
참고한 논문
링크: https://arxiv.org/pdf/1902.00751.pdf
Category: PEFT
학회: arXiv
0. Overview

Adapter Module
- 각 task마다 모델을 새로 training 시키는 대신, Adapter 모듈을 통해 transfer learning
- compact하면서도, extensible한 model을 만드는 것이 목표 다양한 task를 수행 가능한 동시에, 사이즈는 컴팩트하게!
- 기존 parameter는 fix, ❄️ 각 태스크마다 적은 parameters만 추가하여 trainable하게 함. 🔥 → 이를 통해 새로운 task를 수행 가능하도록 함.
🔗 관련 있는 학습 : multi-task, continual learning
Multi-task learning vs. Adapter
| multi-task | Adapter | |
|---|---|---|
| 공통점 | compact models | compact models |
| 차이점 | simultaneous하게 task 접근 | sequential하게 task 접근 |
Continual vs. Adapter
| continual | Adapter | |
|---|---|---|
| 공통점 | task를 계속해서 학습하는 것을 지향 | task를 계속해서 학습하는 것을 지향 |
| 차이점 | 다시 학습하고 나면 이전 task는 잊어버림 | interact하지 않고, shared parameter는 고정 |
1. Introduction
🔥 3 key properties (Contribution)
- 좋은 성능 보임
- task에 sequential하게 학습
: 모든 데이터셋에 대해 동시에 접근하지 않아도 됨- 각 task별로 추가하는 parameter가 매우 적음.
이러한 속성들을 달성하기 위해 어떻게 구현했냐면…
(Bottleneck) Adapter Module
🍦 Vanilla Fine-Tuning
- network의 top layer를 변형함
- 이는 upstream과 downstream에서 각 task의 공간과 label이 다르기 때문
- task-specific
🍫 Adapter
- 원래의 Parameter는 그대로 두고, 새롭게 추가된 parameter를 training시킴
- original network에 새로운 layer인 adapter layer 추가하여 이를 random하게 initialize
- general architectural modifications
| 🍦 Vanilla Fine tuning | 🍫 Adapter | |
|---|---|---|
| original weight | trainable 🔥 | freeze ❄️ |
| top-layer | trainable 🔥 | trainable 🔥 |
| general task | no (task-specific) ❌ | yes ⭕️ |
❓ 잠깐, general architectural modifications이라고?
- Introduction의
- 각 task마다 모델을 새로 training 시키는 대신, Adapter 모듈을 통해 transfer learning
이라는 문구를 기억하시나요?
→ 이게 바로
콘센트의 전압은 같지만, 어댑터를 통해 전압을 바꿔 다양한 전자기기를 사용할 수 있는 것처럼!
Adapter 모듈을 끼워넣어서 → 다양한 task에 대해 모델을 적용할 수 있도록 해보자! 는 뜻!!
2. Adapter tuning for NLP
특징 3가지?
1. 적은 parameter
(원래 parameter는 그대로 두고 (freeze❄️), 아주 적은 새로 추가된 parameter만 학습하는 방식)
2. near-identity initialization
required for stable training of the adapted model
- 학습이 시작되면, original network는 변하지 않게 됨
- 학습 중, adapter는 네트워크를 통한 activation의 분포를 바꾸기 위해 활성화될 수 있음.
- adapter module이 불필요하다면 무시됨.
Section 3.6
- 네트워크에 대해 다른 layer보다 Adapter가 더 많은 영향을 주는 것을 관찰함
- identity function으로부터 멀리 떨어져서 initialization되면, 모델이 학습 실패할 수 있음.
