[파이썬 기반 통계 활용 실습] 가우시안 분포
전체 코드
from scipy import stats
import numpy as np
import matplotlib.pyplot as plt
# 정규 분포 객체 생성
mu = 0
sigma = 1
rv = stats.norm(mu, sigma)
# 확률 밀도 함수(PDF) 시각화
x = np.linspace(-3, 3, 100)
plt.plot(x, rv.pdf(x))
plt.show()
1. 라이브러리 임포트
from scipy import stats
import numpy as np
import matplotlib.pyplot as plt
2. 정규 분포 객체 생성
mu = 0
sigma = 1
rv = stats.norm(mu, sigma)
mu = 0: 평균은 0입니다.
sigma = 1: 표준 편차는 1입니다.
rv = stats.norm(mu, sigma): 평균이 0이고 표준 편차가 1인 정규 분포 객체 rv를 생성합니다.
3. 확률 밀도 함수(PDF) 시각화
x = np.linspace(-3, 3, 100)
plt.plot(x, rv.pdf(x))
plt.show()x = np.linspace(-3, 3, 100): -3부터 3까지 100개의 균등한 값을 생성합니다.
이는 X축의 범위를 설정합니다.
rv.pdf(x): 정규 분포의 확률 밀도 함수(PDF)를 계산합니다.
plt.plot(x, rv.pdf(x)): X축 값에 대해 PDF 값을 플롯합니다.
plt.show(): 그래프를 화면에 표시합니다.
[파이썬 기반 통계 활용 실습] 가우시안 분포 결과 해석
X축 (값):
X축은 -3부터 3까지의 값을 나타냅니다.
이는 정규 분포의 범위를 설정합니다.
Y축 (확률 밀도):
Y축은 해당 값에서의 확률 밀도 값을 나타냅니다.
그래프 (정규 분포 곡선):
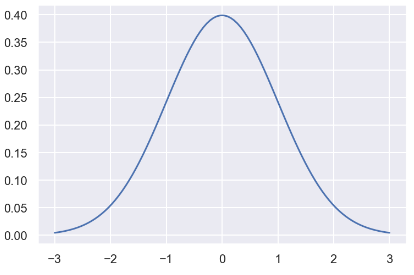
그래프는 평균이 0이고 표준 편차가 1인 정규 분포의 확률 밀도 함수를 나타냅니다.
종 모양의 대칭적인 곡선을 그리며, 중심에 평균(0)이 위치합니다.
곡선의 폭은 표준 편차(1)에 의해 결정됩니다.
대부분의 값(약 68%)이 평균에서 표준 편차 내에 분포합니다.
가우시안 분포의 특성
-
대칭성: 정규 분포는 평균을 중심으로 좌우 대칭입니다. -
중심 극한 정리: 많은 독립적인 랜덤 변수들의 합이 정규 분포를 따르게 되는 경향이 있습니다. -
68-95-99.7 규칙: 평균 ± 1σ, 2σ, 3σ 내에 각각 약 68%, 95%, 99.7%의 데이터가 존재합니다.
이 코드는 평균이 0 이고
표준 편차가 1 인 정규 분포의 확률 밀도 함수를 시각화합니다.
정규분포
정규 분포는 종 모양 의 대칭적인 곡선을 가지며,
데이터가 평균 주위에 어떻게 분포하는지를 잘 나타냅니다.
[파이썬 기반 통계 활용 실습] 가우시안 분포 KDE(Kernel Density Estimation)
전체 코드
from scipy import stats
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 정규 분포 객체 생성
mu = 0
sigma = 1
rv = stats.norm(mu, sigma)
# 100,000개의 샘플 생성 및 KDE 시각화
n_sim = 100000
samples = rv.rvs(n_sim)
sns.kdeplot(samples)
plt.show()
1. 라이브러리 임포트
from scipy import stats
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt2. 정규분포 객체 생성
mu = 0
sigma = 1
rv = stats.norm(mu, sigma)mu = 0: 평균은 0입니다.
sigma = 1: 표준 편차는 1입니다.
rv = stats.norm(mu, sigma): 평균이 0이고 표준 편차가 1인 정규 분포 객체 rv를 생성합니다.
3.샘플 생성 및 KDE 시각화
n_sim = 100000
samples = rv.rvs(n_sim)
sns.kdeplot(samples)
plt.show()n_sim = 100000: 100,000개의 샘플을 생성합니다.
samples = rv.rvs(n_sim): 정규 분포를 따르는 100,000개의 샘플을 생성합니다.
sns.kdeplot(samples): 샘플 데이터를 커널 밀도 추정(KDE)으로 시각화합니다.
plt.show(): 그래프를 화면에 표시합니다.
[파이썬 기반 통계 활용 실습] 가우시안 분포 KDE 결과 해석
KDE (Kernel Density Estimation)
KDE는 데이터의 분포를 부드럽게 추정하는 방법입니다.
히스토그램보다 더 매끄럽고 연속적인 곡선을 생성합니다.
KDE는 각 데이터 포인트 주위에 커널 함수 를 놓고,
모든 커널 함수의 합 으로 밀도를 추정합니다.
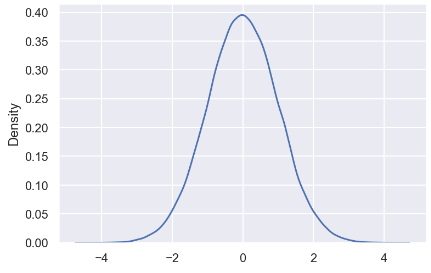
그래프 해석
X축 (값의 범위)
X축은 -4 부터 4 까지의 값을 나타냅니다.
이는 정규 분포에서 샘플링된 값들의 범위를 나타내며,
중앙값인 0을 기준으로 좌우 대칭적인 분포 를 보여줍니다.
