[코세라 Machine Learning]
8주차 Applying PCA
- PCA는 Training Set에 대해서만 해야하며, 이후에 Training Set에서 적용한 Mapping을 CV Set이나 Test Set에 적용해야 한다.
- 장점 :
1. 압축
- 저장되는 data의 memory/disk 감소
- 학습 알고리즘 속도 증가
2. 시각화
- k = 2 or k = 3으로 차원을 낮추어서 시각적으로 확인하기 용이해짐
- 오버피팅의 문제를 해결하려고 PCA를 사용하는 것은 좋지 않다. PCA는 정보의 양을 감소시키고, 특히 예측값에 상관없이 차원을 축소하기 때문에 꼭 필요한 정보를 잃을 수도 있다. 오비피팅의 문제를 해결하려면 정규화 regularization을 사용하는 것이 권장된다.
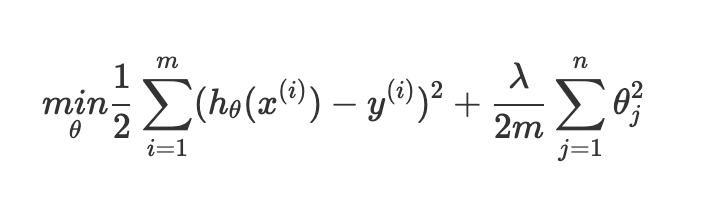
9주차 Density Estimation
- density estimation : 우리가 테스트한 샘플이 feature에 대해서 정상적일 확률을 계산해서 판단하는 것.
- 가우시안 분포 : 정규분포, 분산이 커질수록 그래프가 더 넓게 퍼지게 되고, 평군은 그래프의 중심을 이동시키는 축이 된다.
- anomaly detection algorithm :
- 비정상 데이터를 찾기 위한 feature를 선택한다.
- 각 feature의 평균과 분산을 구한다.
- 새로운 샘플 x에 대해서 p(x)를 구한다. 만약 특정 값 e(임계값)보다 작다면 이상이 있는 것이다.
