[Sol] Today I Learned
1.9, Nov 2021

Today I Learned 인프런 그로스해킹1\. PMFProduct Market Fit : 제품, 서비스가 실험을 할 만한 가치가 있는가확인 적합한 지표3)NPS(Net Promoter Score) : 0~6 Detractors, 7~8 Passives, 9~10
2.10, Nov 2021
코세라 Machine Learning1\. 6주차 Evaluating a Learning Algorithm성능 개선 get more training examples (high variance) try smaller sets of features (high varia
3.11, Nov 2021
loocvhttps://deep-learning-study.tistory.com/623
4.12 Nov, 2021
violinplot 과 boxplot에 hue 적용하려면 x의 값이 지정되어야 한다.
5.14, Nov 2021
referenceshttps://www.kaggle.com/anatpeled/spotify-popularity-predictionhttps://www.kaggle.com/gleblevankov/exploring-spotify-data
6.18 Nov, 2021
데이터가 독립적이고 동일한 분포를 가진 경우KFold, RepeatedKFold, LeaveOneOut(LOO), LeavePOutLeaveOneOut(LPO)동일한 분포가 아닌 경우StratifiedKFold, RepeatedStratifiedKFold, Strati
7.19 Nov, 2021
confusion matrix https://shinminyong.tistory.com/28isolation foresthttps://velog.io/@vvakki\_/Isolation-Forest-%EB%AF%B8%EC%99%84%EC%84%B1이상
8.25 Nov, 2021
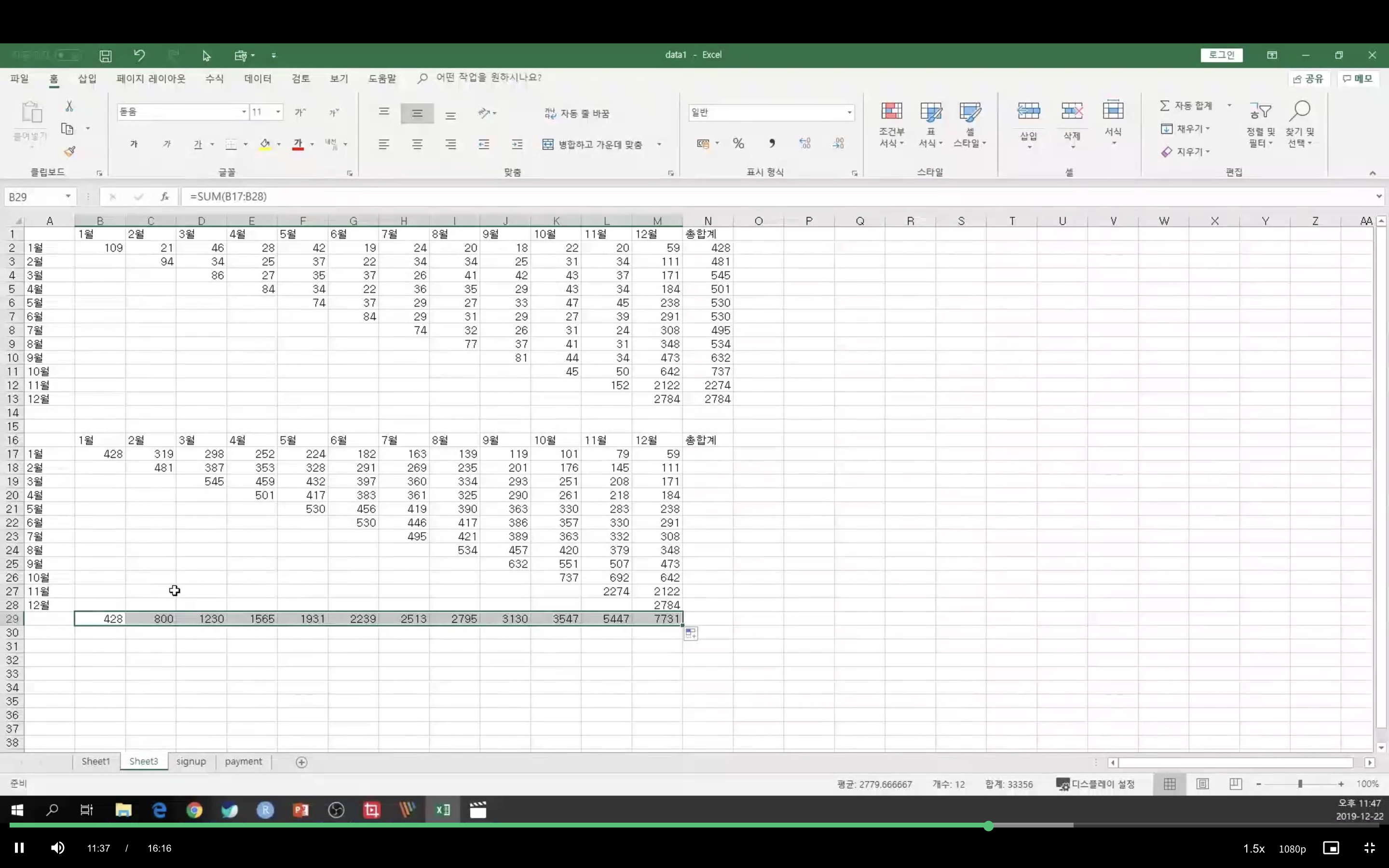
retention 계산MAU 1월 : 428 , 2월 800, 3월 1230 ...user_id로 가입 달 정보를 가져옴.달 마다 몇명의 유저가 구매를 하고 매출액이 얼마인지 구할 수 있음가입자 : retention 계산을 위해 만들었던 걸로 달마다 가입자수 알 수 있
