들어가기 전 복습
-
결측치 확인
table(is.na(df$score)) -
함수의 결측치 제외 기능
mean(df$score, na.rm=T) -
이상치 확인
table(outlier$s) -
ggplot2 함수들
geom_point() : 산점도
geom_col() : 막대그래프 - 요약표
geom_bar() : 막대그래프 - 원자료
geom_line() : 선 그래프
geom_boxplot() : 상자 그림
종교 유무에 따른 이혼율
- 종교가 있는 사람들이 이혼을 덜 할까 ?
- 라이브러리 실행
library(dplyr)
library(ggplot2)
dplyr 패키지는 데이터 전처리와 분석을 위한 도구들을 제공하며, ggplot2 패키지는 데이터 시각화를 위한 도구를 제공한다.
2.종교 변수 검토 및 전처리
class(welfare$religion)
캐릭터table(welfare$religion)
NO YES
8617 80473.종교 유무에 이름을 부여
welfare$religion 값이 1인 경우 'YES'(종교가 있음)로, 그 외의 경우는 'NO'(종교가 없음)로 변환한다.
이후 qplot() 함수를 사용하여 종교 유무의 분포를 시각화한다.
welfarereligion == 1,
'YES', 'NO')
qplot(welfare$religion)
- 혼인 상태 변수 검토 및 전처리
class(welfare$marriage)
누메릭table(welfare$marriage)
0 1 2 3 4 5 6
2861 8431 2117 712 84 2433 26 - 이혼 여부 변수 생성
welfaremarriage == 1, 'marriage', ifelse(welfaregroup_marriage)
table(is.na(welfaregroup_marriage)
welfaremarriage 값이 3인 경우 'divorce'(이혼) 변환하고,
그 외의 값은 NA로 처리한다.
6.종교 유무에 따른 이혼율 표 생성
결측치(NA)를 제외한 데이터를 대상으로 religion(종교 유무)과 group_marriage(혼인 상태) 변수로 그룹화한 후,
각 그룹의 빈도수를 계산한다.
이후, 그룹별 전체 수를 합산해 비율(pct)을 계산한다.
religion_marriage <- welfare %>%
filter(!is.na(group_marriage)) %>%
group_by(religion, group_marriage) %>%
summarise(n = n()) %>%
mutate(tot_group = sum(n),
pct = round(n/tot_group*100, 1))
religion_marriage
divorce marriage
712 8431 종교가 있는 사람들 중 결혼 상태와 이혼 상태의 비율을 계산하고,
이혼율이 얼마나 되는지를 분석할 수 있다.
예를 들어, 종교가 있는 사람들의 이혼율은
(712 / (712 + 8431)) * 100 = 약 7.8%가 된다.
각 단계 설명
filter(!is.na(group_marriage))
group_marriage 변수가 NA가 아닌 행만 필터링한다.
즉, 결측치(NA)를 제외한 데이터를 사용한다.
group_by(religion, group_marriage)
religion(종교 유무)과 group_marriage(혼인 상태) 변수로 데이터를 그룹화한다.
이 과정에서 종교 유무와 혼인 상태의 조합에 따라 데이터를 묶는다.
summarise(n = n())
각 그룹의 빈도수를 계산하여 n이라는 새로운 변수에 저장한다.
'종교 있음 & 결혼 상태', '종교 있음 & 이혼 상태' 등과 같은 조합별로 몇 개의 데이터가 있는지 계산한다.
mutate(tot_group = sum(n), pct = round(n/tot_group*100, 1))
mutate() 함수는 새로운 변수를 생성하거나 기존 변수를 변형한다.
tot_group = sum(n)
각 religion(종교 유무) 그룹별로 n의 합을 계산하여 tot_group에 저장한다.
즉, 해당 그룹에서 전체 데이터의 수를 나타낸다.
pct = round(n/tot_group*100, 1)
각 혼인 상태(group_marriage)의 비율을 계산하여
pct 변수에 저장한다.
이때, 비율은 소수점 첫째 자리까지 반올림된다.
- 이혼율 표 생성: 이혼 추출
group_marriage가 'divorce'(이혼 상태)인 경우만 필터링하여
이혼율만 추출한다.
