한국복지패널데이터
- 한국보건사회연구원 발간
- 가구의 경제활동을 연구해 정책 지원에 반영할 목적
- 2006 ~ 2015년까지 전국에서 7천여 가구를 선정해 매년 추적 조사
- 경제활동, 생활실태, 복지욕구 등 수천 개 변수에 대한 정보로 구성
패키지 & 라이브러리
install.packages('foreign')
library(foreign) # SPSS 파일 로드
library(dplyr) # 전처리
library(ggplot2) # 시각화
library(readxl) # 엑셀 파일 로드
- 한국복지패널데이터 파일 다운로드 필요
이후 해당 파일을 폴더에 옮기기
데이터 준비
real_welfare <- read.spss(file='C:/R_Project_bigdata/Koweps_hpc10_2015_beta1.sav', to.data.frame = T)
복사본 만들기
welfare <- real_welfare
데이터 검토
head(welfare)
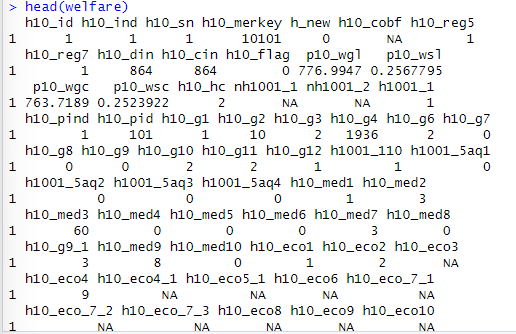
str(welfare)
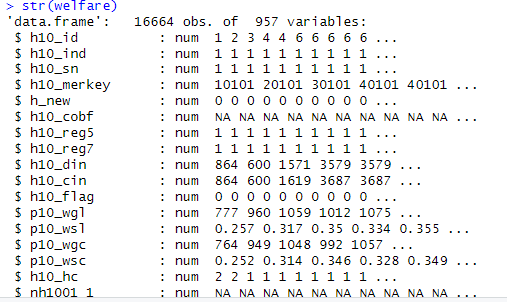
summary(welfare)
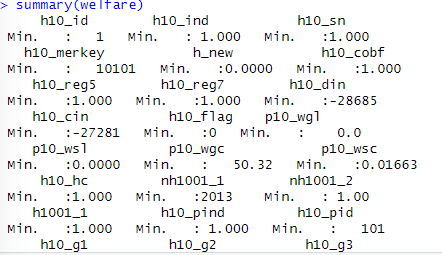
변수명 수정
대규모 데이터 같은 경우는 사용할 변수명을 쉬운 단어로 바꾼 후
분석에 사용할 변수들 각각 파악하는게 좋음.
welfare <- rename(welfare,
s = h10_g3, # 성별
birth = h10_g4, # 태어난 년도
marriage = h10_g10, # 혼인 상태
religion = h10_g11, # 종교
income = p1002_8aq1, # 월급
code_job = h10_eco9, # 직종 코드
code_region = h10_reg7) # 지역 코드
데이터 분석 절차
1단계 : 변수 검토 및 전처리
2단계 : 변수 간 관계 분석 (요약표 만들거나 그래프 생성)
주제: 성별에 따른 월급 차이 - 성별에 따라 월급이 다를까 ?
성별 변수 검토 및 전처리
class(welfare$s)
[1] "numeric"table(welfare$s) # 이상치 확인
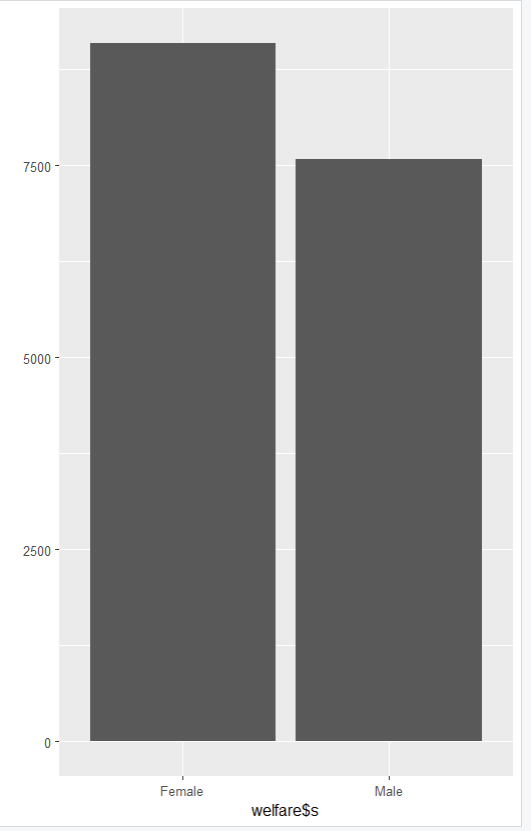
1 2
7578 9086 전처리 - 이상치 없는 데이터만 출력
table(is.na(welfare$s)) # 결측치 x
welfare$s
FALSE
16664 성별 항목 이름 부여
welfares == 1, 'Male', 'Female')
welfare$s가 1이면 남자, 2이면 여자로 표기하도록 함
table(welfare$s)
테이블 확인하기
Female Male
9086 7578qplot(welfare$s)
남자와 여자의 수를 막대 그래프로 시각화해서 볼 수 있다.
월급 변수 검토 및 전처리
class(welfare$income)
누메릭으로 나오는 것을 알수 있다.
[1] "numeric"summary(welfare$income)
인컴(월급)의 최소값, 최대값, 평균 등을 볼 수 있다.
