PEFT란?
: Parameter-Efficient Fine-Tuning
파라미터 효율적 파인 튜닝(미세 조정), 아주 일부에서는 PELT라고 부르기도 한다.
지금부터 기술하는 내용은
- 🤗PEFT :Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware (https://huggingface.co/blog/peft)
- LLM 모델 튜닝, 하나의 GPU로 가능할까? Parameter Efficient Fine-Tuning(PEFT)을 소개합니다! (https://devocean.sk.com/blog/techBoardDetail.do?ID=164779&boardType=techBlog)
를 참고하여 작성하였음을 밝힙니다.
등장 배경
기존의 패러다임
- 거대한 단위의 웹 데이터를 사전학습(pretrain)하고, downstream task에 따라 파인튜닝하는 것
- 사전학습된 LLM (Large Language Model)을 다운스트림 데이터셋에 따라서 Fine-tuning → 사전학습 모델을 그대로 사용하는 것보다 확실한 성능을 보임.
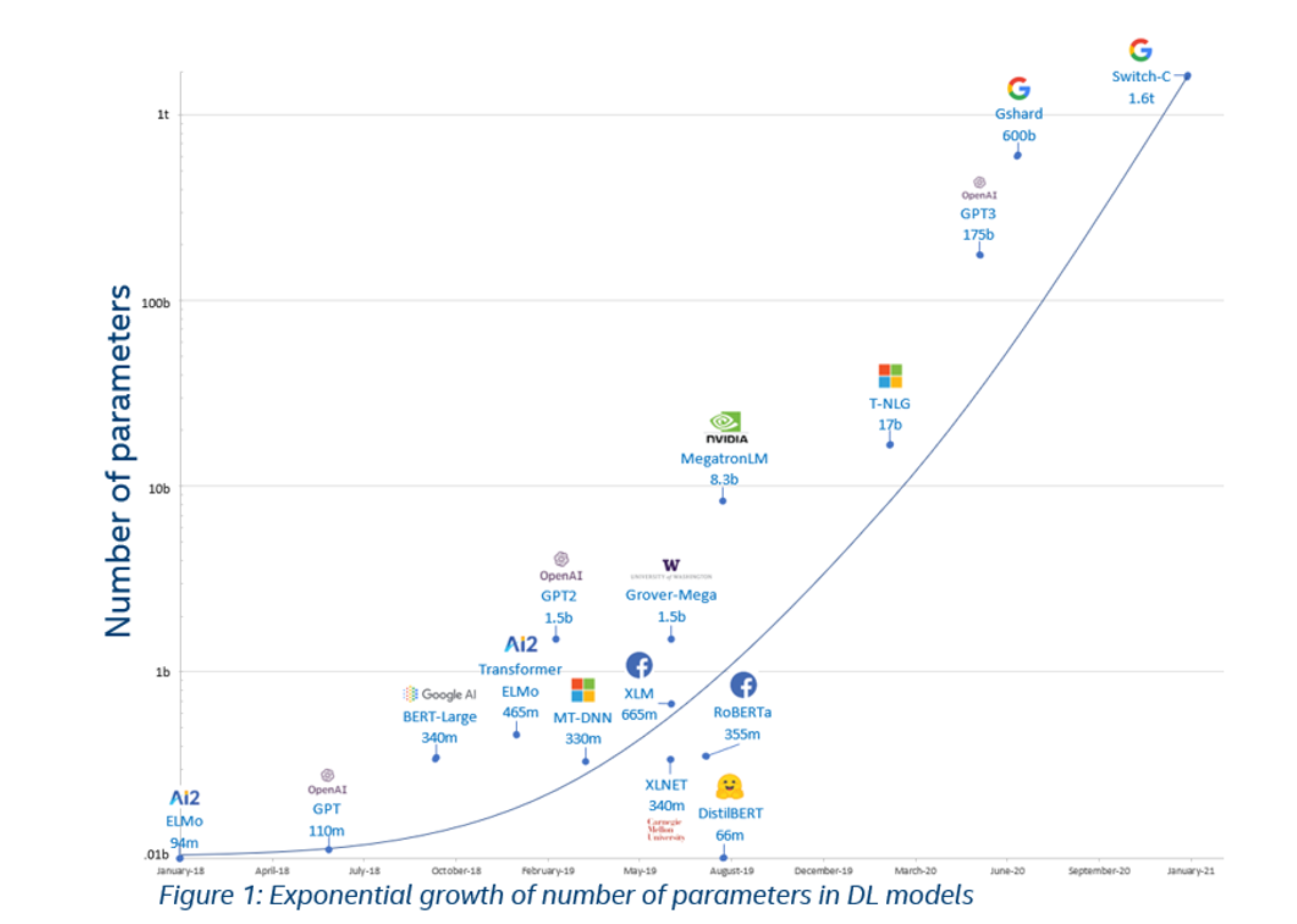
🫢 모델이 점점 커지게 된다!
장점
모델의 size가 커짐에 따라 성능 향상.
(모델이 커짐에 따라 In-context Learning; ICL을 통해 모델을 튜닝할 필요 없이 문제를 풀 수 있게 됨.)
단점
-
보통의 그래픽카드로 모델 전체를 파인튜닝하는 것이 불가능해짐.
-
모델을 저장하고 사용하는 데에 많은 비용 필요
(=모델이 무거워짐)
여러 개의 GPU도 필요하고..
