씨본(Seaborn) 소개
Seaborn은 파이썬에서 통계적 그래픽을 만드는 라이브러리이다.
Matplotlib을 기반으로 하여 더 간단하고 세련된 시각화 기능을 제공한다.
매핑과 통계적 집계를 수행하여 정보적인 플롯을 생성한다.
API를 사용하면 더 다양하게 이용할 수 있다.
1. 산점도 생성하기
# Import seaborn
import seaborn as sns
# Apply the default theme
sns.set_theme()
# Load an example dataset
tips = sns.load_dataset("tips")
# Create a visualization
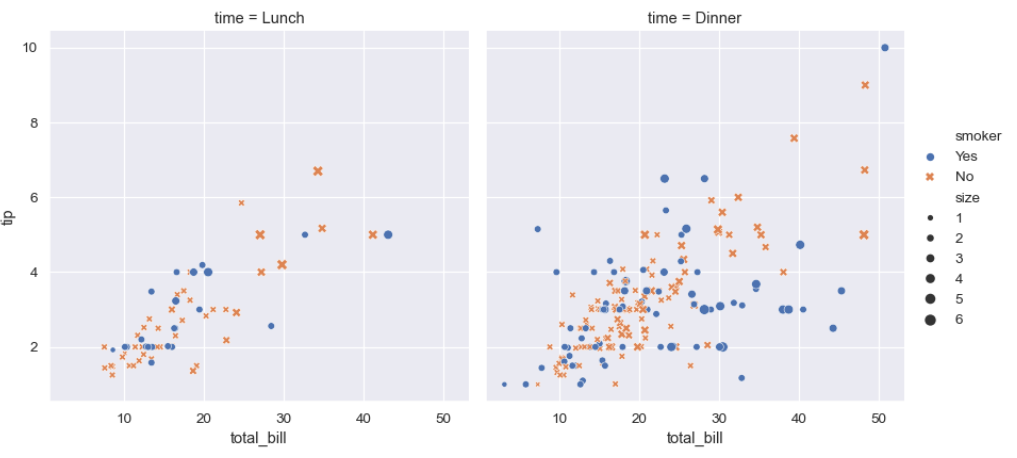
sns.relplot(
data=tips,
x="total_bill", y="tip", col="time",
hue="smoker", style="smoker", size="size",
)
import seaborn as sns
seaborn 라이브러리를 sns라는 이름으로 임포트한다.
sns.set_theme()
테마는 그래프의 스타일과 미관을 설정하는데,
set_theme()를 호출하면 기본적인 스타일이 설정된다.
tips = sns.load_dataset("tips")
tips라는 예제 데이터를 불러온다.
tips 데이터셋은 식사 비용과 팁, 식사 시간, 흡연 여부 등의 정보를 포함하고 있다.
sns.relplot(data=tips, x="total_bill", y="tip", col="time", hue="smoker", style="smoker", size="size")
sns.relplot 함수는 관계형 플롯을 생성하는 함수이다.
여기서는 산점도를 생성한다.
매개변수
data=tips: tips 데이터셋을 사용한다.
x="total_bill": x축에 total_bill(전체 식사 비용) 값을 사용한다.
y="tip": y축에 tip(팁) 값을 사용한다.
col="time": time(식사 시간) 열의 값에 따라 그래프를 열 방향으로 분할한다.
time은 점심과 저녁을 나타낸다.
hue="smoker": smoker(흡연 여부) 값에 따라 점의 색상을 다르게 설정한다.
style="smoker": smoker 값에 따라 점의 스타일(모양)을 다르게 설정한다.
size="size": size(일행의 크기) 값에 따라 점의 크기를 다르게 설정한다.
2. API 관련
dots = sns.load_dataset("dots")
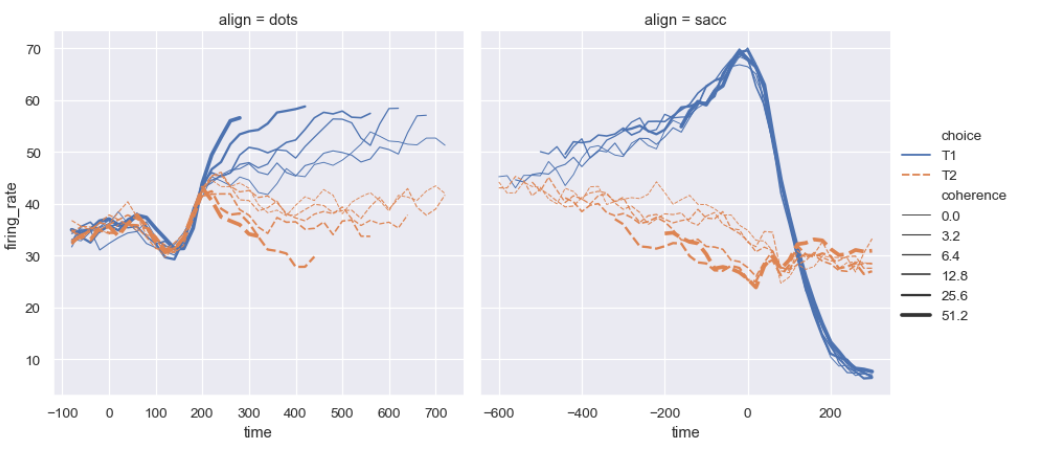
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate", col="align",
hue="choice", size="coherence", style="choice",
facet_kws=dict(sharex=False),
)dots = sns.load_dataset("dots")
dots 데이터셋은 실험 중 특정 조건 하에서의 신경 활동 데이터를 포함하고 있다.