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
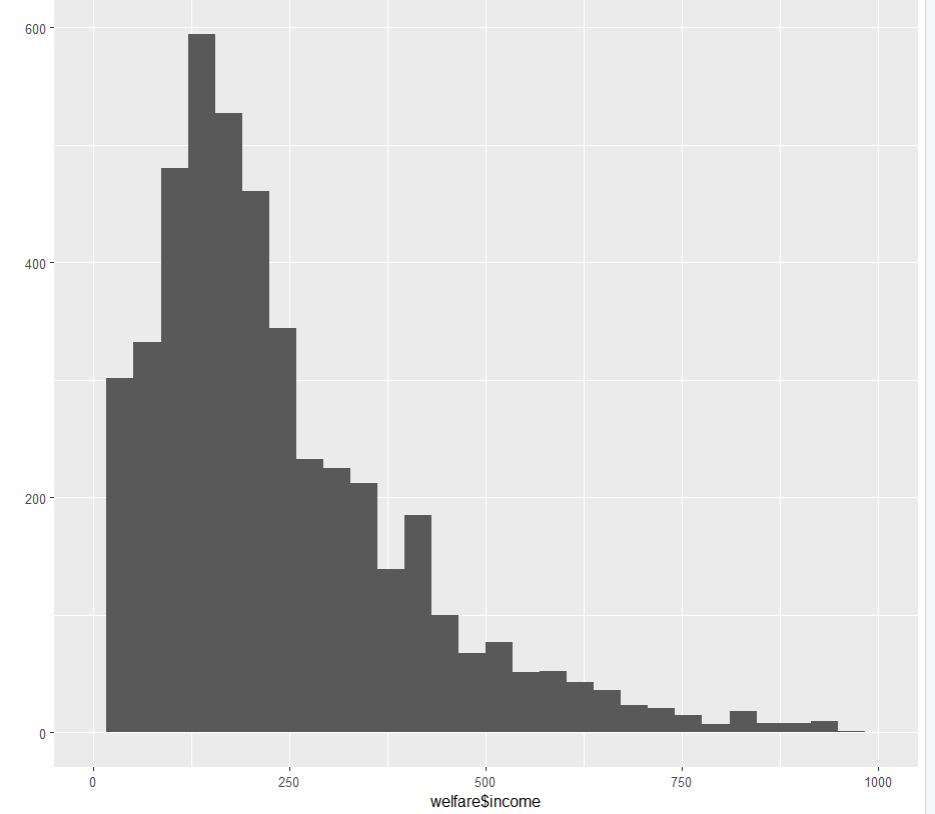
0.0 122.0 192.5 241.6 316.6 2400.0 12030 qplot(welfare$income) + xlim(0,1000)
xlim(0, 1000)은 x축의 범위를 설정해서 히스토그램을 만든다.
x좌표 0에서 1000까지로 한다.
(기준은 최소, 최대값을 보고 만든 것임)
따라서, 0보다 작거나 1000보다 큰 income 값들은 히스토그램에서 제외됨.
데이터 전처리
데이터 전처리를 하기 위해 다시 summary를 보자.
이상치가 있는 것을 알 수 있다.
summary(welfare$income)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.0 122.0 192.5 241.6 316.6 2400.0 12030 이상치 결측 처리
welfareincome %in% c(0, 9999),
NA, welfare$income)
ifelse() 함수는 조건에 따라 값을 할당하는 함수임.
welfare$income %in% c(0, 9999)
welfare$income 값이 0이거나 9999인 경우를 검사함.
%in% 연산자는 특정 값이 지정된 값의 집합에 포함되어 있는지 여부를 확인함.
여기서 welfare$income이 0이거나 9999에 해당하면 조건이 참이 됨.
즉, income 값이 0이거나 9999일 경우 이를 결측치로 처리함.
welfare$income
조건이 거짓이면 원래의 income 값을 유지함.
결측치 확인
is.na를 통해 결측치를 확인한다.
table(is.na(welfare$income))
FALSE TRUE
4620 12044 성별에 따른 월급 차이 분석
s_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(s) %>%
summarise(mean_income = mean(income))
