Pandas 기초
Series + Series = Dataframe
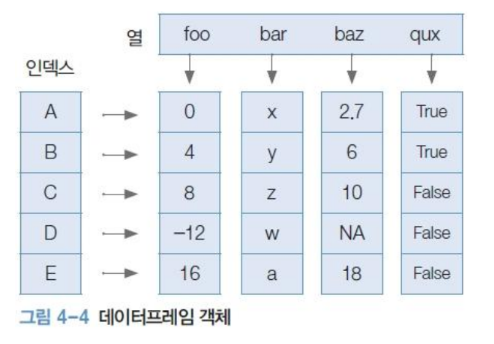
Series
- 머신러닝의 Feature Vector와 유사
- Df의 일부이며, 리스트, dict, nparray 등으로부터 변환가능
- data, index, datatype 3가지 요소로 구성됨
- index 수정 가능하고 해당 값이 없으면 NaN
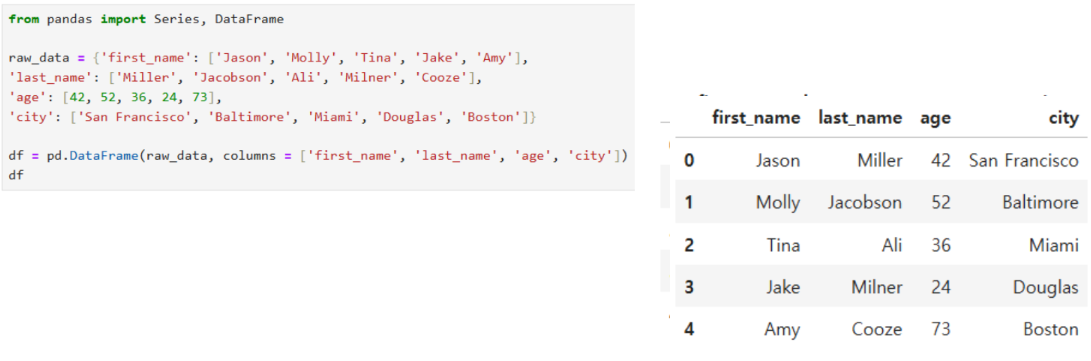
Df 생성
Data Handling
#행데이터 추출
df[5:10]
#데이터셋 조회
df['who'].value_counts()
#Dataset Attributes
df.ndim
df.shape
df.index
df.columns
#Sorting
df.sort_index().head(10)
df.sort_index(ascending=False).head(5)
df.sort_values(by='age').head()#Condition Filtering - loc(location)
df.loc[5, 'class']
df.loc[2:5, ['age', 'fare', 'who']]
# 아래를 출력하면 모든 Data의 Boolean value is printed
cond = (df['age'] > 50)
#조건에 맞는 데이터만 추출 가능
df.loc[[df['age'] > 50]
#describe(): 요약통계
df.describe()
#또는
df.describe(include = 'object')위 내용을 활용해서 남성/ 평균 찾기
condition = (df['adult_male'] == True)
df.loc[condition, 'age'].mean()
df.mean(skipna=False) #NaN 값이 있는 column은 NaN으로 출력
#median은 중앙값누적합
df['age'].cumsum()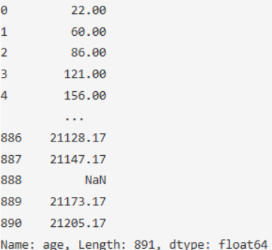
fillna() 결측치 채우기
#fillna()
df['age'] = df['age'].fillna(700)
#평균/중앙값/최빈값으로 채울 수 있음
df['age'] = fillna(df['age'].mean())
df['age'] = fillna(df['age'].median())
df['age'] = fillna(df['age'].mede())
## dropna()로 결측치 제거
df.dropna(how='all')그룹별 집계 실습
#팀 별 점수 합계
df.groupby("Team")["Points"].sum()
#다중 인덱스 활용 그룹별 집계
df.groupby(["Team", "Year"])["Points"].mean()
df.groupby(level = 1).median()실습 with lambda함수로 z-score
여기서 merge(), transform()의 차이가 나옴
score = lambda x: (x = x.mean()) / x.std()
df.groupby("Team").transform(score)mean_purchase =df.groupby('User_ID')["Purchase"].mean().rename("User_mean").reset_index()
df_1 = df.merge(mean_purchase)Groupby 후 Merge하면 번거롭기 때문에
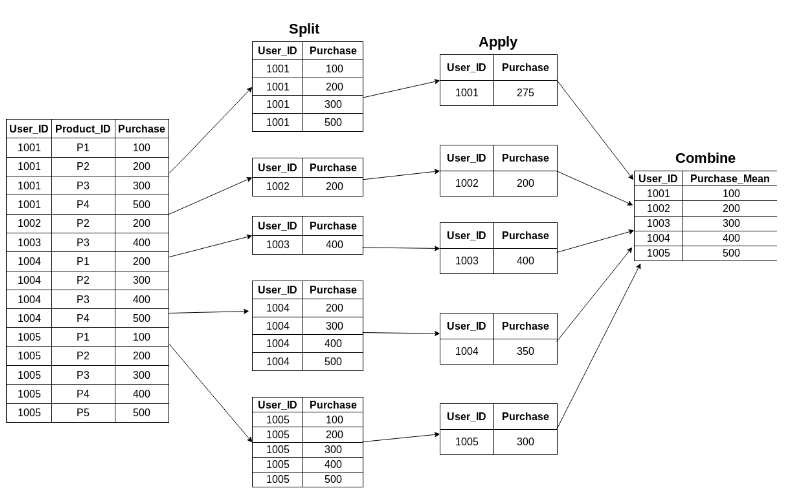
df["User_Mean"] = df.groupby('User_ID')["Purchase"].transform('mean')apply() vs transform()의 차이점
df['sum'] = df.apply(lambda row: row.a + row.b + row.c, axis = 1)위처럼 transform()은 전체 df를 연산할 수 없음
apply()는 각 열 연산 가능
df.T ==> 행 <> 열, Transpose

안녕하세요! 강민수입니다.