Mobile 서빙을 하기 전에 보기 좋은 글

Pytorch 딥러닝 모델을 모바일에 서빙 시 고려해야할 체크리스트
- 추론 속도
- 타겟에서 요구하는 최대 속도
- 예를들어 동영상 타겟이라면 최소 30ms 이내에 들어와야 끊기지 않고 플레이 가능
- 모델 크기
- 타겟이 요구하는 최대 용량
- 마켓에 올릴 수 있는 최대 용량에 제한이 있기 때문에 모델 용량이 크면 클 수록 다른 작업에 사용할 공간이 적어짐.
- IOS의 경우 앱스토어에 4GB, Android의 경우 Play Store에서 100MB까지 기본적으로 가능
- 메모리 사용량
- 타겟이 요구하는 최대 메모리 사용량
- 작은 디바이스에서는 메모리가 제한되어있기 때문에 사용량을 줄이는 것이 중요
- 배터리 사용량
- 모바일 딥러닝 모델은 배터리 수명에도 영향을 미침
- 배터리 수명을 고려하여 최적화해야 함
- 정확도
- 타겟이 요구하는 최소 정확도
- 당연하겠지만 정확도가 잘 나오는게 중요, 하지만 모델을 최적화하면서 정확도를 잡기는 쉽지 않음
- 기기 지원 여부
- 사용하는 프레임워크에서 지원하는 운영체제 여부
- 모바일 기기는 보통 Android, IOS가 대부분을 차지하고 있다.
- 연산자 지원 여부
- 사용하는 프레임워크에서 지원하는 연산자 여부
- 사용하려는 모델에 들어가는 연산자가 지원되는 지 확인해야함
체크리스트에 해당하는 문제를 어떻게 해결 할 것인가
가상 타겟 설정
- 요구사항 : 안드로이드와 IOS에서는 반드시 실행 가능해야함. 정확도는 Top-1 기준으로 70%는 넘겨야함. 동영상 서비스에 들어가야 하기 때문에 iPhone X에서 최소 30ms 이상의 속도가 나와야함.
아키텍처 선택
- 모바일 및 엣지 디바이스에서 사용할 목적으로 만든 아키텍처는 다음과 같다.
- MobileNet v1
- MobileNet v2
- MobileNet v3
- squeezenet
- MnasNet
- BlazeFace
- TinyYOLO / Darknet
- SqueezeNext
- ShuffleNet
- CondenseNet
- ESPNet
- DiCENet
- FBNet
- ChamNet
- GhostNet
- MixNet
- EfficientNet
- 그 중 블로거가 실제 CoreML을 활용해 실행해본 결과를 정리하였다.
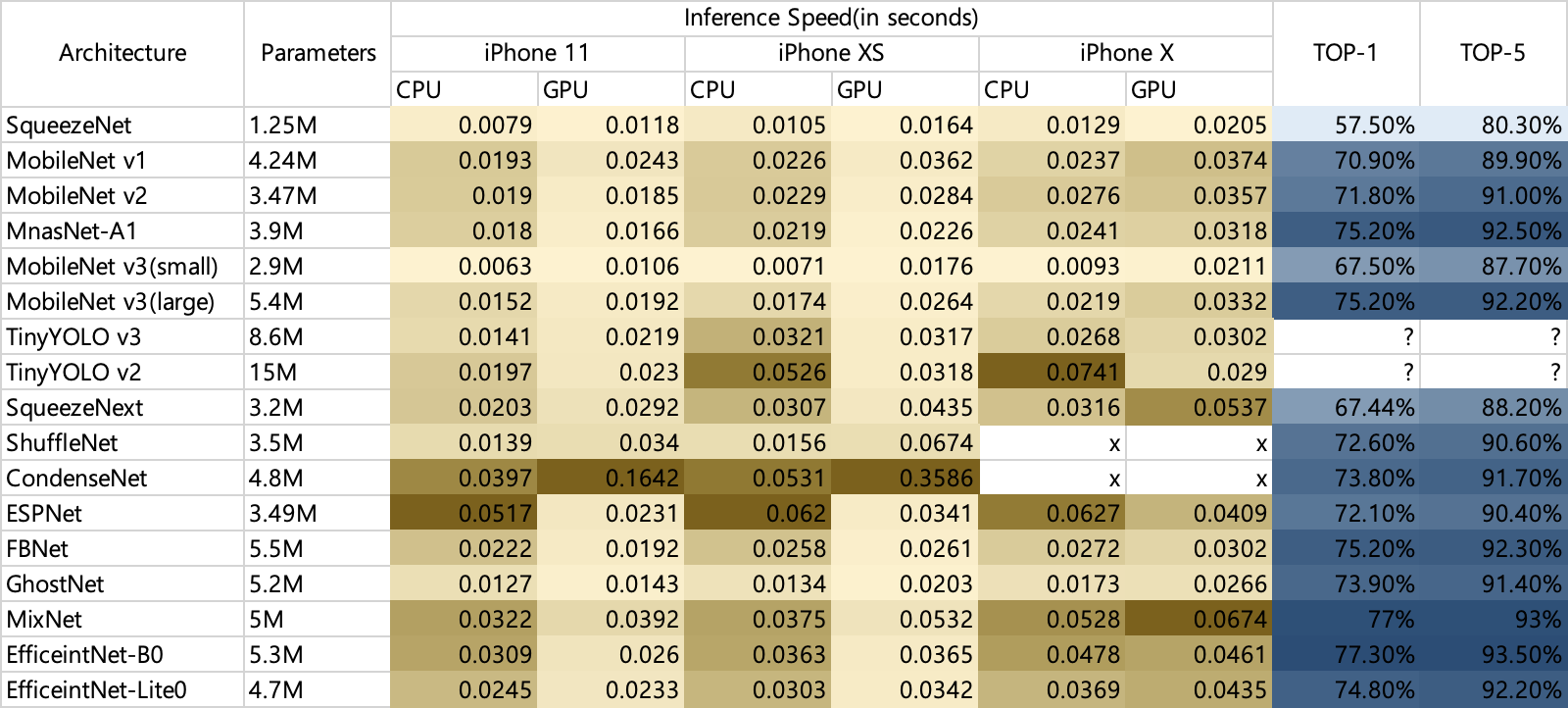
- 정확도도 높은 편이고, 추론속도도 빠른편인 MobileNet, MnasNet, GhostNet이 좋은 선택으로 보인다.