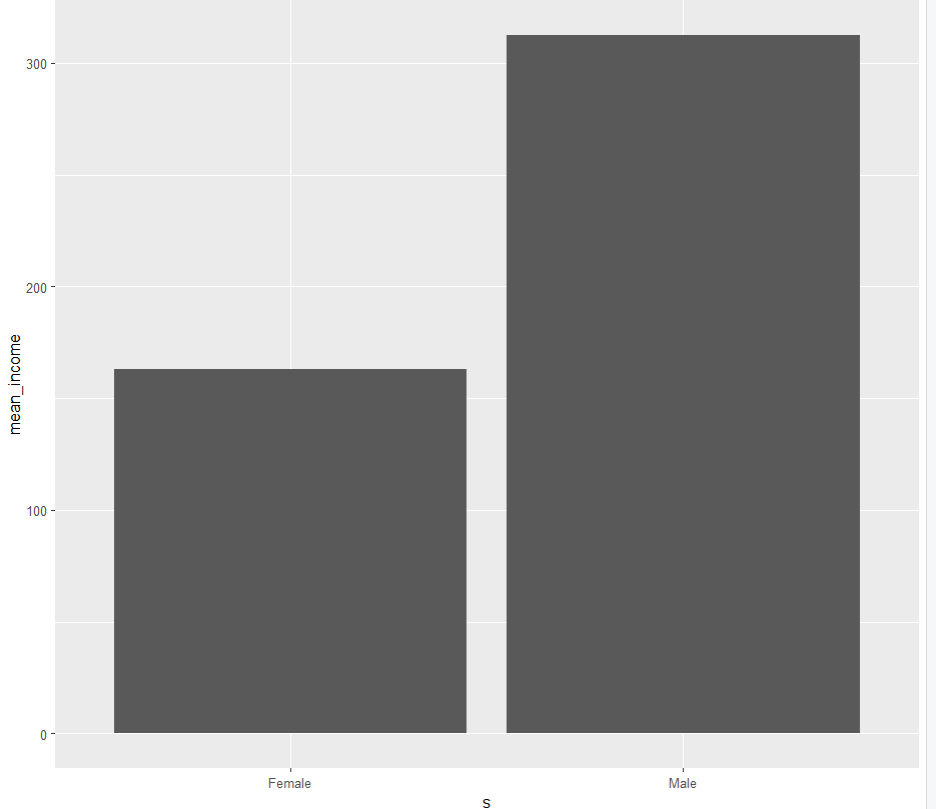
s_income
<chr> <dbl>
1 Female 163.
2 Male 312.그래프 생성
x좌표는 성별, y좌표는 월급 평균값으로 한다.
이를 막대 그래프로 생성한다.
ggplot(data = s_income, aes(x=s, y=mean_income)) +
geom_col()
나이와 월급의 관계 - 몇 살 때 월급을 가장 많이 받을까?
나이 변수 검토 및 전처리
class(welfare$birth)
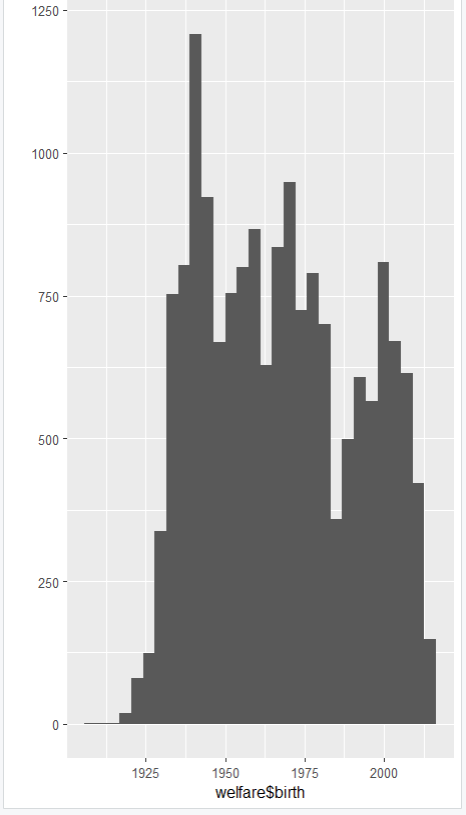
[1] "numeric"summary(welfare$birth) # 이상치 확인
Min. 1st Qu. Median Mean 3rd Qu. Max.
1907 1946 1966 1968 1988 2014
히스토그램을 그린다.
qplot(welfare$birth)
결측치 확인
결측치를 제외한다.
table(is.na(welfare$birth))
FALSE
16664 파생변수 생성 - 나이(age)
welfarebirth + 1
welfare$birth welfare 출생연도를 나타내는 변수.
2015 - welfare$birth + 1는 나이를 계산하는 식.
예를 들어, welfare$birth 값이 1980년이면,
2015 - 1980 + 1 계산으로 나이가 36세가 됨.
+1 더하는 이유
나이를 계산할 때 일반적으로 해당 연도 전체를 포함하기 위해서임.
즉, 2015년에 해당 연령이 몇 번째 해인지를 나타내기 위해 1을 더함.
summary(welfare$age)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.00 28.00 50.00 48.43 70.00 109.00 qplot(welfare$age)
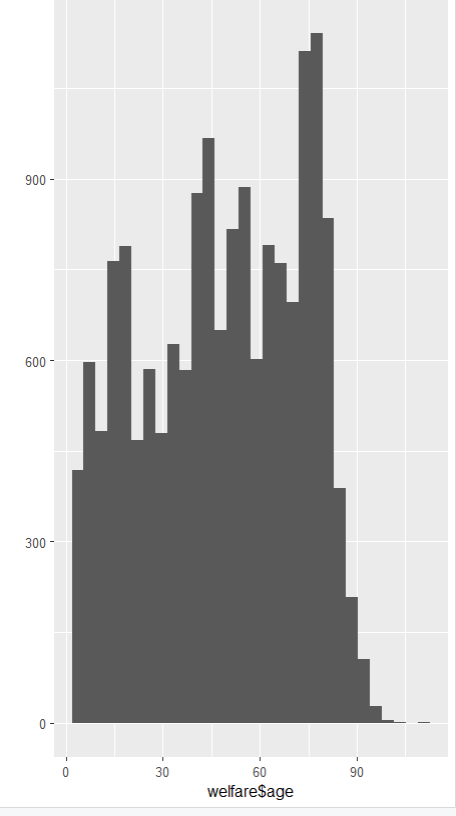
나이와 월급의 관계 분석
age_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(age) %>%
summarise(mean_income = mean(income))
나이 기준으로 월급 평균을 섬머리 해보자.
age_income
<dbl> <dbl>
1 20 121.
2 21 106.
3 22 130.
4 23 142.
5 24 134.
6 25 145.
7 26 158.
8 27 188.
9 28 205.
10 29 189.