sns.relplot(data=dots, kind="line", x="time", y="firing_rate", col="align", hue="choice", size="coherence", style="choice", facet_kws=dict(sharex=False))
sns.relplot 함수를 통해 선 그래프를 생성한다.
매개변수
data=dots: dots 데이터셋을 사용한다.
kind="line": 라인 플롯(line plot)을 생성한다.
x="time": x축에 time 값을 사용한다.
y="firing_rate": y축에 firing_rate(발화율) 값을 사용한다.
col="align": align 열의 값에 따라 그래프를 열 방향으로 분할한다.
hue="choice": choice 값에 따라 선의 색상을 다르게 설정한다.
size="coherence": coherence 값에 따라 선의 두께를 다르게 설정한다.
style="choice": choice 값에 따라 선의 스타일(모양)을 다르게 설정한다.
facet_kws=dict(sharex=False): 각 서브 플롯의 x축을 독립적으로 설정한다.
(서브 플롯 간에 x축 눈금이 공유되지 않는다.)
3. 통계적 추정
fmri = sns.load_dataset("fmri")
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", col="region",
hue="event", style="event",
)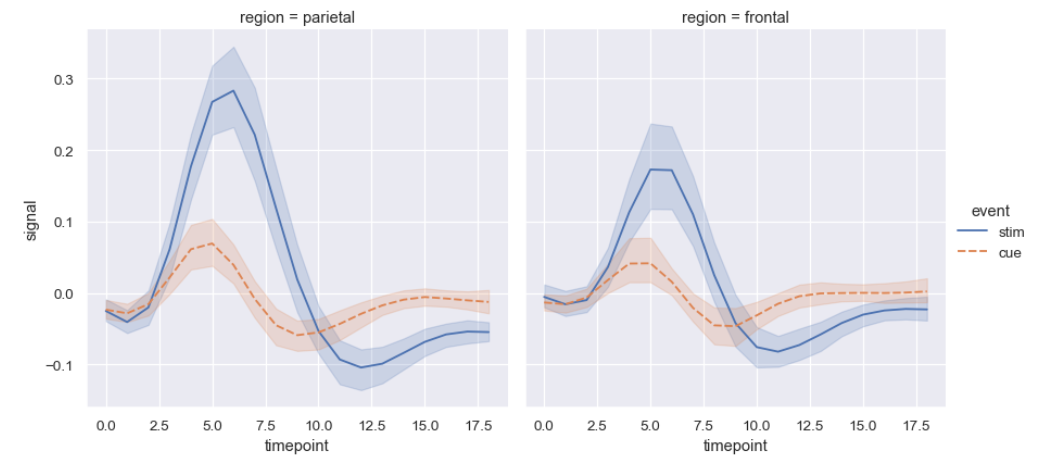
fmri = sns.load_dataset("fmri")
fmri 데이터셋은 기능적 자기공명영상(fMRI) 데이터를 포함하고 있다.
sns.relplot(data=fmri, kind="line", x="timepoint", y="signal", col="region", hue="event", style="event")
매개변수
data=fmri: fmri 데이터셋을 사용한다.
kind="line": 라인 플롯(line plot)을 생성한다.
x="timepoint": x축에 timepoint(시간 점) 값을 사용한다.
y="signal": y축에 signal(신호) 값을 사용한다.
col="region": region(뇌의 부위) 열의 값에 따라 그래프를 열 방향으로 분할한다.
hue="event": event(사건) 값에 따라 선의 색상을 다르게 설정한다.
style="event": event 값에 따라 선의 스타일(모양)을 다르게 설정한다.
