0. 인덱스 객체(Index Objects)
인덱스 개체란 판다스에서 데이터의 행이나 열을 식별하는 레이블을 저장하는 객체를 말한다.
시리즈(Series)나 데이터프레임(DataFrame)에서 각각의 데이터 요소를 고유하게 식별할 수 있도록 도와준다.
인댁스 개체에서는 축 라벨과 축 이름을 관리할 수 있다.
시리즈 또는 데이터프레임을 만들 때
선택 인자 index=에 라벨 리스트를 대입하면
자동으로 인덱스 객체로 만든다.
pd.Series(range(3), index=['a', 'b', 'c']) 와 같이 입력한다.
시 = pd.Series(range(3), index=['a', 'b', 'c'])
시 아웃풋
a 0
b 1
c 2
dtype: int64
시.index했을 때 아웃풋을 확인하자.
인덱스 = 시.index
인덱스아웃풋
Index(['a', 'b', 'c'], dtype='object')
인덱스를 변경할 때 '새로운 인덱스' 설정하기
주의사항
인덱스 객체 그 자체로는 불변 객체이다.
예를 들어 'A'를 대입할 때 오류가 뜬다.
따라서 인덱스 객체를 직접 수정할 수 없음을 의미한다.
대신, 인덱스를 변경하고 싶다면 새로운 인덱스를 설정해야 한다.
인덱스[0] = 'A'아웃풋
Error: Index does not support mutable operations
위 설명과 같이 인댁스 객체를 직접 수정하려고 하니 에러가 뜨는 것을 확인할 수 있다.
1. 인덱스 값 변경하기: 인덱스명.values
인덱스.values아웃풋
['a' 'b' 'c']
인덱스.values[0] = 'A'
인덱스아웃풋
Index(['A', 'b', 'c'], dtype='object')
인덱스 객체를 사용하고 있는 시리즈 객체의 인덱스도 다음과 같이 변경이 되는 것을 볼 수 있다.
시아웃풋
A 1
b 2
c 3
dtype: int64
Index(['A', 'b', 'c'], dtype='object')
기존의 a가 A로 바뀐 것을 볼 수 있다.
2. 인덱스 객체를 집합처럼 다루기
인덱스 객체를 집합처럼 다룰 수도 있다.
프레임3아웃풋
인구 지역
분류
번호 1535.0 대전
둘 NaN 대전
셋 NaN 대전
여섯 9776.0 서울
하나 1542.0 대전

프레임3.columns아웃풋
Index(['인구', '지역'], dtype='object', name='분류')
'인구' in 프레임3.columns'여섯' in 프레임3.index모두 아웃풋이 True로 반환되는 것을 알 수 있다.
3. 중복값을 가지는 인덱스
파이썬 집합과는 다르게 판다스 인덱스는 중복된 값을 가질 수 있다.
중복인덱 = pd.Index(['하나', '둘', '하나', '셋'])
중복인덱아웃풋
Index(['하나', '둘', '하나', '셋'], dtype='object')
'하나' 라는 값이 중복되었지만 아웃풋에서도 확인 가능하다.
4. 인덱싱 다시하기: reindex
인덱싱을 다시하는 방법: reindex 를 이용한다.
새로운 인덱스에 맞게 기존의 자료를 재배열하여 새로운 객체를 만들어낸다.
시 = pd.Series([3, -8, 2, 0], index=['d', 'b', 'a', 'c'])
시아웃풋
d 3
b -8
a 2
c 0
dtype: int64
시리즈 객체에서 reindex메소드를 부르면
인자로 넘겨준 새로운 인덱스에 맞게 자료들을 재배열한다.
시.reindex(['a', 'b', 'c', 'd', 'e'])아웃풋
a 2.0
b -8.0
c 0.0
d 3.0
e NaN
dtype: float64
인덱스가 없으면 소실값을 설정한다.