# ℹ 59 more rows
# ℹ Use `print(n = ...)` to see more rows그래프 생성
ggplot(data=age_income, aes(x=age, y=mean_income)) +
geom_line(colour = 'skyblue',
size = 2.0,
linetype =1.5)
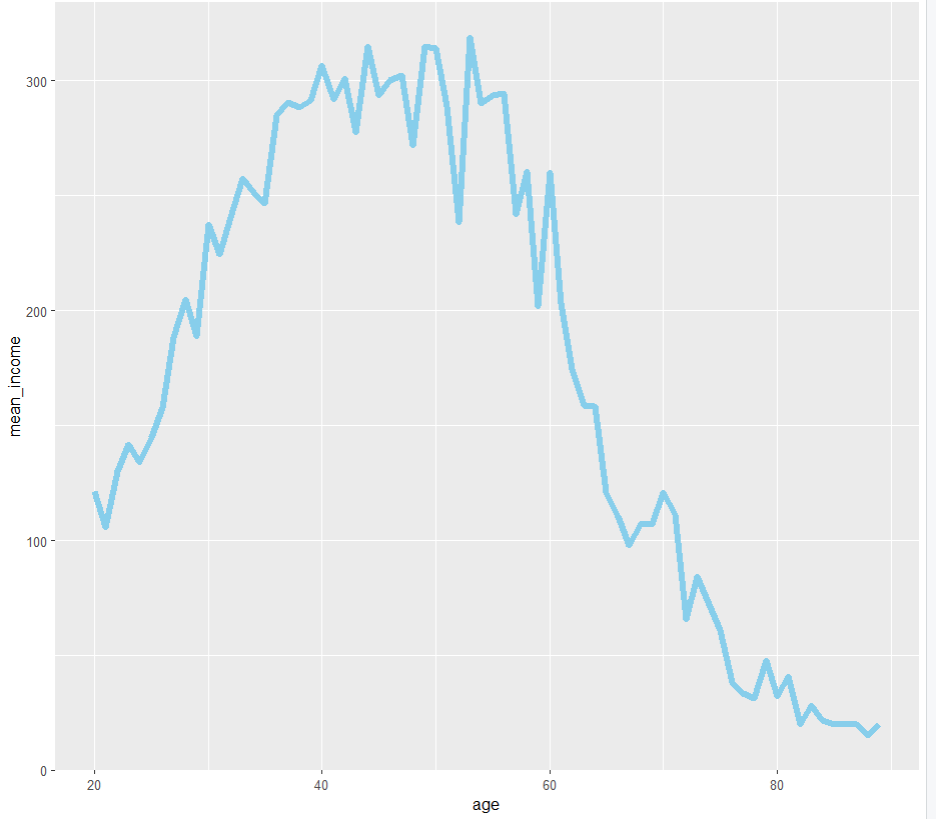
그림을 보면 40대 ~ 60대의 연령대가 가장 월급이 많고
80대 이후가 가장 낮은 것으로 확인할 수 있다.
연령대에 따른 월급 차이
어떤 연령대의 월급이 가장 많을까?
파생변수 - 연령대(ageg)
연령대를 3가지로 구분한다. (미들, 올드, 영)
welfare <- welfare %>%
mutate(ageg = ifelse(age < 30, 'young',
ifelse(age <= 59,'middle','old')))
table(welfare$ageg)
middle old young
6049 6281 4334 연령대에 따른 월급 차이 분석
ageg_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(ageg) %>%
summarise(mean_income = mean(income))
ageg_income
# A tibble: 3 × 2
ageg mean_income
<chr> <dbl>
1 middle 282.
2 old 125.
3 young 164.ggplot(data=ageg_income, aes(x=ageg, y=mean_income)) +
geom_col()
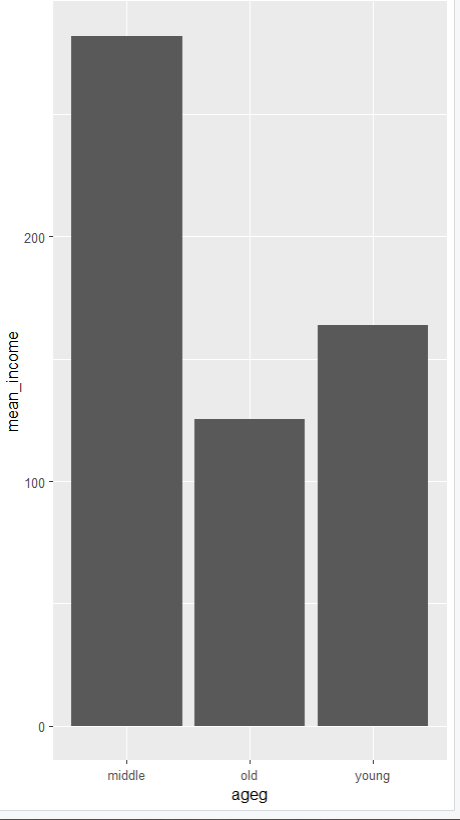
미들 30 ~59 사이 연령대가 월급이 가장 높은 것으로 확인된다.