Instantiation for Transformer Networks
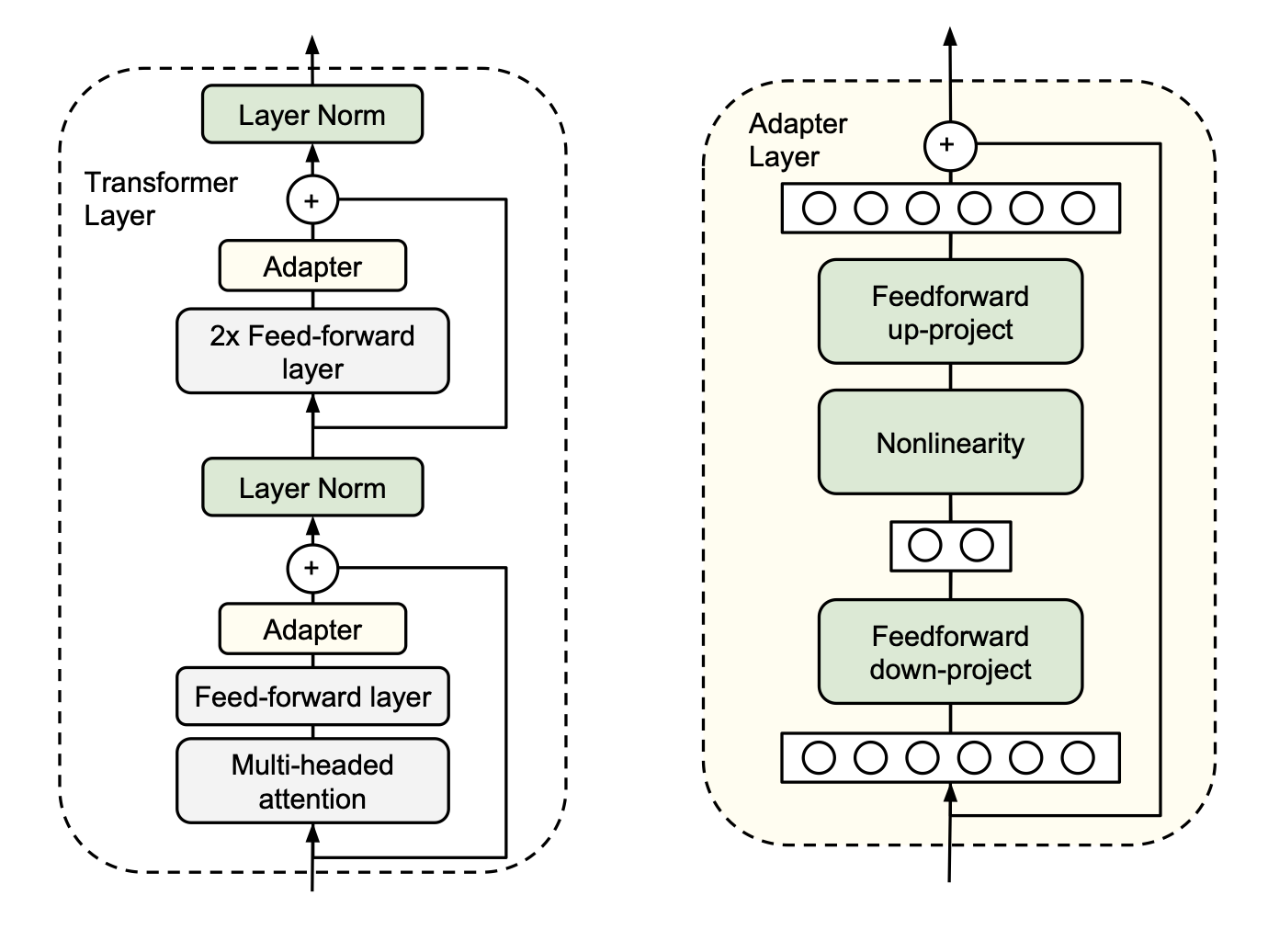
-
Adapter 모듈은 transformer에서 feedforward 이후에 위치
(실험했을 때, 이 구조가 가장 좋은 성능을 보였다고 함.)
projection : feature size → layer input size
추가로 skip connection도 이루어진다.
그 이후 layer normalization을 진행한다.