Y축 (밀도)
Y축은 확률 밀도(Density) 를 나타냅니다.
밀도 값 은 주어진 X값에서 데이터가 존재할 확률을 나타냅니다.
Y축의 최대 값은 약 0.4로,
이는 평균(0) 근처에서 가장 높은 밀도를 가집니다.
커널 밀도 추정(KDE) 곡선
그래프는 부드럽고 연속적인 종 모양 의 곡선을 그립니다.
KDE 곡선 은 샘플 데이터의 분포를 부드럽게 추정하여,
히스토그램보다 매끄러운 분포를 나타냅니다.
중심이 0인 대칭적인 형태를 가지며,
샘플 데이터가 평균이 0인 정규 분포를 따르고 있습니다.
그래프 특징
이 그래프는 평균이 0이고 표준 편차가 1인 정규 분포 에서 샘플링된 데이터의 커널 밀도 추정 결과를 시각화한 것입니다.
데이터가 정규 분포를 잘 따르고 있으며,
중심이 0인 대칭적인 종 모양 의 곡선을 보여줍니다.
샘플 데이터가 실제로 정규 분포를 따르고 있습니다.
샘플 생성 시간 측정하기
%%timeit 매직 명령어를 사용하여 두 가지 방법으로 100개의 정규 분포 샘플을 생성하는 데 걸리는 시간을 측정합니다.
방법1: scipy.stats를 사용하여 샘플 생성
n_sim = 100
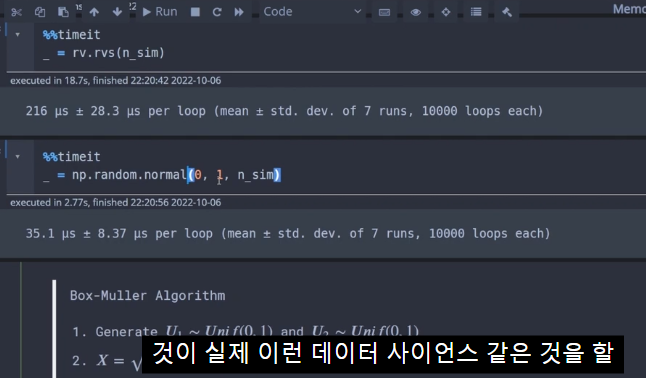
%%timeit
_ = rv.rvs(n_sim)rv = stats.norm(0, 1): 평균이 0이고 표준 편차가 1인 정규 분포 객체를 생성합니다.
n_sim = 100: 100개의 샘플을 생성합니다.
rv.rvs(n_sim): scipy.stats.norm 객체에서 100개의 샘플을 생성합니다.
%%timeit: 주피터 노트북에서 사용할 수 있는 매직 명령어로, 코드 셀의 실행 시간을 측정합니다.
_: 생성된 샘플을 변수에 할당하지만, 실제로는 사용하지 않습니다.
216 µs ± 28.3 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)100개의 샘플을 생성하는 데
평균 216 마이크로초가 걸리며,
표준 편차는 28.3 마이크로초가 걸립니다.
(7번의 실행에서 10,000 번 루프를 돌린 결과라는 것입니다.)
방법2: numpy를 사용하여 샘플 생성
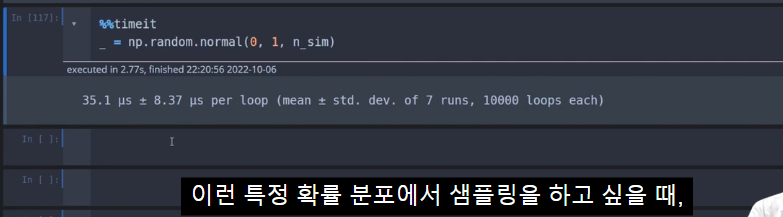
%%timeit
_ = np.random.normal(0, 1, n_sim)np.random.normal(0, 1, n_sim) : 평균이 0이고 표준 편차가 1인 정규 분포에서 100개의 샘플을 numpy를 사용하여 생성합니다.
%%timeit : 주피터 노트북에서 사용할 수 있는 매직 명령어로, 코드 셀의 실행 시간을 측정합니다.
_: 생성된 샘플을 변수에 할당하지만, 실제로는 사용하지 않습니다.
35.1 µs ± 8.37 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
numpy를 사용하여 샘플을 생성한 결과
100개의 샘플을 생성하는 데
평균 35.1 마이크로초가 걸리며,
표준 편차는 8.37 마이크로초임을 나타냅니다.
(7번의 실행에서 10,000번 루프를 돌린 결과입니다.)
결과 비교
성능 차이
scipy.stats.norm을 사용하여 샘플을 생성하는 데 평균 216 마이크로초가 걸립니다.
numpy.random.normal을 사용하여 샘플을 생성하는 데 평균 35.1 마이크로초가 걸립니다.
반면, numpy를 사용한 방법이 scipy.stats를 사용한 방법보다 훨씬 빠릅니다.
표준 편차
scipy.stats.norm의 표준 편차는 28.3 마이크로초로,
numpy의 표준 편차 8.37 마이크로초보다 큽니다.
scipy.stats.norm 방법이 성능이 더 변동성이 있다는 것을 알 수 있습니다.
성능과 효율성
따라서 성능 면에서는
numpy.random.normal을 사용하여 정규 분포 샘플을 생성하는 방법이 scipy.stats.norm을 사용하는 방법보다 훨씬 빠릅니다.
효율성 측면에서는 numpy가 대규모 데이터 처리를 위한 고성능 라이브러리로, 샘플 생성 시에도 더 효율적입니다.
*해당 강의는 메타코드 서포터즈로서 작성하게 되었습니다.