막대 정렬
ggplot(data=ageg_income, aes(x=ageg, y=mean_income)) +
geom_col() +
scale_x_discrete(limits = c('young','middle','old'))
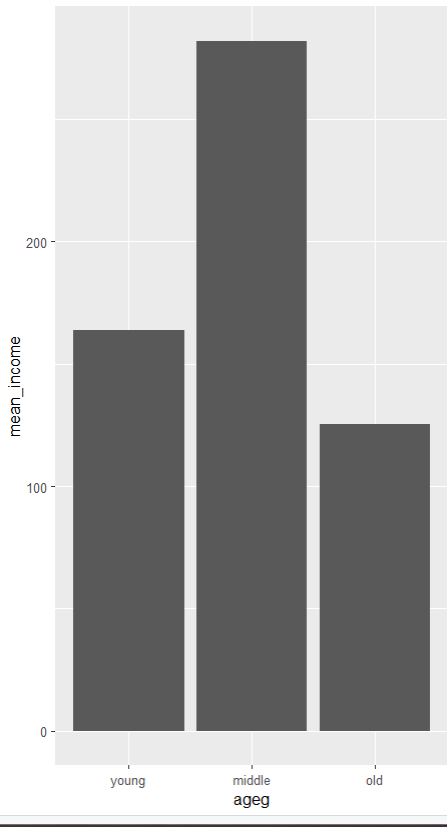
scale_x_discrete() 함수는 x축의 범주형 데이터를 특정 순서로 표시하도록 설정함.
limits = c('young', 'middle', 'old')는 x축에 표시될 값들의 순서를 지정함. 이 순서대로 x축에 연령대가 표시됨.
x축에는 'young' (젊은층), 'middle' (중년층), 'old' (노년층) 순서로 범주가 정렬됨
연령대 및 성별 월급 차이: 성별 월급 차이는 연령대별로 다를까?
연령대 및 성별 월급 평균표 생성
s_income <- welfare %>%
filter(!is.na(income)) %>%
group_by(ageg, s) %>%
summarise(mean_income = mean(income))
s_income
# Groups: ageg [3]
ageg s mean_income
<chr> <chr> <dbl>
1 middle Female 188.
2 middle Male 353.
3 old Female 81.5
4 old Male 174.
5 young Female 160.
6 young Male 171. 그래프 생성
ggplot(data=s_income, aes(x=ageg, y=mean_income, fill=s)) +
geom_col() +
scale_x_discrete(limits = c('young','middle','old'))
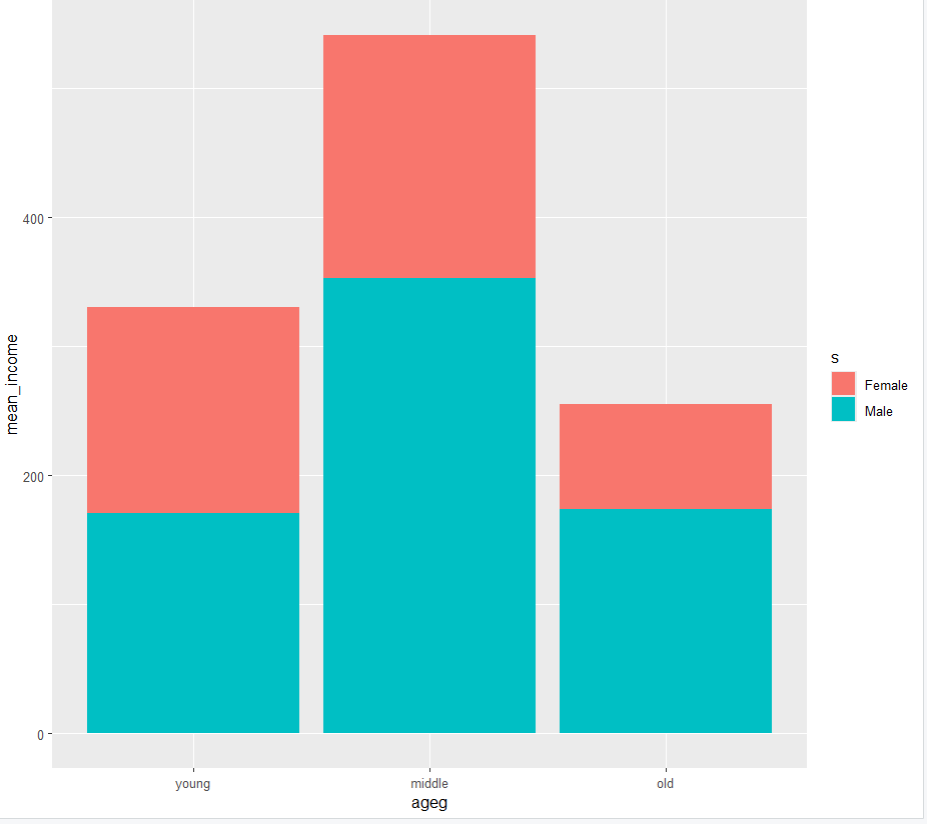
영 -> 미들 -> 올드 순서
성별 막대 분리
ggplot(data=s_income, aes(x=ageg, y=mean_income, fill=s)) +
geom_col(position = 'dodge') +
scale_x_discrete(limits = c('young','middle','old'))
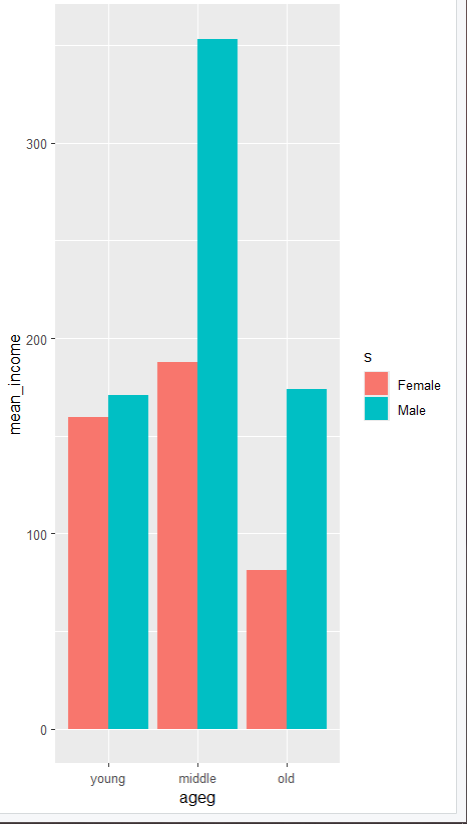
geom_col(position = 'dodge')
position = 'dodge'
옵션을 추가하여 막대가 성별에 따라 옆으로 나란히 배치되도록 설정함.