-
bottleneck 구조
- (d : feature size)
- d → m
- m → d
- 그러므로 총 parameter는 (2md + d + m)개 (m<<d)
- parameter는 원래 parameter보다 7.5~8.5% 정도만 추가해야 함 (만약 새로 추가된 parameter가 0에 가깝게 설정되면 원래 parameter만 남으므로 identity function으로 작용할 수 있다.) (layer normalization의 parameter는 건드리지 않는 것이 좋다고 함)
- (d : feature size)
3. Experiments
GLUE Benchmark
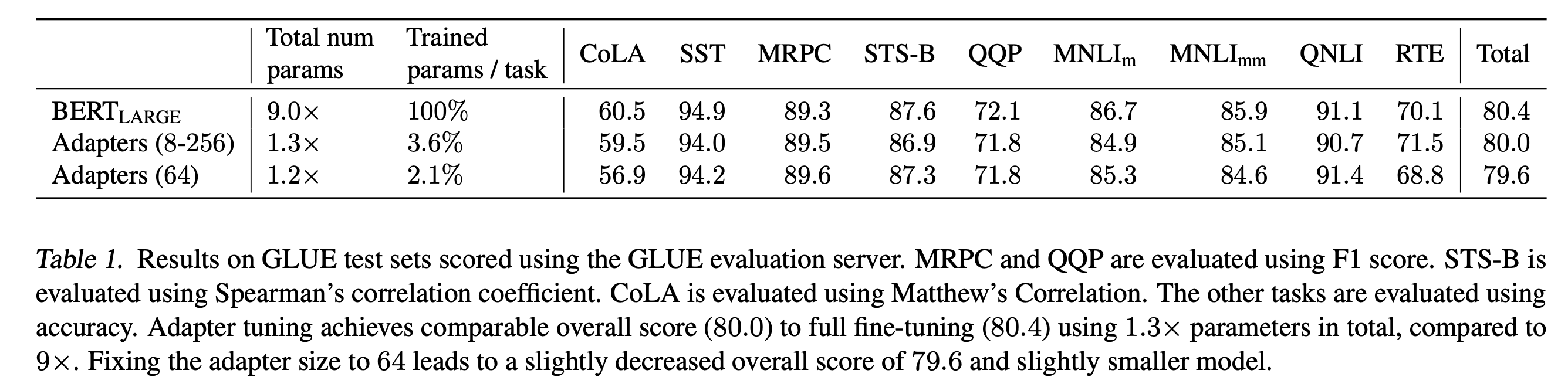
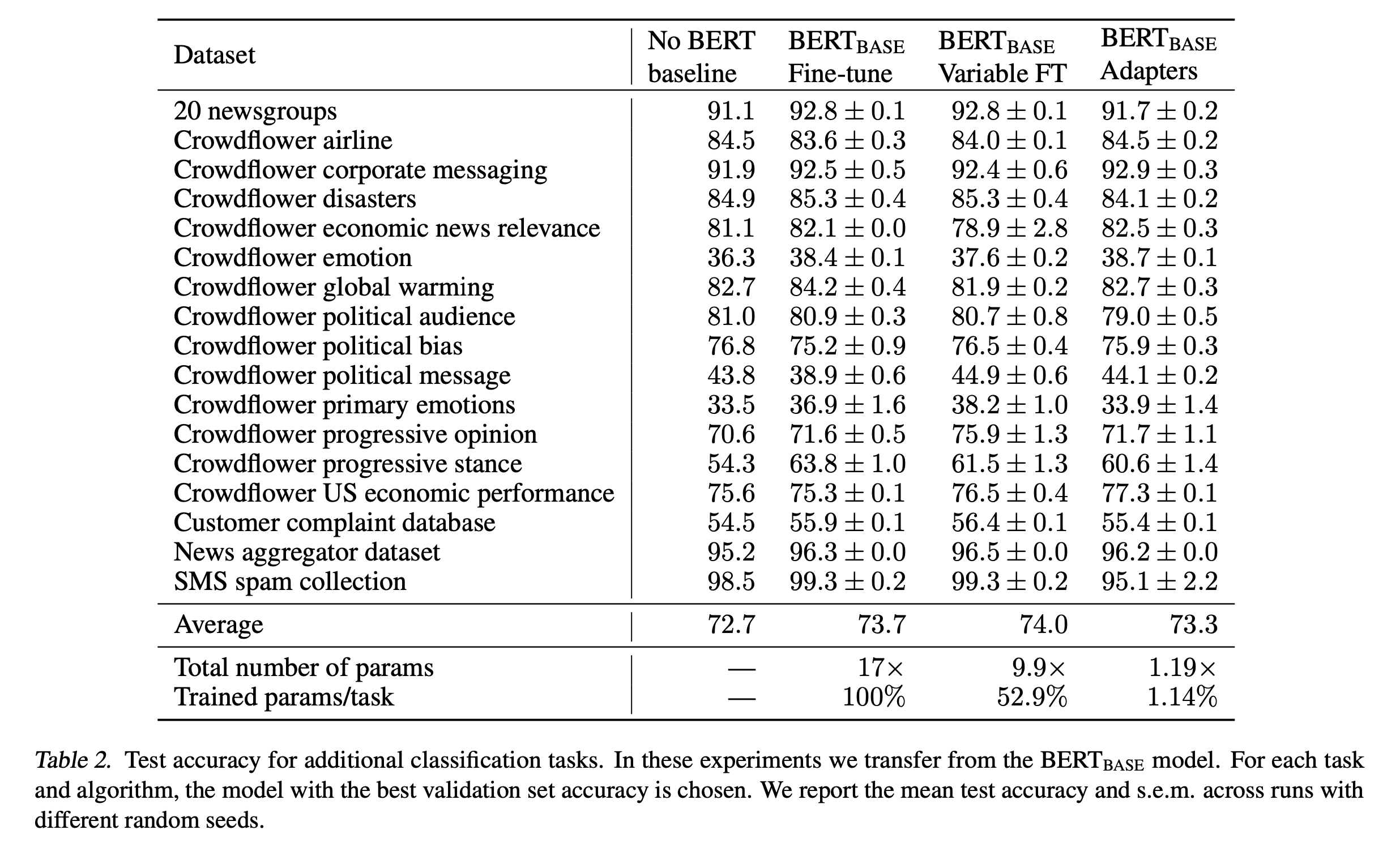
