMAN') and salary not in (950, 1300, 1600) order by ename desc;
정리
1. 테이블 생성
CREATE TABLE [테이블명] (열1 데이터타입, 열2 데이터타입, ...);
-- 데이터 타입 뒤에 not null을 입력하면 null 값을 허용하지 않음
-- 데이터 타입 뒤에 primary key를 입력하면 중복 값을 허용하지 않음2. 데이터 삽입
INSERT INTO [테이블명] (열1, 열2, ...) VALUES (값1, 값2, ...);3. 데이터 조회
SELECT * FROM [테이블명];4. 조건에 따른 데이터 조회
SELECT * FROM [테이블명] WHERE [조건];
--정렬 : order by [정렬기준] (ASC/DESC, 오름차순/내림차순 중 하나)
--SELECT [검색할 열] as "별칭" : as 생략 가능, 열의 별칭을 붙여줌5. 데이터 삭제
DELETE FROM [테이블명] WHERE [조건];
--drop table [테이블명] : 테이블 삭제6. 데이터 수정
UPDATE [테이블명] SET [열] = [새로운값] WHERE [조건];