동일한 연령대에서 성별별 막대가 쌓이지 않고,
옆으로 분리되어 표시됨.
각 연령대에서 남성과 여성의 소득을 비교하기가 더 쉬움.
나이 및 성별 월급 차이 분석
s_age <- welfare %>%
filter(!is.na(income)) %>%
group_by(age, s) %>%
summarise(mean_income = mean(income))
head(s_age)
# A tibble: 6 × 3
# Groups: age [3]
age s mean_income
<dbl> <chr> <dbl>
1 20 Female 147.
2 20 Male 69
3 21 Female 107.
4 21 Male 102.
5 22 Female 140.
6 22 Male 118.그래프 생성
ggplot(data=s_age, aes(x=age, y=mean_income, col=s)) +
geom_line(size=2.0)
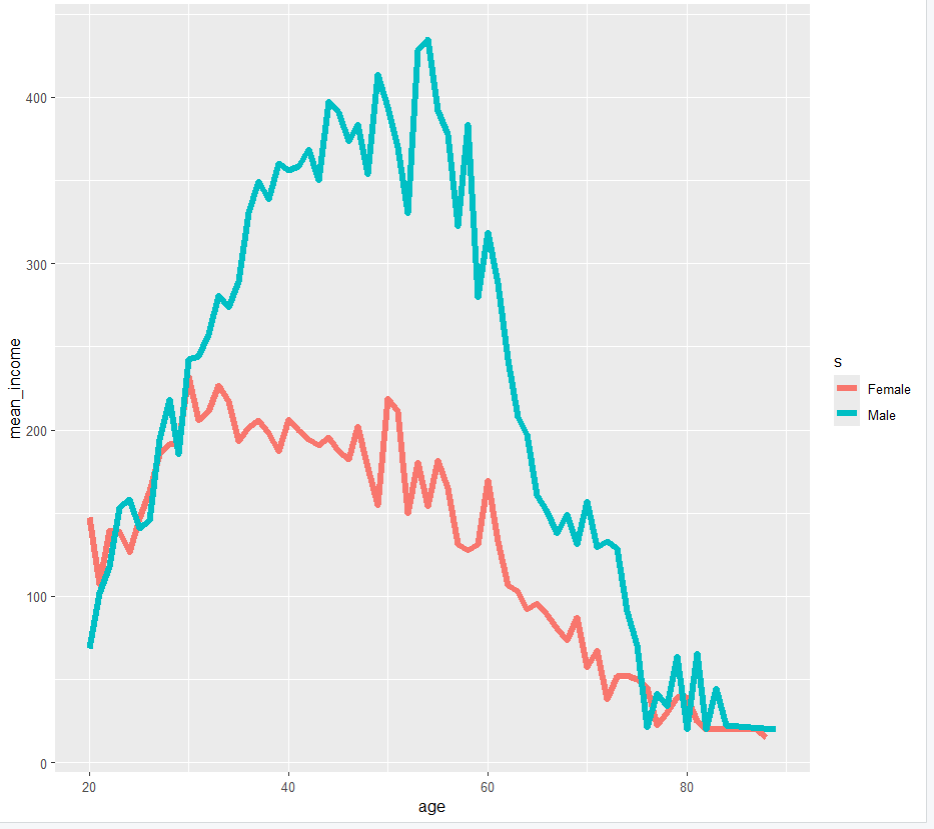
직업별 월급 차이: 어떤 직업이 돈을 가장 많이 버는가?
class(welfare$code_job)
[1] "numeric"table(welfare$code_job)
데이터 전처리
(직업 분류 시트 불러오기 , left_join())
list_job <- read_excel('Koweps_Codebook.xlsx',
col_names = T,
sheet = 2)
welfare <- left_join(welfare, list_job, by='code_job')
welfare %>%
filter(!is.na(code_job)) %>%
select(code_job, job) %>%
head(10)
code_job job
1 942 경비원 및 검표원
2 762 전기공
3 530 방문 노점 및 통신 판매 관련 종사자
4 999 기타 서비스관련 단순 종사원
5 312 경영관련 사무원
6 254 문리 기술 및 예능 강사
7 510 영업 종사자
8 530 방문 노점 및 통신 판매 관련 종사자
9 286 스포츠 및 레크레이션 관련 전문가
10 521 매장 판매 종사자직업별 월급 차이 분석
job_income <- welfare %>%
filter(!is.na(job) & !is.na(income)) %>%
group_by(job) %>%
summarise(mean_income = mean(income))
head(job_income)
# A tibble: 6 × 2
job mean_income
<chr> <dbl>
1 가사 및 육아 도우미 80.2
2 간호사 241.
3 건설 및 광업 단순 종사원 190.
