파이썬
1.[파이썬 판다스] 데이터프레임
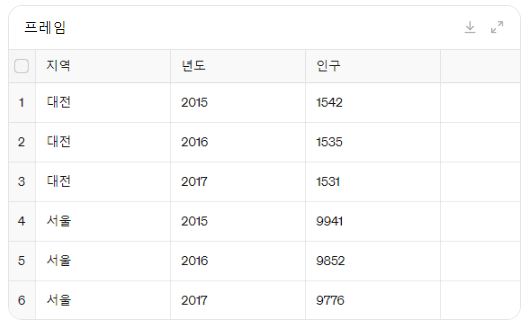
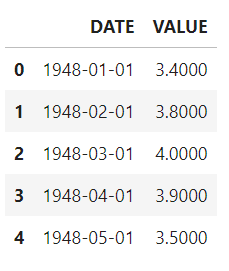
데이터프레임(DataFrame)의 정의\-데이터프레임은 같은 크기의 자료들로 이루어진 열들을 차례로 모아 놓은 직사각 모양의 자료형\-데이터프레임의 열과 행은 각각 인덱스를 가지고 있음 데이터프레임을 만드는 방법\*\*같은 크기의 리스트 또는 넘파이 배열을 값으로 갖는
2.[파이썬 판다스] 항목 제거와 슬라이싱

파이썬 판다스 축으로부터 항목 제거1.시리즈: 축으로부터 항목 제거: drop 메소드시리즈를 만든다.a 0b 1c 2d 3e 4dtype: int64새로운 시리즈(이름: 새시)를 만든다.여기서 c행을 드랍한다.a, c행을 드랍한다.b 1
3.[파이썬 판다스] 함수 사용과 대응

판다스는 넘파이 범용함수(ufunc; 성분끼리 연산)를 사용할 수 있다.이런 출력이 나온다.시드 값 1234를 사용하여 랜덤 상태 객체 rng를 생성해보자.이 객체를 사용하면 재현 가능한 랜덤 숫자 생성을 할 수 있다.표준 정규분포에서 12개의 랜덤 숫자를 생성한다..
4.[파이썬 판다스] 정렬

정렬 및 순위(Sorting and Ranking)행 또는 열이름에 대해서 자료를 정렬하려면 sort_index 메소드를 사용하면 된다.np.arange(3 \* 4)는 0부터 11까지의 숫자를 생성합니다..reshape(3, 4)는 이 숫자들을 3x4 형태의 배열로
5.[파이썬 판다스] 중복 인덱스, 기술통계량
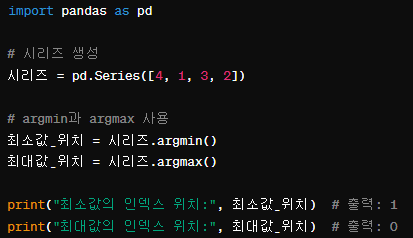
reindex와 같이 대부분의 메소드들은 열, 행이름들이 유일해야하지만 필수는 아니다. 다음과 같이 시리즈의 인덱스이름으로 중복된 이름 a를 가질 수 있다.중복된 이름에 대한 반환값은 다음과 같이 시리즈형이고 중복되지 않은 인덱스 이름의 반환값은 스칼라임을 알 수 있다
6.[파이썬 판다스] 상관계수와 공분산
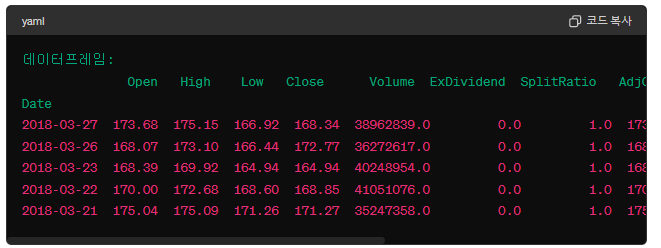
