※ 본 내용의 논문의 정리보단 제가 이해하고 공부한 내용위주로 작성하는 것이니 자세한 사항은 논문을 참고하시길 바랍니다.
안녕하세요. 오늘 리뷰할 논문은 "Improving Passage Retrieval with Zero-sho Question Generation"으로 ICLR 2023 논문입니다.
- knowledge intensive task에서 많이 사용하고 있는 기존
retrieve-then-readpipline 대신 LLM을 이용하여 주어진 Question에 대해 context documents를 직접 생성하는 방법인generate-then-readpipline을 제안합니다.
Overview

Method

1. Zero-shot setting
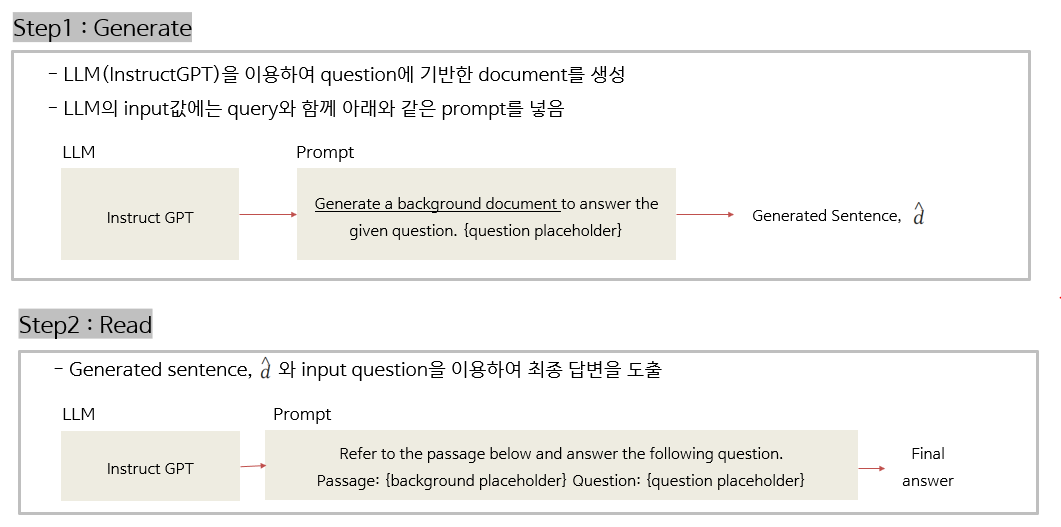
2. Supervised setting
- 기존 DPR과 같은 retriever를 포함한 구조의 Supervised setting 에서는 retrieved된 documents가 많을수록 성능이 향상되고, 다양한 관점에서의 documents를 가져옴
- 그러나, generator같은 경우에는 깊은 지식의 documents를 생성하는 것이 어렵고, 텍스트가 반복될 가능성이 있어 다양성에 문제점을 가지고 있음
- 따라서, 논문에서는 이를 개선하기 위해 두가지 Prompt 방법을 이용하여 실험 진행
Diverse Human Prompts
사람이 직접 다른 프롬프트를 선택하여 문서를 생성하는 방법
Clustering-based Prompts
Clustering을 통해 다양한 문맥의 정보를 반영하는 문서를 생성하는 방법

