데이터프레임(DataFrame)의 정의
-데이터프레임은 같은 크기의 자료들로 이루어진 열들을 차례로 모아 놓은 직사각 모양의 자료형
-데이터프레임의 열과 행은 각각 인덱스를 가지고 있음
데이터프레임을 만드는 방법
**같은 크기의 리스트 또는 넘파이 배열을 값으로 갖는 사전형을 사용하기
1. 데이터 프레임 만들기
데이프레임 작성예시
(1) 중괄호 ( { ) 로 먼저 묶는다.
(2) 열 이름은 '로 묶는다.
(3) 안에 들어가는 값들은 [ 로 시작한다.
- 문자열은
'를 붙이고, 수치형은 그대로 입력
데이터 = { '지역' : ['대전', ... ],
'년도' : [2015, ...] }
데이터 = {'지역': ['대전', '대전', '대전', '서울', '서울', '서울'],
'년도': [2015, 2016, 2017, 2015, 2016, 2017],
'인구': [1542, 1535, 1531, 9941, 9852, 9776]}
프레임 = pd.DataFrame(데이터)
프레임2. 데이터 프레임 보기
데이터프레임이름 입력한다.
프레임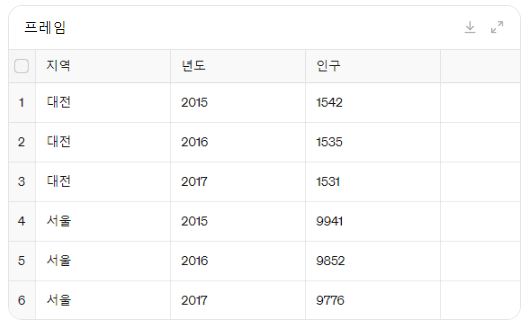
3. 상위 5개 자료 보기 (head)
메소드를 통해 상위 5개 자료를 확인한다.
프레임.head()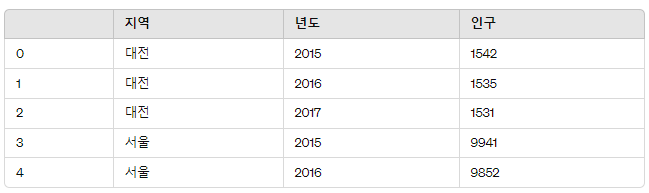
4. 컬럼 리스트 지정 (columns)
지역 --> 년도 --> 연구 순서 였던 열의 순서를 바꿀 수 있다.
아래와 같이 지역 --> 연구 --> 년도 로 바꾸어보자.
pd.DataFrame(데이터프레임이름, columns=['열이름'....바꾸고 싶은 순서대로])
pd.DataFrame(데이터, columns=['지역', '인구', '년도'])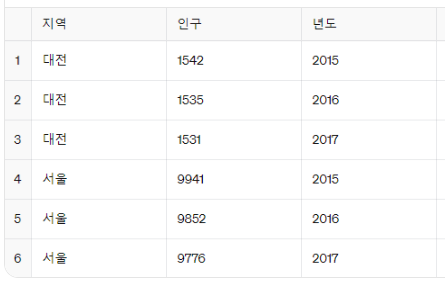
5. 사전에 없는 열 이름 지정해보기
열 이름인 '자산'을 만들고, 이를 새로운 데이터프레임에 넣었다.
이때 자산열에 소실값(NaN)이 지정된다.
프레임2 = pd.DataFrame(데이터, columns=['지역', '인구', '년도', '자산'],
index=['하나', '둘', '셋', '넷', '다섯', '여섯'])
프레임2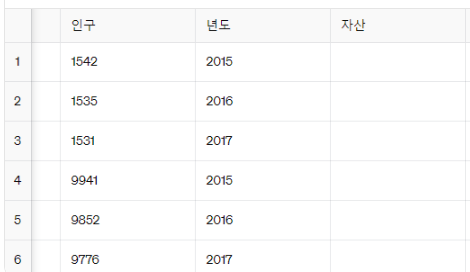
6. 열 구성 확인하기: columns
현재 프레임2에 열이 어떻게 구성되어 있느니 확인한다.
데이터프레임이름.columns 와 같이 작성한다.
프레임2.columns아웃풋
Index(['지역', '인구', '년도', '자산'], dtype='object')
7. 열 접근하기(사전적 열쇠, 속성)
방법 7-1. 사전적 열쇠를 통한 열 접근
사전적 열쇠는 프레임['열이름'] 으로 사용하면 된다.
프레임2['지역']아웃풋
하나 대전
둘 대전
셋 대전
넷 서울
다섯 서울
여섯 서울
Name: 지역, dtype: object
방법 7-2. 속성을 통한 열 접근
속성은 프레임명.열이름 으로 접근하면 된다.