종교 유무에 따른 이혼율이 저장된 divorce 데이터프레임을 생성한다.
divorce <- religion_marriage %>%
filter(group_marriage == 'divorce') %>%
select(religion, pct)
divorce
religion pct
<chr> <dbl>
1 NO 8.3
2 YES 7.2ggplot(data=divorce, aes(x=religion, y=pct)) + geom_col()
ggplot2 패키지를 사용하여 종교 유무(religion)에 따른 이혼율(pct)을 막대 그래프로 시각화할 수 있다.
이 그래프를 통해 종교가 있는 사람과 없는 사람의 이혼율 차이를 시각적으로 확인할 수 있다.
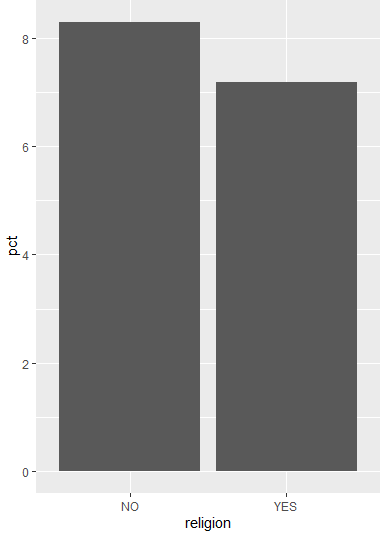
지역별 연령대 비율
- 노년층이 많은 지역은 어디인가?
- 지역 변수 검토 및 전처리
class(welfare$code_region)
[1] "numeric"table(welfare$code_region)
1 2 3 4 5 6 7
2486 3711 2785 2036 1467 1257 2922 - 지역 코드 목록 생성
list_region <- data.frame(code_region = c(1:7),
region = c(
'서울',
'수도권(인천/경기)',
'부산/경남/울산',
'대구/경북',
'대전/충남',
'강원/충북',
'광주/전남/전북/제주도'
))
- welfare 에 지역명 변수 추가 - 매칭
welfare <- left_join(welfare, list_region, by='code_region')
welfare %>%
select(code_region, region) %>%
head(20)
left_join()을 사용하여 welfare 데이터프레임에 region(지역명) 변수를 추가합니다.
이후, code_region과 region 변수를 20개 행까지 확인합니다.
- 지역별 연령대 비율 분석
4-1. 나이 변수가 없는 경우 새로 생성
welfarebirth + 1
welfare 데이터프레임에 age 변수를 생성합니다.
출생연도(birth)를 사용하여 2015년 기준 나이를 계산합니다.
4-2. 연령대 변수가 없는 경우 새로 생성
welfare <- welfare %>%
mutate(ageg = ifelse(age < 30, 'young',
ifelse(age <= 59,'middle','old')))
ageg라는 연령대 변수를 생성합니다.
30세 미만은 'young' (젊은층)
30세에서 59세는 'middle' (중년층)
60세 이상은 'old' (노년층)으로 분류합니다.
- 지역별 연령대 비율표 생성
region_ageg <- welfare %>%
group_by(region, ageg) %>%
summarise(n=n()) %>%
mutate(tot_group = sum(n),
pct = round(n/tot_group*100, 2))
region_ageg
지역별(region)과 연령대별(ageg)로 데이터를 그룹화한 후,
각 그룹의 빈도수를 계산하여 n 변수에 저장합니다.
그룹별 전체 수(tot_group)를 계산한 후,
각 연령대의 비율(pct)을 소수점 둘째 자리까지 계산합니다.
