L1, L2 실습 - Si-kit Learn Breast Cancer Case
#L1/L2 Regularization
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
#breast_cancer
cancer = load_breast_cancer()
x = cancer.data
y = cancer.target
#8:2
train_x, test_x, train_y, test_y = train_test_split(x, y, test_size=0.2, random_state=42)
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler로 전처리
scaler = MinMaxScaler()
train_x_scaled = scaler.fit_transform(train_x)
test_x_scaled = scaler.transform(test_x)
# 기본 logistic Regression
logistic_regression = LogisticRegression(max_iter=100)
logistic_regression.fit(train_x_scaled, train_y)
#prediction
pred = logistic_regression.predict(test_x_scaled)
#accuracy
acc = accuracy_score(test_y, pred)
print("breast_cancer Accuracy:", acc)
## 오류 원인은 accuracy(score)에서 pred 모델 자체에 Logistic Regression 객체를 넣어서. fit()은 예측 결과를 반환하는 게 아니라 자기 자신을 반환함
################################### L1
from sklearn.feature_selection import SelectFromModel
selector = SelectFromModel(LogisticRegression(penalty='l1', C = 0.1, solver ='liblinear', max_iter = 100))
selector.fit(train_x_scaled, train_y)
#feature extract
X_train_new = selector.transform(train_x_scaled)
X_test_new = selector.transform(test_x_scaled)
# Prediction with new features
model = LogisticRegression()
model.fit(X_train_new, train_y)
y_pred = model.predict(X_test_new)
#Accuracy Score
acc = accuracy_score(test_y, y_pred)
print("L1 Accuracy: ", acc)
################################### L2
selector = SelectFromModel(LogisticRegression(penalty='l2', C= 0.1, solver='liblinear', max_iter = 100))
selector.fit(train_x_scaled, train_y)
X_train_new = selector.transform(train_x_scaled)
X_test_new = selector.transform(test_x_scaled)
# Prediction with new features
model = LogisticRegression()
model.fit(X_train_new, train_y)
y_pred = model.predict(X_test_new)
# Accuracy
acc = accuracy_score(test_y, y_pred)
print("L2 Accuracy: ", acc)결과
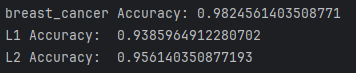
해석
- 첫 행에 Overfitting이 일어난 것 확인
- L1 규제를 적용하니 확실히 많이 줄었음 (Classification에서 좋은 성능, Sparsity 확보)
- L2 규제를 적용하니 성능도 확보하였고 Overfitting의 위험성도 줄일 수 있었음

안녕하세요! 강민수입니다.