프레임2.지역아웃풋
하나 대전
둘 대전
셋 대전
넷 서울
다섯 서울
여섯 서울
Name: 지역, dtype: object
--> 아웃풋이 모두 똑같은 것을 확인할 수 있다.
8. 행 접근하기: loc 속성
데이터프레임이름.loc['행 이름'] 와 같이 작성한다.
프레임2.loc['하나']아웃풋
지역 대전
인구 1542
년도 2015
자산 NaN
Name: 하나, dtype: object
9. 열에 값 지정하기
방법 9-1. 스칼라를 통해 열에 값 지정하기
스칼라 는 단일 값을 의미한다.
스칼라 값은 하나의 숫자, 문자열, 단일 데이터를 나타낸다.
- (참고)
벡터,배열은 여러 개의 값을 담을 수 있다.
자산 열에 20이라는 데이터를 넣어보자.
스칼라는 프레임명['열이름'] = 값 으로 대입한다.
프레임2['자산'] = 20
프레임2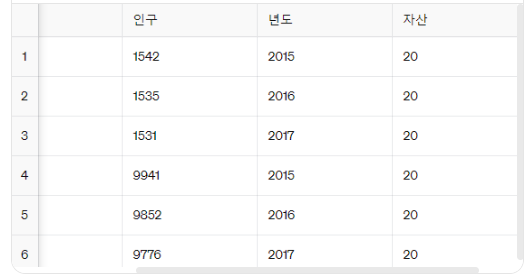
자산 열에 20 데이터가 채워진 것을 볼 수 있다.
9-2. 배열을 통해 열에 값 지정하기 ( 넘파이 함수 )
배열은 np.arange(n) 라는 함수를 통해 열에 값을 지정할 수 있다.
여기서 n은 숫자를 의미한다.
프레임명.열이름 = np.arange(n)
예) np.arange(6): 0부터 5까지의 숫자를 생성
20으로 채워졌던 것이 0, 1, 2, 3, 4, 5로 바뀐 것을 확인할 수 있다.
프레임2.자산 = np.arange(6)
프레임2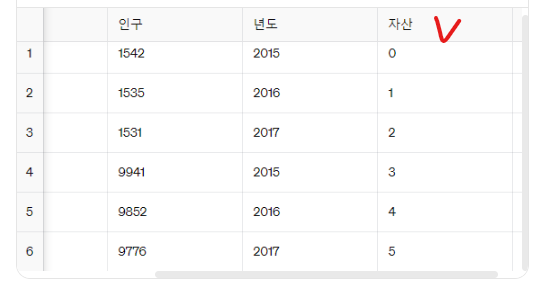
10. 배열 할당
배열 할당의 기준
배열 크기 == 데이터프레임 행의 크기
예) 배열이 3개면 데이터프레임도 3개
따라서 배열 크기랑 데이터프레임 행 크기랑 같아야 한다.
시리즈를 데이터프레임에 열로 지정할 수 있다.
시리즈 인덱스 이름 == 데이터프레임 인덱스 값이 설정됨
일치하지 않은 것은 소실값 NaN으로 나타남
용어 정리
시리즈 : 1차원 자료를 나타내기 위한 자료형
데이터프레임 : 2차원 자료를 나타내기 위한 자료형
데이터프레임 프레임2의 '자산' 열에 시 라는 시리즈를 대입할 것이다.
작성 예시
프레임이름1 = pd.Series([넣을 값들 ... ], index=[값들 .... 몇번째 행에])
프레임이름2[넣을 열 이름] = 프레임이름1
프레임이름2
시 = pd.Series([20, 19, 3], index=['둘', '넷', '다섯'])
프레임2['자산'] = 시
프레임2 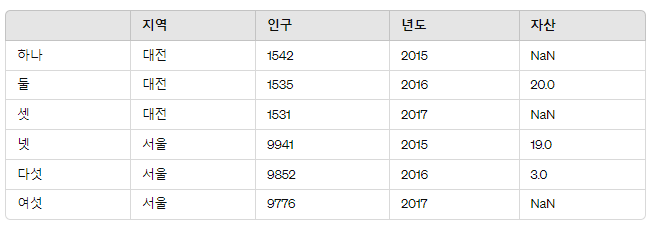
둘, 넷, 다섯 인덱스에 각각 20, 19, 13을 대입할 것이다.
해당 인덱스에 맞는 값이 업데이트되었고,
나머지 인덱스는 NaN으로 채워진 것을 알 수 있다.
11. 데이터프레임에 열 추가하기
사전 형식으로 데이터프레임에 덤이라는 새로운 열을 추가해보자.
그리고 지역이 대전이면 'True', 아니면 'False'를 표시하는지 확인해보자.
덤 열에서 확인 가능하다.