Evaluation
Zero-shot Setting
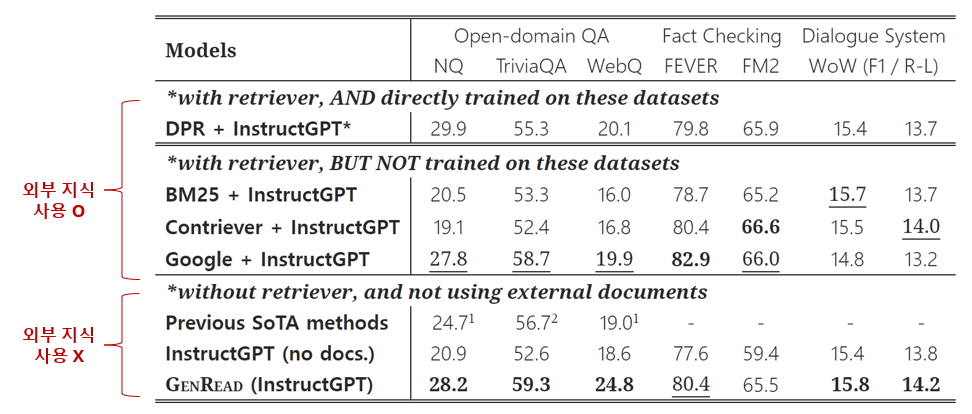
- 세가지 태스크들에서 GenRead 방식은 외부 지식을 사용하지 않았음에도 불구하고, 외부지식을 사용한 retriever 방식보다 더 높거나 비슷한 성능을 보임 (논문 작성 당시 Open-domain QA task SOTA 달성)
- 외부 지식을 사용하지 않은 방법들(InstructGPT, FLAN, GLaM)과도 비교하였을 때 가장 높은 성능을 보여줌
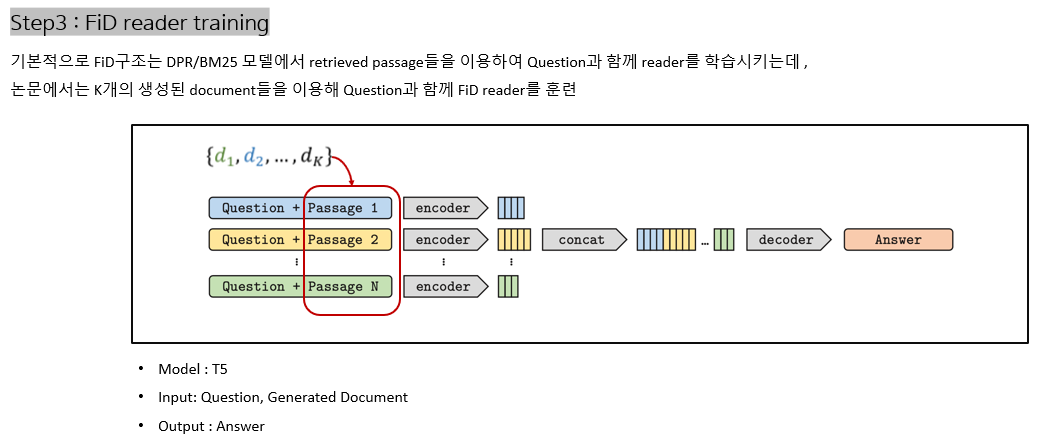
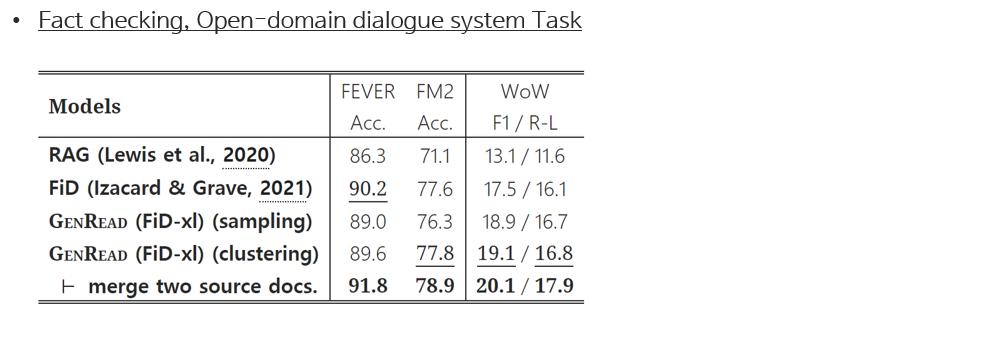
Supervised setting
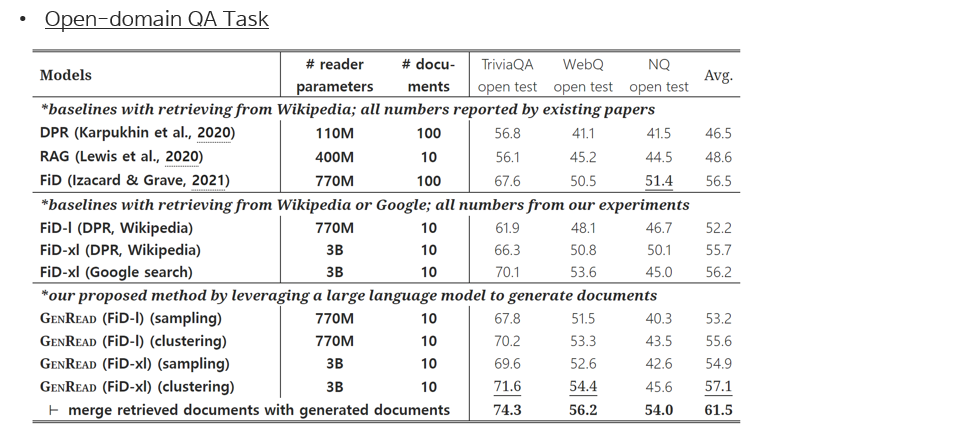
Conclustions
-
논문에서는 기존에 연구되어 오고 있는 retrieve-then-read pipeline 대신, generate-then-read pipeline을 제안하며 knowledge-intensive tasks를 해결하는 새로운 방법을 제시
-
Documents를 생성하는데 있어, 다양한 contextual documents를 만들기 위해 clustering-based prompting 접근 방법을 제안
-
실험 결과, 주목할 점은 논문에서 제시한 GenRead모델이 기존 retrieval-reader model들과 달리 외부 지식 없이도 기존 모델들의 성능을 뛰었다는 점

NLP 파이팅해야지!