
※ 본 내용의 논문의 정리보단 제가 이해하고 공부한 내용위주로 작성하는 것이니 자세한 사항은 논문을 참고하시길 바랍니다.
안녕하세요. 오늘 리뷰할 논문은 "Improving Passage Retrieval with Zero-sho Question Generation"으로 EMNLP 2022 논문입니다.
- 논문에서는 Reranker의 방법론으로 training data나 finetuning을 하지 않아도 되는 Unsupervised Passage Re-ranking(UPR)을 제안
- 논문의 핵심 아이디어는 query를 generation하는 과정에 얻을 수 있는 logit값을 relevance socre로 이용했다는 점인 듯합니다.
Overview
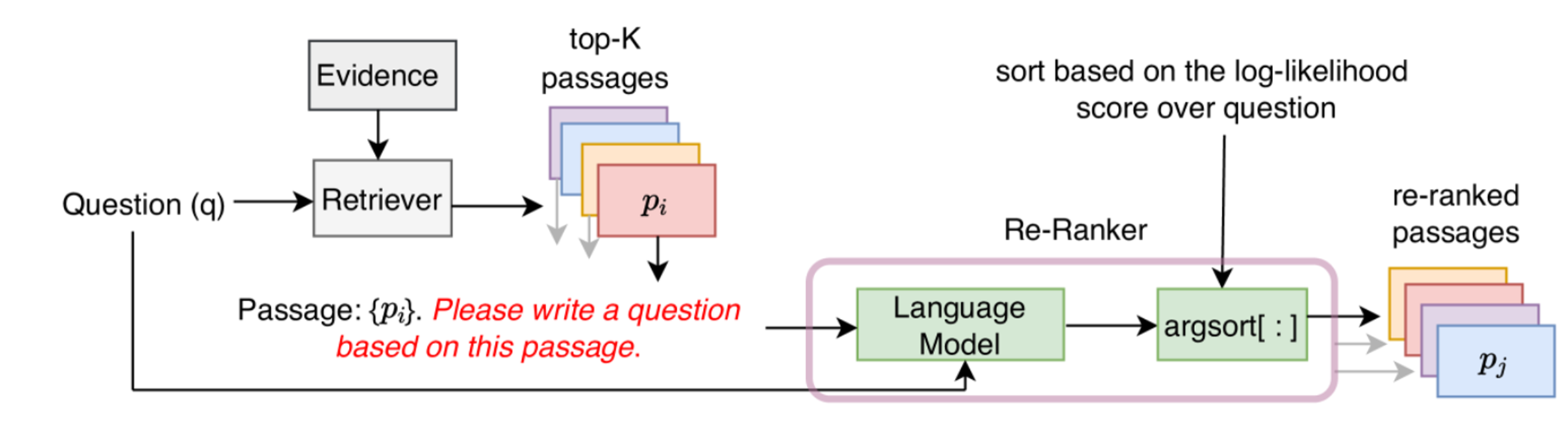
Method
1. Retriever
Retriever는 search query가 주어졌을 때, query와 관련 있는 문서들을 top-k개 문서를 검색하는 단계로, 논문에서는 기존에 있는 Unsupervised/supervised Retriever를 사용하였다.
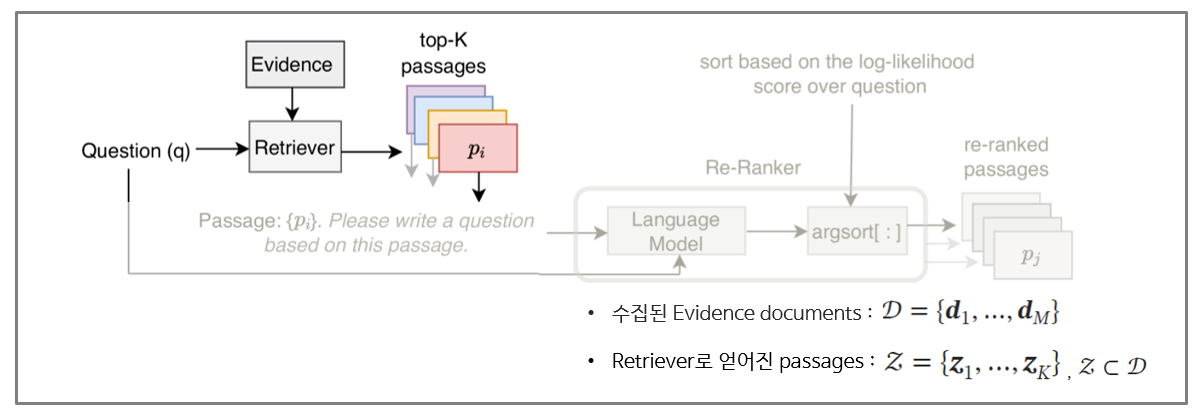
2. Unsupervised Passage Re-ranking (UPR)
query generation probability와 relevance score가 비례한다는 가정을 가지고, query generation 과정에서 relevance score를 구한다.

이를 Bayse’rule을 이용하여서도 수식적으로 표현하면 아래와 같이 정리할 수 있다.