4. 데이터셋의 변수 분포
sns.displot(data=tips, x="total_bill", col="time", kde=True)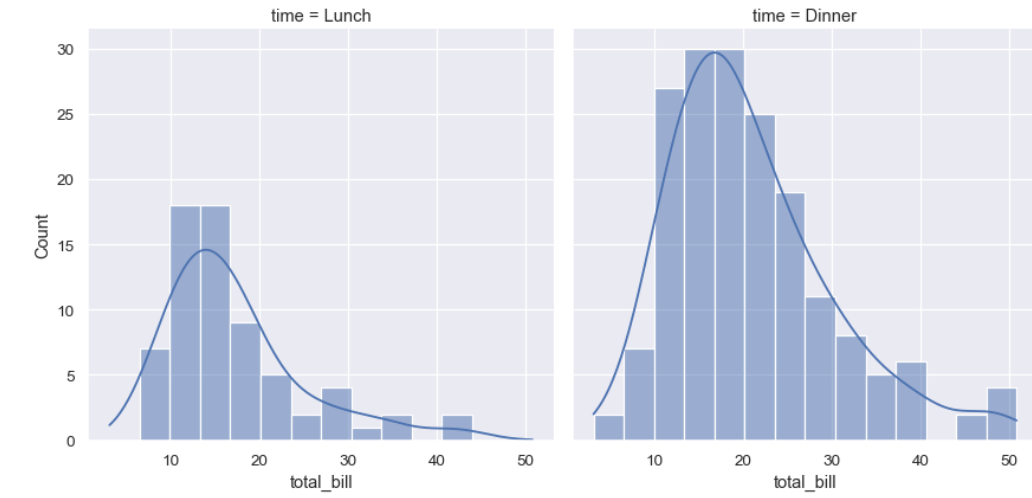
sns.displot(data=tips, x="total_bill", col="time", kde=True)
sns.displot 함수는 데이터의 분포를 시각화하는 함수이다.
여기서는 히스토그램을 생성한다.
매개변수
data=tips: tips 데이터셋을 사용한다.
x="total_bill": x축에 total_bill(총 청구서 금액) 값을 사용한다.
col="time": time(식사 시간) 열의 값에 따라 그래프를 열 방향으로 분할한다.
점심과 저녁에 대해 각각 별도의 히스토그램을 생성한다.
kde=True: 커널 밀도 추정(KDE)을 히스토그램 위에 추가하여 데이터의 밀도를 부드러운 곡선으로 시각화한다.
5. 범주형 데이터 시각화
sns.catplot(data=tips, kind="swarm", x="day", y="total_bill", hue="smoker")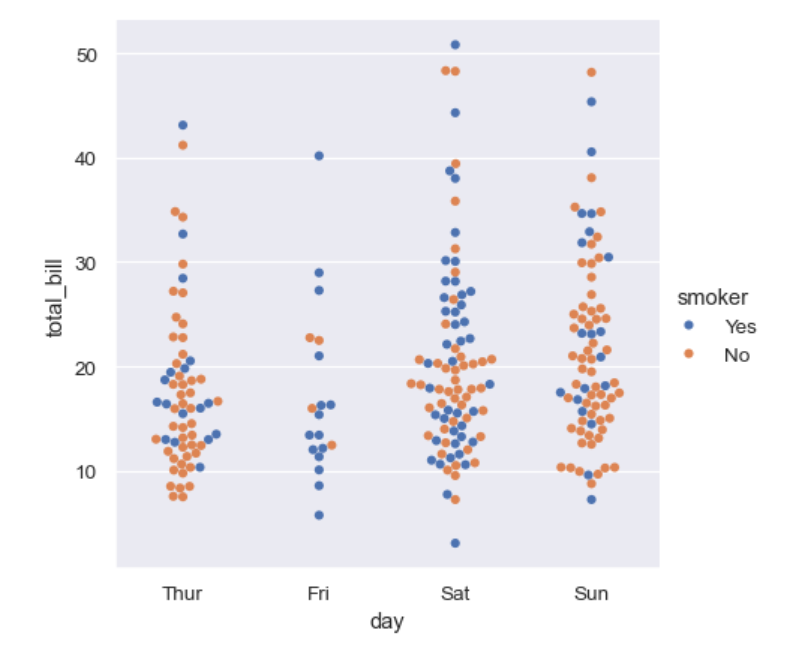
sns.catplot(data=tips, kind="swarm", x="day", y="total_bill", hue="smoker")
sns.catplot 함수는 범주형 데이터를 시각화하는 여러 가지 종류의 플롯을 생성할 수 있다.
매개변수:
data=tips: tips 데이터셋을 사용한다.
kind="swarm": 스웜 플롯(swarm plot)을 생성한다.
x="day": x축에 day(요일) 값을 사용한다.
y="total_bill": y축에 total_bill(총 청구서 금액) 값을 사용한다.
hue="smoker": smoker(흡연 여부) 값에 따라 점의 색상을 다르게 설정한다.