'e' 인덱스에서는 '소실값'인 NaN이 나온 것을 알 수 있다.
5. 소실값 채우기: method='ffill'
시계열 자료일 경우 reindex 할 때 소실값들을 채우는 것이 더 좋을 때가 있다.
이 때 사용할 수 있는 선택인자, method= 가 있다.
method='ffill' 은 앞에 있는 자료로 뒤에 있는 소실값들을 채운다.
시1 = pd.Series(['빨강', '파랑', '초록'], index=[0, 2, 4])
시1아웃풋
0 빨강
2 파랑
4 초록
dtype: object
위와 같은 시리즈가 있다.
0, 2, 4 인덱스만 생성했다.
시1.reindex(range(6), method='ffill')소실값을 채우기 위해 0~5(n=6) 범위를 잡은 다음
ffill 메소드를 사용해보자.
아웃풋
0 빨강
1 빨강
2 파랑
3 파랑
4 초록
5 초록
dtype: object
0~1은 빨강, 2~3은 파랑, 4~6은 초록으로 되어있다.
6. 데이터프레임 리인덱스
6-1. 리인덱스: 하나의 인덱스만 주어질 경우
데이터프레임의 경우, reindex는 행, 열 또는 둘다 바꿀 수 있다.
하나의 인덱스만 주어지면 행에 대해서 재인덱싱을 한다.
먼저, 넘파이를 실행하고, 데이터프레임을 만든다.
import numpy as np
프 = pd.DataFrame(np.arange(6).reshape(3, 2), index=range(0, 5, 2), columns=['A', 'B'])
프- np.arange(6): 0부터 5까지의 숫자로 이루어진 배열을 생성
즉, [0, 1, 2, 3, 4, 5]가 된다.
- reshape(3, 2): 이 배열을 3행 2열의 2차원 배열로 변환
- pd.DataFrame: 2차원 배열을 데이터프레임으로 변환
- index=range(0, 5, 2): 행 인덱스를 0, 2, 4로 설정
range(0, 5, 2)
0부터 시작하여 5 미만까지 2씩 증가하는 숫자의 시퀀스를 생성한다 (그렇게 되면 0, 2, 4가 된다.)
- columns=['A', 'B']: 열 이름을 A와 B로 설정
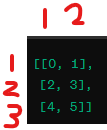
아웃풋
A B
0 0 1
2 2 3
4 4 5
6-2. 행에 대해 재인덱싱
행에 대해서 리인덱스를 해보자.
range(5)를 써서 0 ~ 5까지 인덱싱 하였다.
프.reindex(range(5))아웃풋
A B
0 0.0 1.0
1 NaN NaN
2 2.0 3.0
3 NaN NaN
4 4.0 5.0

1행, 3행이 재인덱싱된 것을 볼 수 있다.
이 행들은 소실값으로 확인된다.
6-3. 열에 대해 재인덱싱
열에 대해 재인덱싱을 해보자.
B, C, A 열의 순서로 인덱싱을 할 것이다.
프.reindex(columns=['B', 'C', 'A'])아웃풋
B C A
0 1 NaN 0
2 3 NaN 2
4 5 NaN 4
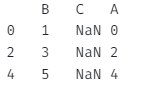
C열이 재인덱싱된 것을 볼 수 있다.
C열에 값을 쓴 적이 없으니 NaN로 나오는 걸 확인할 수 있다.
6-4. 행/열 모두 재인덱싱
프.reindex(range(5), columns=['B', 'C', 'A'])0 ~ 4행 인덱싱과 B, C, A열 인덱싱을 할 것이다.
아웃풋
B C A
0 1.0 NaN 0.0
1 NaN NaN NaN
2 3.0 NaN 2.0
3 NaN NaN NaN
4 5.0 NaN 4.0
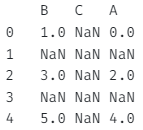
1행과 3행, C열이 재인덱싱된 것을 볼 수 있다.