Experiments
1. datasets
- Open-Domain QA dataset :
SQuAD-Open,TriviaQA,NA, WebQ - Keyword-centric Datasets :
Entity Questions,BEIR Benchmark
2. Retriever
- Unsupervised Retrievers :
BM25,MSS,Contriever - Supervised Retrievers :
DPR,MSS-DPR
Evaluation
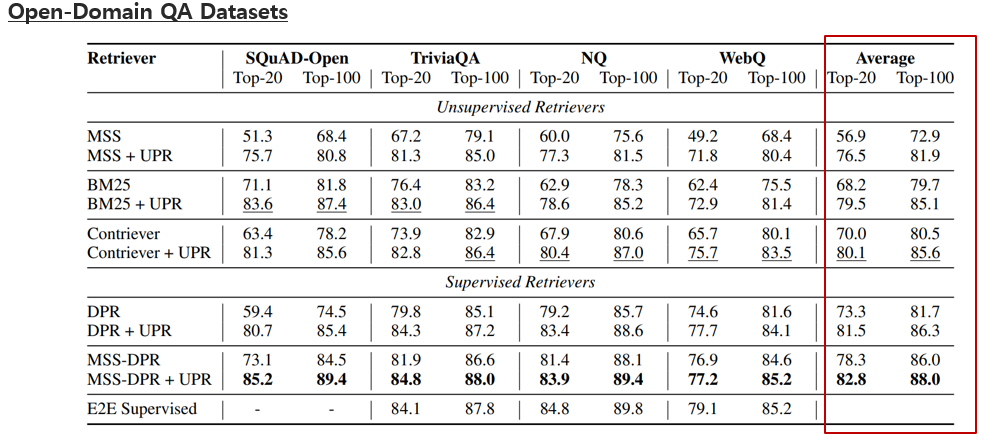
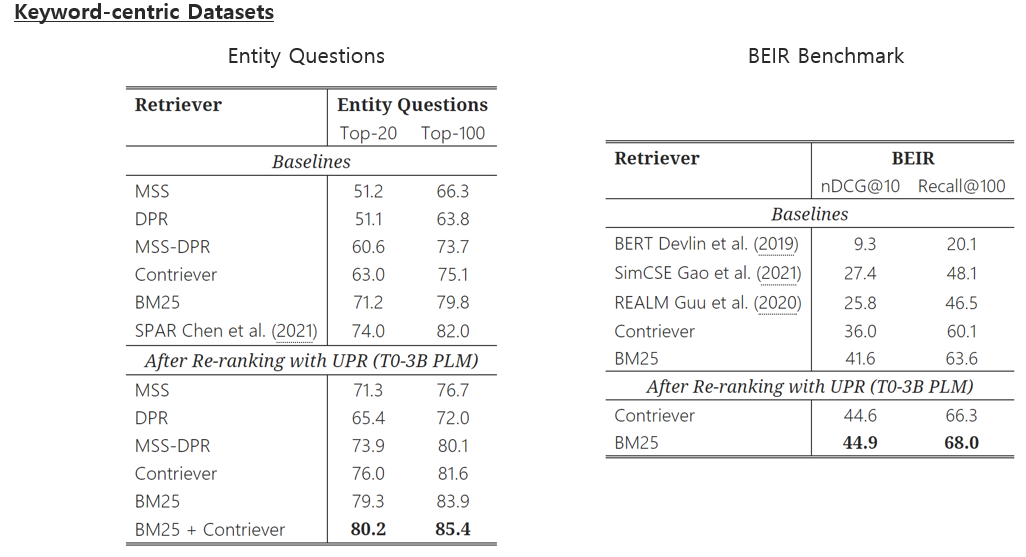
- 결과의 평균결과를 보면 기존 retriever만 사용했을 때보다, UPR을 함께 사용했을 때 전반적으로 성능 향상을 보였다.
- 이 결과에서 주목해볼 점은 완전한 unsupervised한 방식(contriever+UPR)이 supervised 하게 훈련된 모델(DPR)의 성능도 뛰어 넘을 수 있다는 점을 보여주었다.
Conclustions
- 논문에서는 검색을 위한 retriever-reranker pipeline에서 unsupervised passage re-ranking (UPR) 방법을 제안
- UPR은 PLM에서 문서기반 query를 generation하는 것을 통해 relevance score를 계산하는 방식
- 그 결과, UPR을 사용하였을 때 단순 retrieve만 사용했을 때 보다 높은 성능을 보였고, 특히 retriever와 UPR로 구성된 unsupervised pipeline이 supervised retriever models의 성능을 능가했다는 점이 주목할 만한 점
Limitations
- 한계점은 앞서 언급한 높은 latency가 발생할 수 있다는 점
- 또, 본질적인 re-ranker의 한계점으로 1단계인 retriever에 따라 성능이 달라지기 때문에 의존적이라는 점
- UPR은 PLM을 학습시키는데 사용된 학습 데이터에 민감할 수 있기 때문에 domain-specific한 task를 하기 위서는 PLM 선택에 있어 고려가 필요

NLP 파이팅해야지!