Additional Classification Tasks
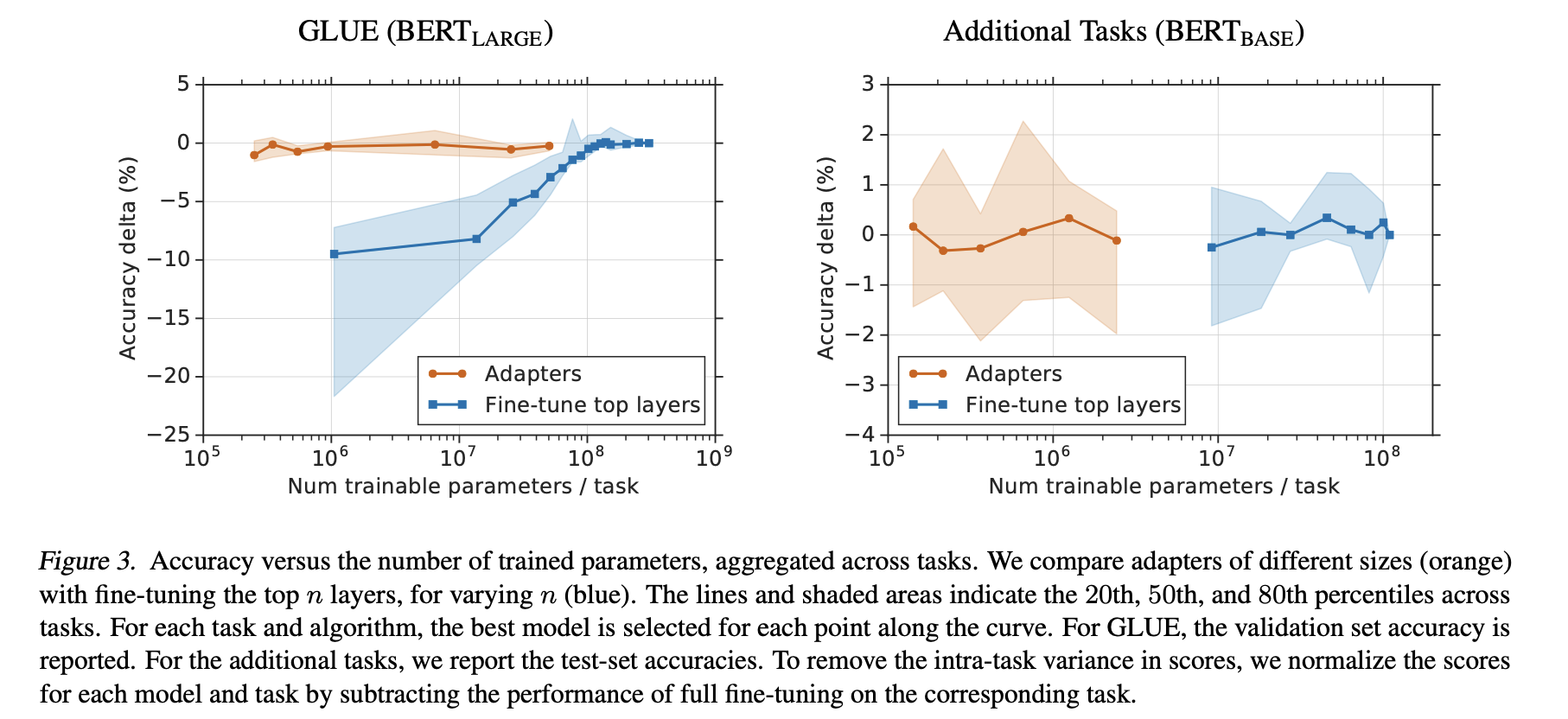
Parameter/Performance trade-off
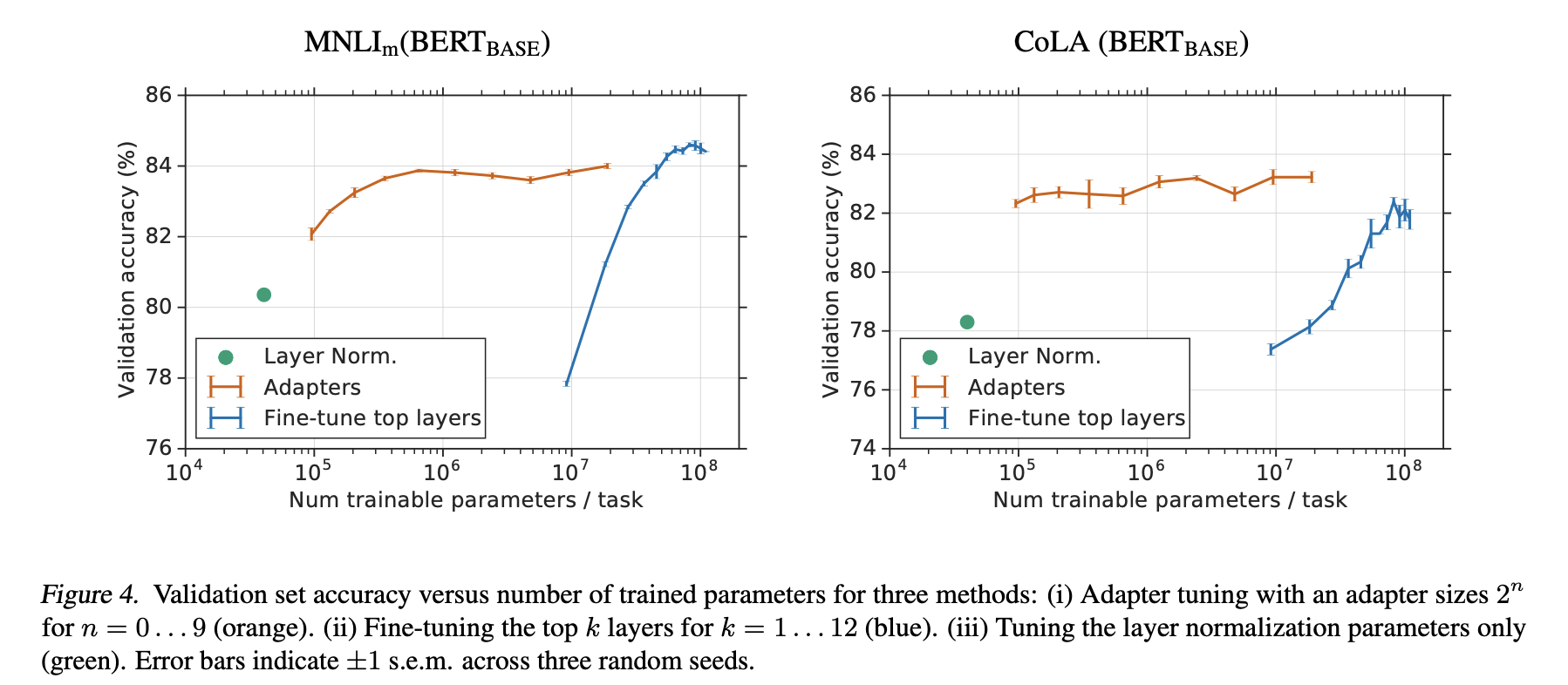
SQuAD Extractive Question Answering