4 건설 및 채굴 기계운전원 358.
5 건설 전기 및 생산 관련 관리자 536.
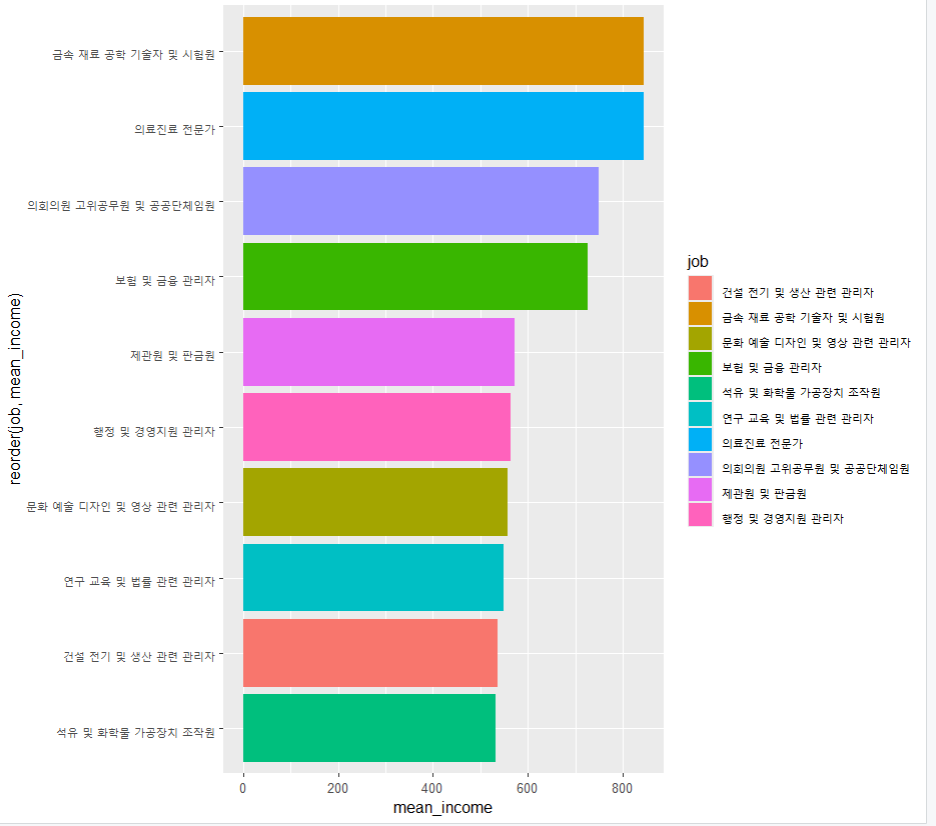
6 건설관련 기능 종사자 247. 상위 10개 추출
정렬(내림차순)해서 헤드 10개만 추출한다.
top10 <- job_income %>%
arrange(desc(mean_income)) %>%
head(10)
top10
# A tibble: 10 × 2
job mean_income
<chr> <dbl>
1 금속 재료 공학 기술자 및 시험원 845.
2 의료진료 전문가 844.
3 의회의원 고위공무원 및 공공단체임원 750
4 보험 및 금융 관리자 726.
5 제관원 및 판금원 572.
6 행정 및 경영지원 관리자 564.
7 문화 예술 디자인 및 영상 관련 관리자 557.
8 연구 교육 및 법률 관련 관리자 550.
9 건설 전기 및 생산 관련 관리자 536.
10 석유 및 화학물 가공장치 조작원 532.그래프 생성
ggplot(data=top10, aes(x=reorder(job, mean_income), y=mean_income, fill=job)) +
geom_col() +
coord_flip() # 그래프를 돌려주는 옵션
성별 직업 빈도 분석: 성별로 어떤 직업이 가장 많은가?
성별 직업 빈도표 생성
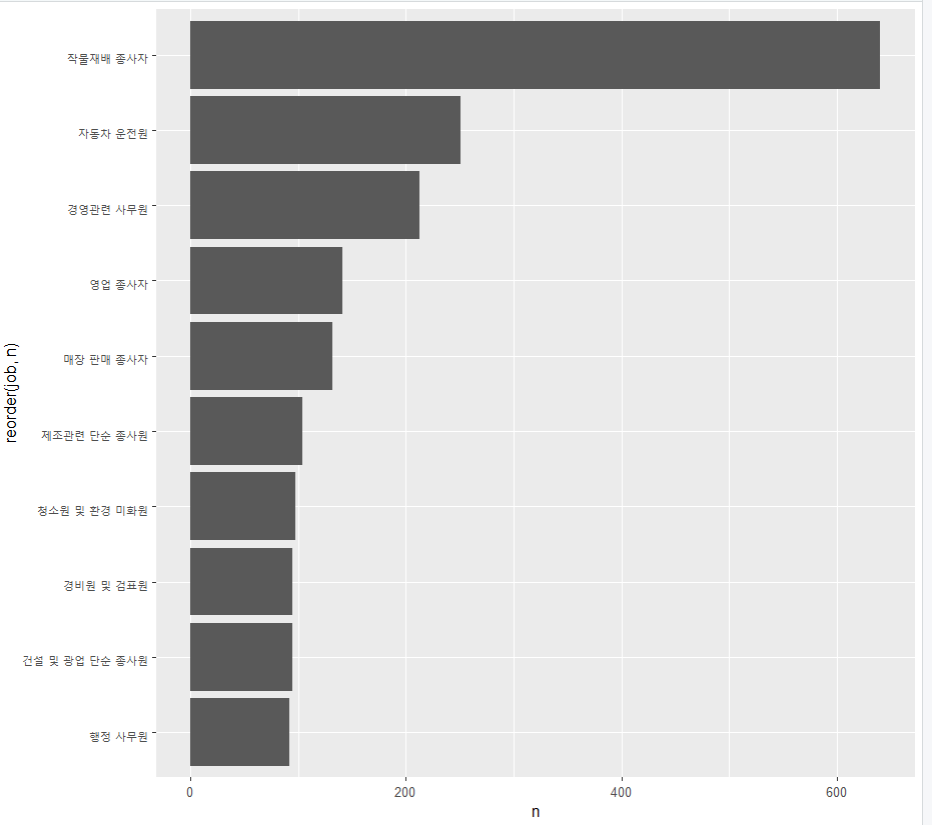
1. 남성 직업 빈도 상위 10개 추출
job_male <- welfare %>%
filter(!is.na(job) & s == 'Male') %>%
group_by(job) %>%
summarise(n = n()) %>%
arrange(desc(n)) %>%
head(10)
job_male
# A tibble: 10 × 2
job n
<chr> <int>
1 작물재배 종사자 640