9.27 Nov, 2021
공공 임대 상가 자료 https://www.data.go.kr/data/15069062/fileData.do
10.1 Dec, 2021
Robust scaler : 이 스케일러는 중앙값을 제거하고 Quantile 범위 (기본값은 IQR : Interquartile Range)에 따라 데이터를 스케일링합니다. IQR은 1 분위 (25 분위)와 3 분위 (75 분위) 사이의 범위입니다. 아웃라이어 영향을
11.2 Dec, 2021
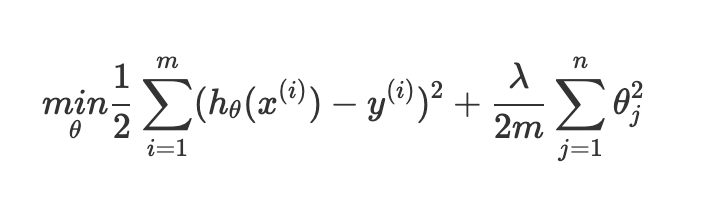
PCA는 Training Set에 대해서만 해야하며, 이후에 Training Set에서 적용한 Mapping을 CV Set이나 Test Set에 적용해야 한다.장점 : 1\. 압축 \- 저장되는 data의 memory/disk 감소 \- 학습 알고리즘 속도 증가
12.6 Dec, 2021

Supervised Learning vs Anomaly Detection : 수집한 training data가 정상데이터는 많은데 비정상데이터가 그에 비해 월등히 적을때 Anomaly Detection 모델 사용. Supervised learning 모델도 비정상 데이
13.7 Dec, 2021
OMTM : One Metric That Matters = North Star Metric지금 제일 중요한 지표 관리하는 것서비스 내에서 중요하게 생각하는 지표, 지표간의 우선순위가 명확해야함하나가 아니라 여러가지 지표일 수 있음OMTM과 KPI의 차이점 : OMTM은
14.8 Dec, 2021
머신러닝 알고리즘을 위한 데이터 준비를 함수를 만들어서 자동화해야하는 이유 : \- 어떤 데이터셋에 대해서도 데이터 변환을 손쉽게 반복할 수 있다.(예: 다음번에 새로운 데이터셋을 사용할 때)향후 프로젝트에 사용할 수 있는 변환 라이브러리를 점진적으로 구축하게 된다
15.9 Dec, 2021
RandomizedSearchCV하이퍼파라미터 탐색 공간이 커지면 사용가능한 모든 조합을 시도하는 대신 각 반복마다 하이퍼파라미터에 임의의 수를 대입하여 지정한 횟수만큼 평가함.규제처럼 설정값이 연속형인 경우 랜텀 탐색 권장.장점 : 랜덤 탐색을 1,000회 반복하도록