주의사항
프레임2.덤 (x)
위 형식으로 새로운 열을 추가할 수 없다.
열을 추가하기 위해 반드시 아래 방법으로 작성해야 한다.
프레임2['덤'] = 프레임2.지역 == '대전'
프레임2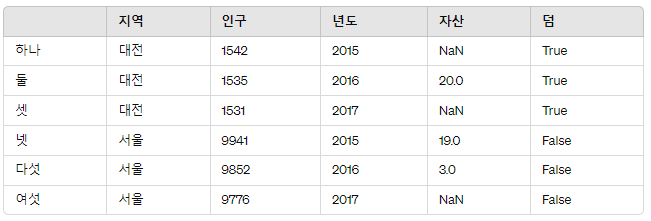
덤 열에서는 프레임2에 있는 지역이 대전이면 트루, 아니면 펄스로 나오는 것을 확인할 수 있다.
12. 열 제거하기: del 함수
del이라는 함수를 통해 열을 제거하도록 하자.
주의사항
속성을 통해서(예: del 프레임2.인구) 제거하고자 입력하면 오류가 발생한다.
열 제거할 때는 del 함수 를 이용하도록 하자.
열을 제거하기 위해 del 프레임이름['열이름'] 을 입력한다.
del 프레임2['덤']
프레임2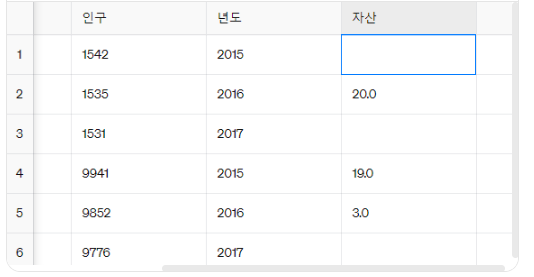
덤 열이 제거되었다.
13. 사전형 꼴로 자료 만들기
데이터프레임이름 = {'열이름': {'행이름1': 값1, '행이름2': 값2, '행이름3': 값3}, ... }} 으로 작성한다.
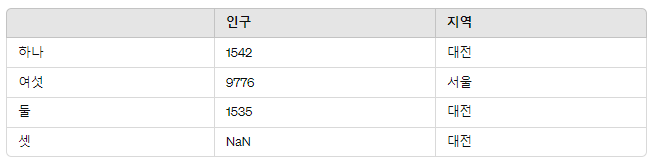
인구1 = {'인구': {'하나': 1542, '여섯': 9776, '둘': 1535}, '지역': {'하나': '대전', '여섯': '서울', '둘': '대전', '셋':'대전'}}
프레임3 = pd.DataFrame(인구1)
프레임3셋인덱스에서는 소실값을 확인할 수 있다.
인구1 딕셔너리에서 셋 인덱스에 대한 인구 값이 정의되지 않았기 때문이다.
14. 데이터프레임 전치(transpose)
전치 연산을 통해 행과 열의 위치를 바꿀 수 있다.
특정 행의 값을 열 단위로 비교할 수 있다.
예) 행과 열을 전치해서 각 지역별 인구 값을 한눈에 볼 수 있다.
아래 그림에서는 지역에 대전, 서울이 있는것을 확인할 수 있다.
판다스에서는 아래와 같이 해석한다.
- 바깥쪽 열쇠: 열 인덱스 이름
- 안쪽 열쇠: 행 인덱스 이름
프레임3.T

15. name 속성 지정하기
컬럼(열)인 인구, 지역은 '분류'
인덱스(행)인 둘, 셋, 여섯, 하나는 '번호' 로 행/열별 이름을 붙여주었다.
프레임3.index.name = '행 이름'
프레임3.columns.name = '열 이름 과 같이 작성한다.
프레임3.index.name = '번호'
프레임3.columns.name = '분류'
프레임3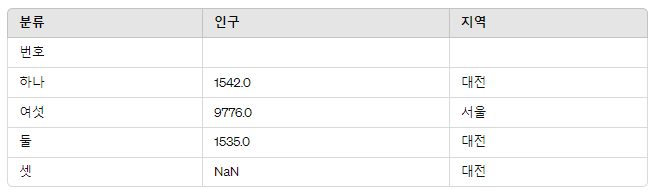
맨 왼쪽에 분류, 분류 바로 아래에 번호가 써져있는 것을 확인할 수 있다.
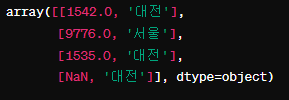
16. 이차원 값 배열 얻기: values 속성
이차원 값 배열을 얻기 위해서 데이터프레임이름.values 의 형식으로 작성한다.
프레임3.values이 배열은 프레임3의 각 행과 열의 값을 포함하고 있으며, 이는 2차원 배열로 표현되는 것을 알 수 있다.