🐮 아이디어: 소 잡는 칼로 닭 잡지 말자
In-context Learning
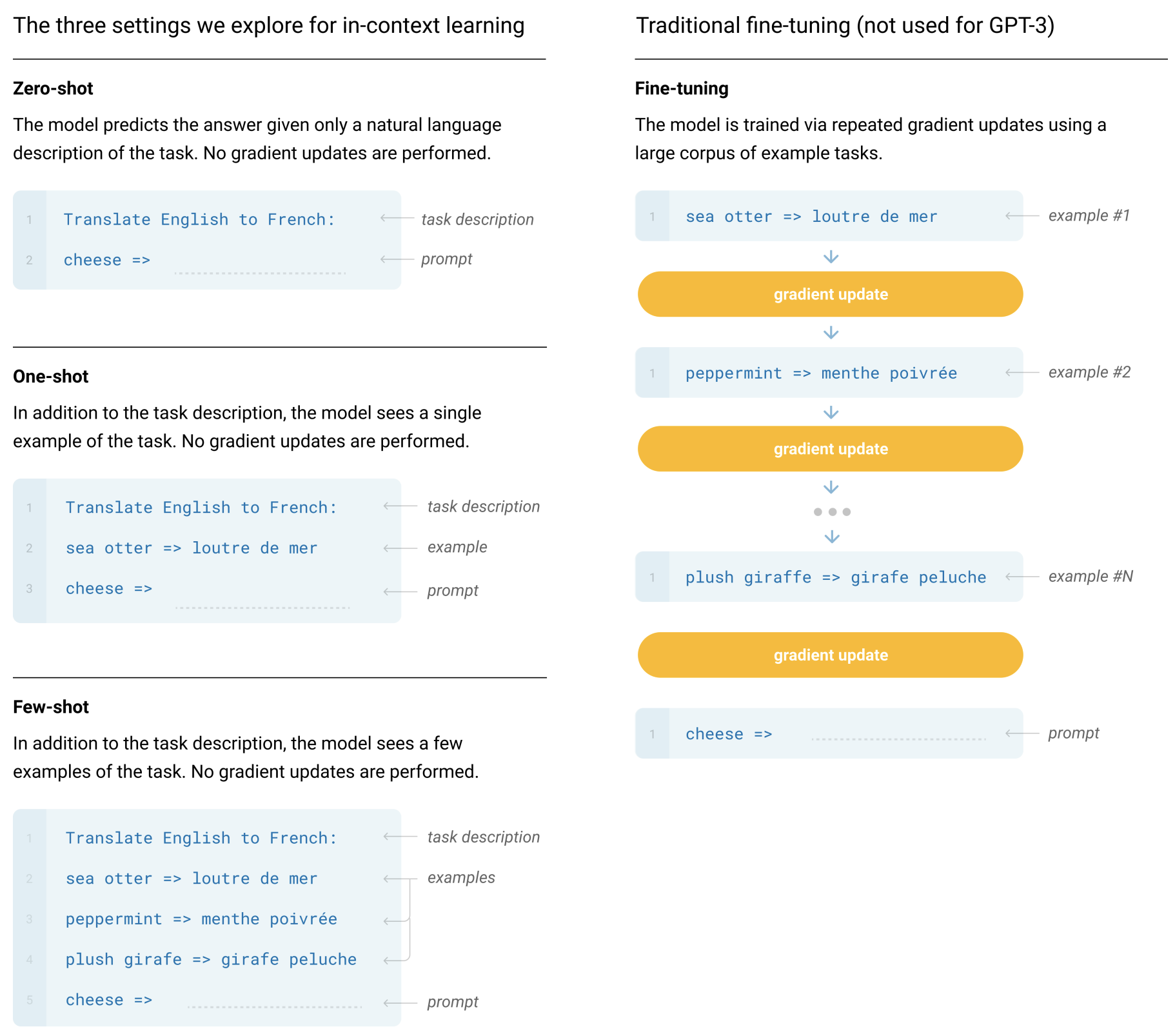
- 튜닝할 필요 없다는 점은 좋음. 그렇지만 간단한 task를 수행하기 위해서 굳이 무거운 모델을 써야만 할까??
- ICL은 매번 미리 예제를 입력해주어야하기 때문에 계산비용, 메모리비용, 저장비용 등이 발생 또한 incorrect labels을 예제로 넣어주더라도 문제를 잘 해결하기도 하더라 라는 내용의 연구도 존재 → 결과의 신뢰성 문제
PEFT의 장점?
(추후에 추가로 PEFT의 경험적 장점과 단점에 대해 정리할 예정)
👍 1. 저장공간, 계산능력 대폭 상승
- 사전학습된 LLM의 대부분의 파라미터를 프리징하고 일부의 파라미터만을 Fine-tuning하기 때문.
👍 2. catastrophic forgetting 극복
👍 3. low-data regime(데이터가 적은 상황), out-of-domain scenario에서 성능 Good
👍 4. 저장 공간 관리에도 도움이 됨.
- 전체 파인튜닝에서 만들어지는 큰 크기의 체크포인트 파일과 달리, 메가바이트 단위의 작은 체크포인트 파일을 얻을 수 있기 때문!
ex) Hugging Face의 bigscience/mt0-xl
Fully Fine-tuning
- 40GB 모델 → 전체 파인튜닝으로 인해 각 다운스트림 데이터 세트에 대해 40GB의 체크포인트 파일이 생성됨
PEFT
- 다운스트림 데이터 세트에 대해 몇개의 적은 용량을 가진 체크포인트 파일을 생성
- 전체 파인 튜닝과 유사한 성능을 달성
- 학습된 적은 weight는 사전학습된 LLM모델 레이어의 가장 윗부분에 위치하게 됨 : 모델 전체를 대체할 필요 없이 조금의 가중치만 추가 → 같은 모델로 여러 작업을 수행 가능

NLP Learner