Dataset 출처
https://www.kaggle.com/datasets/whenamancodes/heart-failure-clinical-records?resource=download

Code
# Heart Failure Dataset
# It has 12 features
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score
# Import Data
df = pd.read_csv("C:\\Users\\datam\\OneDrive\\Desktop\\MK\\practice\\Heart Failure Clinical Records.csv")
feature = df.columns.tolist()
X = df.drop('DEATH_EVENT', axis=1)
Y = df['DEATH_EVENT']
print("Features:", feature)
print("X shape", X.shape)
print("Y shape", Y.shape)
# Split to 8:2
train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.2, random_state=42)
# Min Max Scaling
scaler = MinMaxScaler()
train_x_scaled = scaler.fit_transform(train_x)
test_x_scaled = scaler.transform(test_x)
# Hyper param candidates
gamma_list = [0.01, 0.1, 1, 2, 5]
C_list = [0.1, 1, 10, 100, 1000]
# Greedy Search
best_score = 0
best_params = {'C': None, 'gamma': None}
train_scores = []
val_scores = []
for gamma in gamma_list:
for C in C_list:
svc = SVC(C=C, gamma=gamma, max_iter=10000)
svc.fit(train_x_scaled, train_y)
train_acc = svc.score(train_x_scaled, train_y)
val_acc = svc.score(test_x_scaled, test_y)
train_scores.append((gamma, C, train_acc))
val_scores.append((gamma, C, val_acc))
if val_acc > best_score:
best_score = val_acc
best_params['C'] = C
best_params['gamma'] = gamma
print("Best Validation Accuracy:", best_score)
print("Best Parameters:", best_params)
# Fitting with best param
final_model = SVC(C=best_params['C'], gamma=best_params['gamma'], max_iter=1000)
final_model.fit(train_x_scaled, train_y)
final_pred = final_model.predict(test_x_scaled)
final_acc = accuracy_score(test_y, final_pred)
print("Final Test Accuracy:", final_acc)
# Visaulization
#train_scores_arr = np.array(train_scores)
#val_scores_arr = np.array(val_scores)
#plt.figure(figsize=(10, 5))
#plt.plot(range(len(train_scores)), train_scores_arr[:, 2], label='Train Accuracy')
#plt.plot(range(len(val_scores)), val_scores_arr[:, 2], label='Validation Accuracy')
#plt.xticks(ticks=range(len(train_scores)), labels=[f"γ={g},C={c}" for g, c in train_scores_arr[:, :2]], rotation=90)
#plt.xlabel("Parameter Combination")
#plt.ylabel("Accuracy")
#plt.title("Train vs Validation Accuracy")
#plt.legend()
#plt.tight_layout()
#plt.show()
#####################################################################################################
##RF
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve, auc, accuracy_score
# Hyper param candidate
n_estimators_list = [50, 100, 200]
max_depth_list = [2, 3, 5, 10, 15]
# greedy search
best_rf_score = 0
best_rf_params = {'n_estimators': None, 'max_depth': None}
rf_train_scores = []
rf_val_scores = []
for n in n_estimators_list:
for d in max_depth_list:
rf = RandomForestClassifier(n_estimators=n, max_depth=d, random_state=42)
rf.fit(train_x_scaled, train_y)
train_acc = rf.score(train_x_scaled, train_y)
val_acc = rf.score(test_x_scaled, test_y)
rf_train_scores.append((n, d, train_acc))
rf_val_scores.append((n, d, val_acc))
if val_acc > best_rf_score:
best_rf_score = val_acc
best_rf_params['n_estimators'] = n
best_rf_params['max_depth'] = d
print("Best RF Validation Accuracy:", best_rf_score)
print("Best RF Parameters:", best_rf_params)
# Fit with best param
best_rf = RandomForestClassifier(
n_estimators=best_rf_params['n_estimators'],
max_depth=best_rf_params['max_depth'],
random_state=42
)
best_rf.fit(train_x_scaled, train_y)
rf_final_pred = best_rf.predict(test_x_scaled)
rf_final_acc = accuracy_score(test_y, rf_final_pred)
print("Final RF Test Accuracy:", rf_final_acc)
# ROC Curve 비교 (SVM은 기존 모델 사용)
rf_pred_proba = best_rf.predict_proba(test_x_scaled)[:, 1]
svm_pred_scores = final_model.decision_function(test_x_scaled)
fpr_rf, tpr_rf, _ = roc_curve(test_y, rf_pred_proba)
fpr_svm, tpr_svm, _ = roc_curve(test_y, svm_pred_scores)
roc_auc_rf = auc(fpr_rf, tpr_rf)
roc_auc_svm = auc(fpr_svm, tpr_svm)
# Visualization
plt.figure(figsize=(8, 6))
plt.plot(fpr_rf, tpr_rf, label=f"Random Forest (AUC = {roc_auc_rf:.2f})")
plt.plot(fpr_svm, tpr_svm, label=f"SVM (AUC = {roc_auc_svm:.2f})")
plt.plot([0, 1], [0, 1], 'k--', label='Random Chance')
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve Comparison: SVM vs Random Forest")
plt.legend(loc='lower right')
plt.grid(True)
plt.tight_layout()
plt.show()Visualization
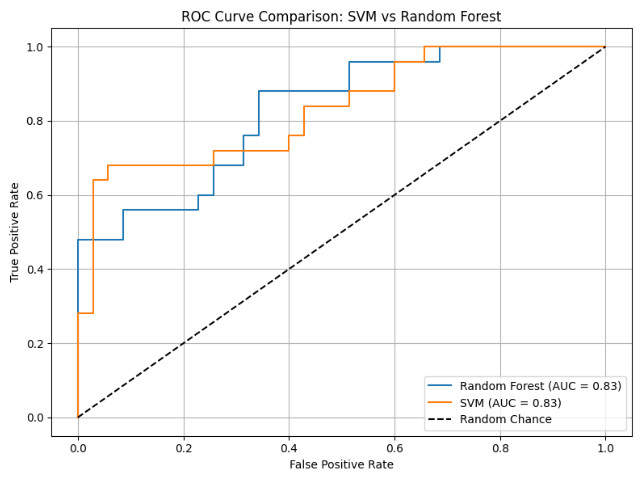
-AUC가 동일한 것을 볼 수 있었음
-내가 추가한 Hyper-param 외에도 더 추가해서 Search 하면 좋은 성능을 가질 수 있겠지요
-Scaler는 MinMaxScaler를 사용했습니다.
-max_iter를 1,000으로 hyperparam을 비교하기 전에 조기에 멈추는 현상이 나타나서 10,000으로 설정하였음.

안녕하세요! 강민수입니다.