# A tibble: 21 × 5
# Groups: region [7]
region ageg n tot_group pct
<chr> <chr> <int> <int> <dbl>
1 강원/충북 middle 417 1257 33.2
2 강원/충북 old 555 1257 44.2
3 강원/충북 young 285 1257 22.7
4 광주/전남/전북/제주도 middle 947 2922 32.4
5 광주/전남/전북/제주도 old 1233 2922 42.2
6 광주/전남/전북/제주도 young 742 2922 25.4
7 대구/경북 middle 637 2036 31.3
8 대구/경북 old 928 2036 45.6
9 대구/경북 young 471 2036 23.1
10 대전/충남 middle 548 1467 37.4
# ℹ 11 more rows
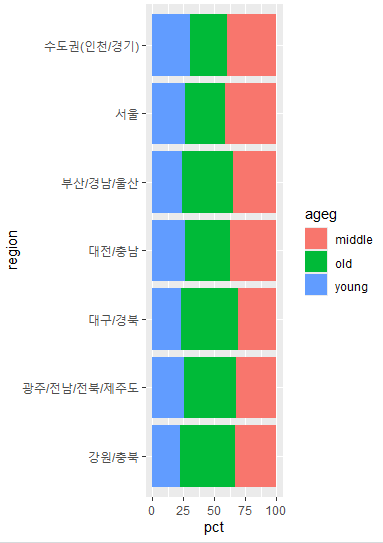
# ℹ Use `print(n = ...)` to see more rows- 그래프 생성
ggplot2 패키지를 사용하여 지역별 연령대 비율을 시각화합니다.
geom_col()을 사용하여 막대 그래프를 그리며,
coord_flip()을 통해 x축과 y축을 뒤집어
가로형 막대 그래프로 표시합니다.
ggplot(data=region_ageg, aes(x=region, y=pct, fill=ageg)) +
geom_col() +
coord_flip()
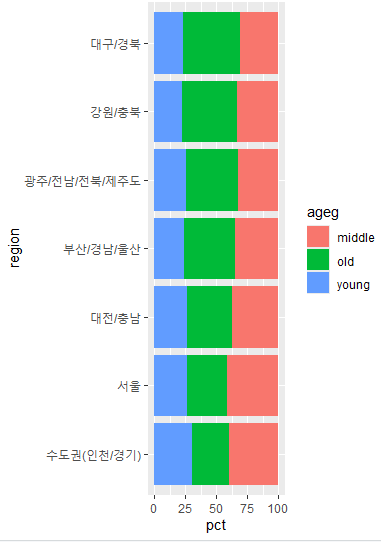
- 막대 정렬 : 노년층 비율 높은 순서
region_ageg 데이터프레임에서 ageg가 'old'인 행만 필터링하고,
노년층 비율(pct)이 높은 순서대로 정렬합니다.
list_order_old <- region_ageg %>%
filter(ageg == 'old') %>%
arrange(pct)
list_order_old
# A tibble: 7 × 5
# Groups: region [7]
region ageg n tot_group pct
<chr> <chr> <int> <int> <dbl>
1 수도권(인천/경기) old 1109 3711 29.9
2 서울 old 805 2486 32.4
3 대전/충남 old 527 1467 35.9
4 부산/경남/울산 old 1124 2785 40.4
5 광주/전남/전북/제주도 old 1233 2922 42.2
6 강원/충북 old 555 1257 44.2
7 대구/경북 old 928 2036 45.6- 지역명 순서 변수 생성
order 라는 변수에 노년층 비율이 높은 순서대로 지역명을 저장합니다.
order <- list_order_old$region
order
ggplot(data=region_ageg, aes(x=region, y=pct, fill=ageg)) +
geom_col() +
coord_flip() +
scale_x_discrete(limits=order)
노년층 비율이 높은 순서에 따라
지역명이 정렬된 막대 그래프를 생성합니다.
aes(x=region, y=pct, fill=ageg)
aes() 함수는 그래프에서 사용할 미적 요소를 지정한다.
x=region: x축에 지역(region)을 배치한다.
y=pct: y축에 연령대 비율(pct)을 배치한다.
fill=ageg: 막대의 색상을 연령대(ageg)에 따라 다르게 지정한다.
geom_col()
막대 그래프를 그리기 위한 ggplot2의 레이어입니다.
coord_flip()
그래프의 x축과 y축을 뒤집는 함수입니다.
함수는 가로형 막대 그래프를 만들 때 사용됩니다.
scale_x_discrete(limits=order)를 사용하여
x축에 표시되는 지역명이 order 변수에 따라 정렬됩니다.