증권 자료를 pandas-datareader 패키지를 이용해서 내려받을 수 있다. pandas_datareader 모듈을 이용해서 4개 회사 거래 자료를 내려받는다.미리 저장된 파일을 다음 사이트에서 내려받아 사용한다.내려받은 자료 구조를 살펴보자. all_data의
7.[파이썬 판다스] 빈도수, 포함관계, 유일값

시리즈에서 값에 대한 정보를 추출하는 메소드들에 대해서 살펴보자. 다음과 같은 시리즈를 만들자.시리즈 값들 중 유일한 값들을 unique 메소드를 이용해서 찾아내자.value_counts 메소드를 이용해 값들에 대한 빈도수를 찾을 수 있다.판다스 함수를 이용해서도 빈도
8.[파이썬 판다스] 시리즈
판다스는 파이썬에서 자료 정제 및 분석을 빠르고 쉽게 할 수 있는 자료 구조와 관리 도구들을 가지고 있다. NumPy, SciPy자료 분석 라이브러리: statsmodels, scikit-learn시각화 도구: matplotlib판다스는 NumPy 에서 사용되는 배열
9.[파이썬 판다스] 인덱스 객체와 리인덱스

0\. 인덱스 객체(Index Objects)Pandas에서 데이터의 행이나 열을 식별하는 레이블을 저장하는 객체이다.시리즈(Series)나 데이터프레임(DataFrame)에서 각각의 데이터 요소를 고유하게 식별할 수 있도록 도와준다.축 라벨과 축 이름을 관리할 수 있
10.[파이썬] 경로 & 파일 호출
user 폴더가 있으니 경로 설정 시 주의해야 한다.해당 주소를 path에 담는다.그리고 경로를 변경한다.다시 경로를 확인한다.판다스라이브러리 임포트를 한다.pd는 pandas 라이브러리를 간단히 사용하기 위한 별칭이다.pd.read_csv 함수는 CSV 파일을 읽어와
11.실행 창으로 주피터 랩 여는 방법
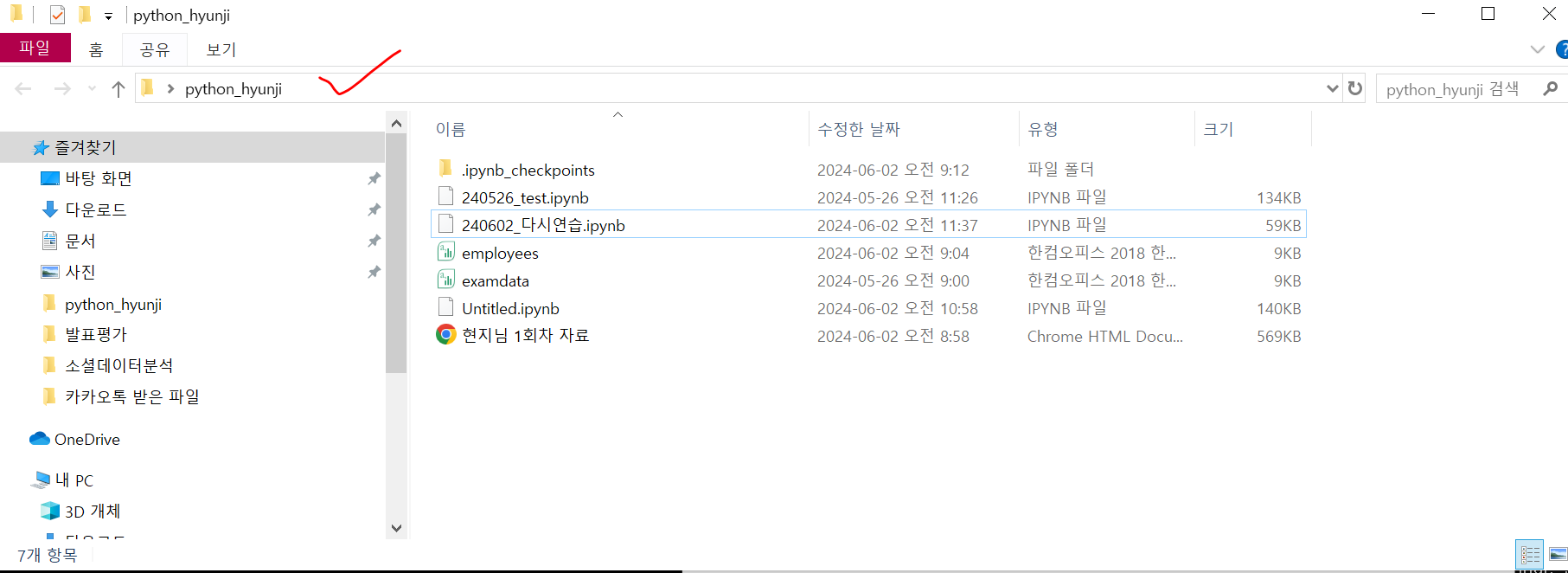
해당 내용은 주피터 랩이 먼저 설치되어 있다는 것을 가정한다.사진과 같이 바탕화면에 폴더를 생성하고 파일들을 이 폴더에 넣어놨다.주소창에 cmd 를 입력한다.커맨드 창이 뜨면 jupyter lab 을 입력한다.하단의 Or copy and paste one of the