2 자동차 운전원 251
3 경영관련 사무원 213
4 영업 종사자 141
5 매장 판매 종사자 132
6 제조관련 단순 종사원 104
7 청소원 및 환경 미화원 97
8 건설 및 광업 단순 종사원 95
9 경비원 및 검표원 95
10 행정 사무원 92n = n(): 각 직업별로 데이터의 개수를 세어 n이라는 변수에 저장함. 이 변수는 해당 직업에 속한 남성의 수를 나타냄.
arrange(desc(n)):
arrange() 함수는 데이터를 정렬함.
desc(n): n 변수를 기준으로 내림차순으로 정렬함.
즉, 빈도가 높은 직업이 상위에 오도록 정렬함.
2. 여성 직업 빈도 상위 10개 추출
job_female <- welfare %>%
filter(!is.na(job) & s == 'Female') %>%
group_by(job) %>%
summarise(n = n()) %>%
arrange(desc(n)) %>%
head(10)
job_female
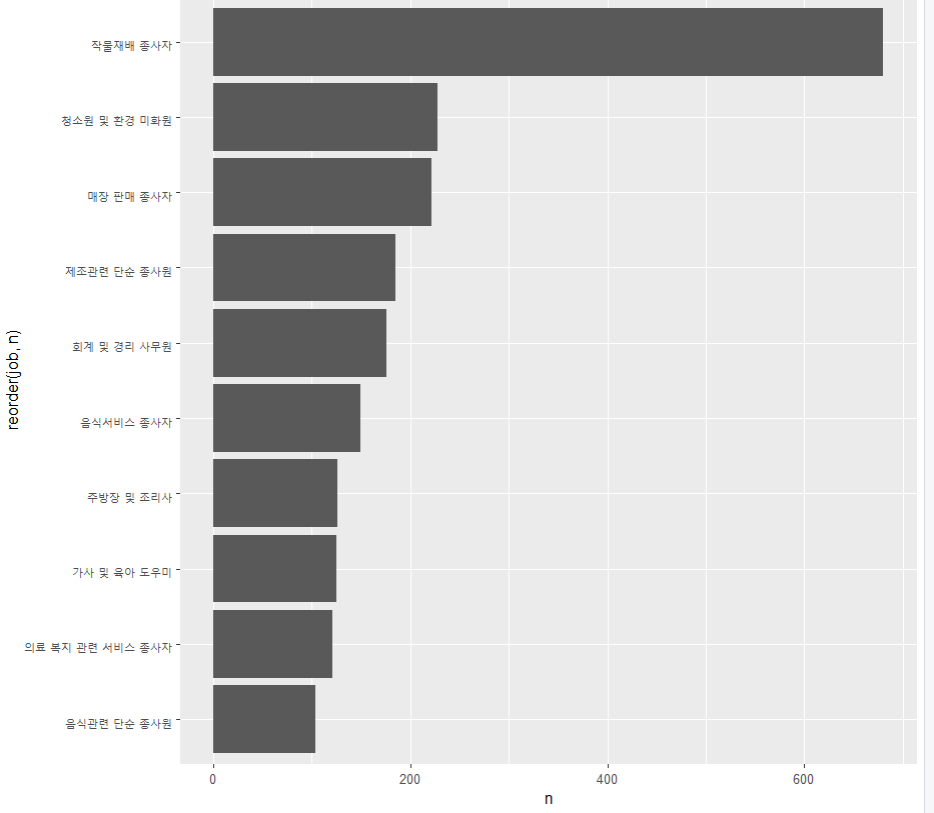
job n
<chr> <int>
1 작물재배 종사자 680
2 청소원 및 환경 미화원 228
3 매장 판매 종사자 221
4 제조관련 단순 종사원 185
5 회계 및 경리 사무원 176
6 음식서비스 종사자 149
7 주방장 및 조리사 126
8 가사 및 육아 도우미 125
9 의료 복지 관련 서비스 종사자 121
10 음식관련 단순 종사원 104그래프 생성(남자/여자)
남자의 직업 막대 그래프
ggplot(data=job_male, aes(x=reorder(job, n), y=n)) +
geom_col() +
coord_flip()
여자의 막대 직업 그래프
ggplot(data=job_female, aes(x=reorder(job, n), y=n)) +
geom_col() +
coord_flip()