12.[파이썬 판다스] 특정 기준으로 조회/집계
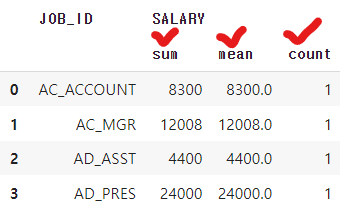
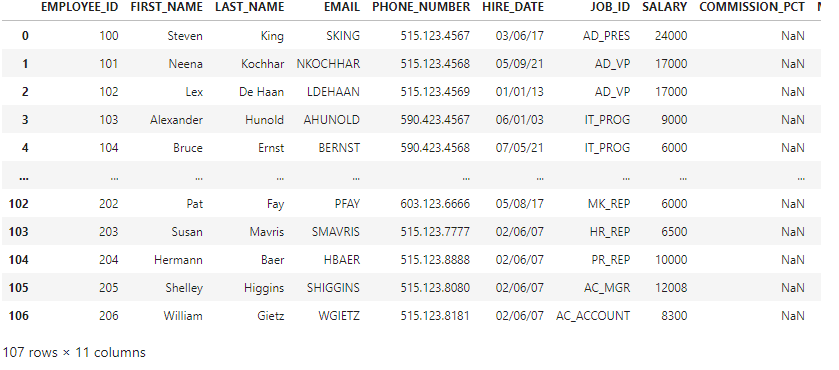
판다스 불러오기특정 기준으로 조회컬럼 만들기\*주의사항: 괄호를 잘 넣었는지 확인해야 한다.10-1. job_id 중 특정 이름만 출력합계, 평균, 최소, 최대, 개수 구하기agg를 통한 집계 한꺼번에 하기
13.[파이썬 판다스] 데이터 병합(merge)
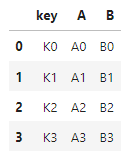
인덱스 리셋복합 열을 별도로 저장하고, 인덱스 리셋판다스 불러오기데이터프레임 만들기 & 조회하기데이터 병합이 케이스의 경우 완벽하게 떨어지는 경우라서 아래와 같이 보인다.머지 메소드 머지결과키값이 맞는 것만 보임핑크색 부분을 보면 left 기준으로 병합이 된 것을 알
14.[파이썬 맷플롯립] 바 차트와 히스토그램
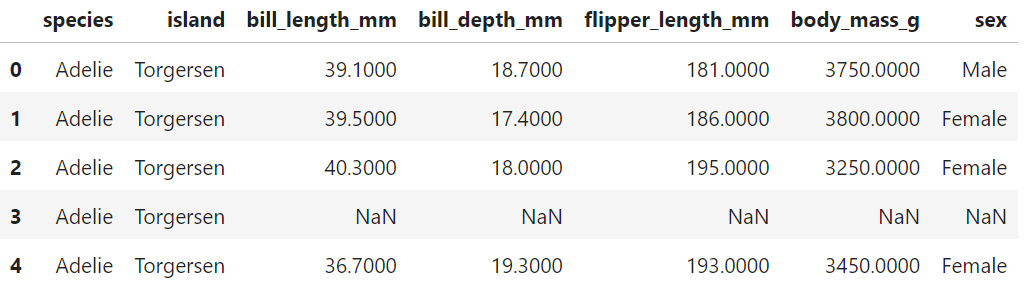
출처: https://www.pkpolar.pl/tag/pingwiny/씨본과 맷플롯립을 활용하여 각 펭귄의 종 별 몸무게의 차이를 그래프화하려고 한다.라이브러리 불러오기df 불러오기산점도 그리기데이터프레임 검토종별 바디매스 평균 보기speciesAdelie
15.[파이썬 맷플롯립] 선그래프, 산점도, 히스토그램
선 그래프 (라인차트)정보 확인<class 'pandas.core.frame.DataFrame'>RangeIndex: 918 entries, 0 to 917Data columns (total 2 columns): Column Non-Null Count Dtyp
16.[파이썬 맷플롯립] 다이아몬드, 타이타닉 데이터셋을 활용한 시각화
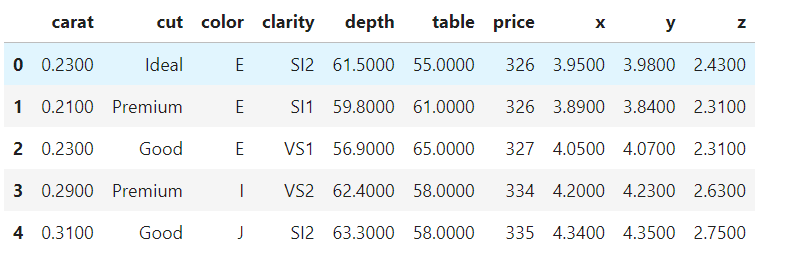
다이아몬드 데이터셋 불러오기 데이터의 각 변수carat: 다이아몬드 무게cut: 컷팅의 가치color: 다이아몬드 색상clarity: 깨끗한 정도depth: 깊이 비율, z / mean(x, y)table: 가장 넓은 부분의 너비 대비 다이아몬드 꼭대기의 너비price
17.[파이썬 맷플롯립] pyplot
시각화 생성x:y 플로팅 방법plt.plot(1, 2, 3, 4, 1, 4, 9, 16)각각 다른 다지안의 선 그리기t = np.arange(0., 5., 0.2)생성된 배열 t는 0.0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6, 1.8,
18.[파이썬 씨본] 데이터 시각화
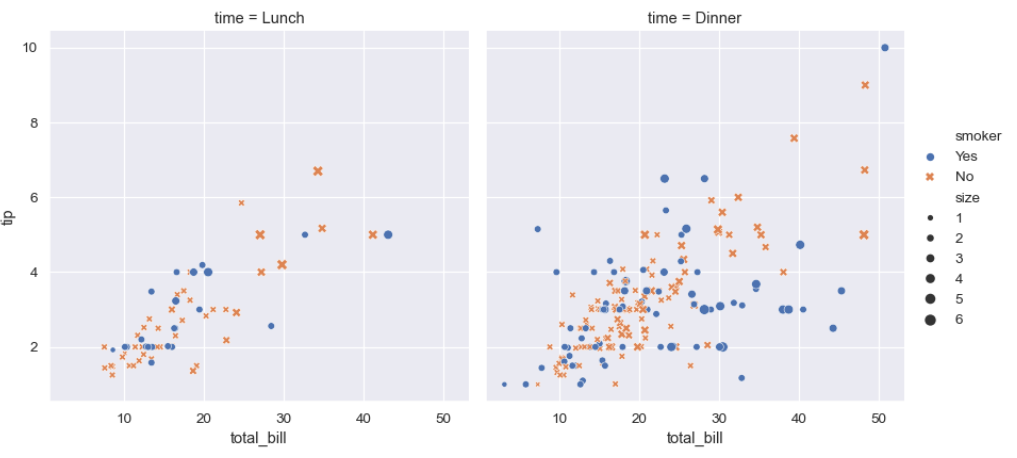
Seaborn은 파이썬에서 통계적 그래픽을 만드는 라이브러리이다.Matplotlib을 기반으로 하여 더 간단하고 세련된 시각화 기능을 제공한다.매핑과 통계적 집계를 수행하여 정보적인 플롯을 생성한다.API를 사용하면 더 다양하게 이용할 수 있다.import seabor
19.[파이썬 머신러닝] 랜덤포레스트 실습 및 정리
import pandas as pdimport osos.chdir(r'C:/Users/\~\~~')train_df = pd.read_csv('activity_train.csv')test_df = pd.read_csv('activity_test.csv')X_train =
20.[파이썬 머신러닝] Gradient Boosting Machine(GBM)
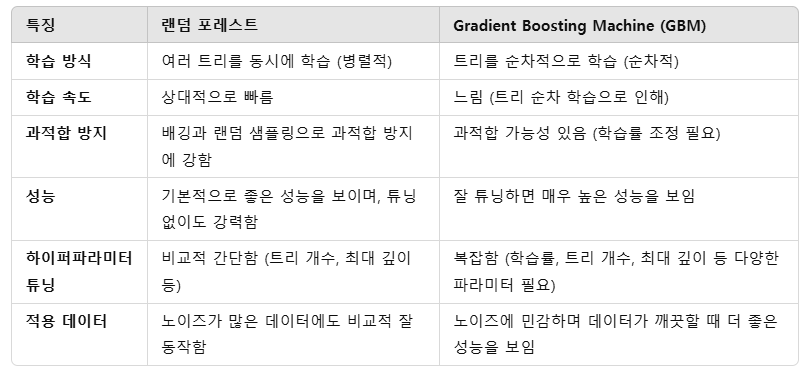
여러 개의 약한 학습기(주로 결정 트리)를 순차적으로 학습하여 오류를 보완하면서 강력한 모델을 만드는 알고리즘임. 주요 특징은 이전 단계의 오류를 보완하도록 다음 단계에서 학습하는 것임.GBM은 여러 개의 결정 트리를 순차적으로 학습시킴. 각 트리는 이전 트리의 오류를
21.[CNN] 파이토치 손글씨 인식
import pandas as pdimport numpy as npfrom sklearn.datasets import load_breast_cancerimport matplotlib.pyplot as pltfrom sklearn.model_selection import