- 하지만 아키텍처만으로는 아직 만족스럽지 않기 때문에, 더욱 성능을 향상시킬 수 있는 방법을 찾아보자
아키텍처 최적화
- 위에서 선택한 아키텍처를 다양한 방법으로 최적화 할 수 있다.
- 학습 과정에 적용 가능한 방법도 있고, 프레임워크에서 지원하는 방법도 있다.
- 최적화 방법론
- Prunning
- 모델의 일부 가중치, 뉴런 혹은 Layer를 제거하여 모델의 크기를 줄이는 방법론
- Nonstructural pruning
- 특정 기준을 세워서 가지치기 하듯 무작위로 각각의 Weight들을 0으로 만들어버림.
- 실제로 구조가 달라지는 것이 아니다보니 실질적인 Inference 속도를 개선하긴 어려움
- Structural pruning
- 단위를 잡아서 특정 구조를 한번에 잘라냄.
- 네트워크 구조 자체가 사라지는 것이다보니, 실질적인 inference 속도를 개선할 수 있음.
- 구조를 통째로 날리는 것 이므로 pruning 하는 비율을 높게 하기 어려움.
- Network Quantization
- 기본적으로 Pytorch에서 학습이 완료된 결과물은 Float32 형임. 이것을 Float16 혹은 INT8 형으로 변경하여 용량 및 추론 속도를 향상시킬 수 있다.
- Quantization으로 얻을 수 있는 장점을 정리하자면 다음과 같다.
- 모델의 사이즈 축소
- 모델의 연산량 감소
- 효율적인 하드웨어 사용
- PTQ (Post Training Quantization)
- Float32 모델로 학습 한 후, 결과 Weight 값에 대하여 quantization 하는 방법
- 장점 : 파라미터 size가 큰 대형 모델에 대해서는 정확도 하락의 폭이 작음
- 단점 : 파라미터 size가 작은 소형 모델에 대해서는 정확도 하락의 폭이 큼
- QAT (Quantization Aware Training)
- 학습 진행 시점에 inference 시에 quantization 적용에 의한 영향을 미리 시뮬레이션 하는 방식
- 장점 : Quantization 이후 모델의 정확도 감소 폭을 최소화 할 수 있음
- 단점 : 모델 학습 이후 추가 학습이 필요함
- Knowledge Distillation
- 미리 학습된 대규모 네트워크의 지식을 모방하도록 작은 네트워크 모델을 학습
- 쉽게 말해 선생과 제자의 관계라고 보면 된다.
- 대규모 네트워크는 선생, 소규모 네트워크는 제자가 되어 선생 모델의 출력을 학습한다.
- Data Transformation
- 입력 이미지를 두개의 해상도 하위 이미지로 분해함.
- 하나는 고주파 정보를 전달하고, 하나는 저주파 정보를 전달함.
- 이미지 해상도를 줄이면서 원래 정보를 손실하지 않고 계산 속도를 달성함.
- 네트워크 구조를 변경해야해서 재 학습이 필요함
- Octave Convolution
- Prunning
프레임워크 선택
-
앞서 안드로이드와 IOS 기기에서 반드시 실행 가능해야 하기 때문에, Pytorch 만으로는 각 기기에 올리기가 어렵다.
-
아래는 모바일로 서빙하기 위해 사용 가능한 프레임워크들이다.
-
Tensorflow lite
-
텐서플로우 모델을 모바일, 임베디드, IoT 환경에서 돌릴 수 있도록 도와주는 툴
-
안드로이드, IOS, 내장형 Linux, 마이크로 컨트롤러 등 사용 가능
-
대리자를 통해 GPU, DSP, NPU 등 지원
모델 유형 GPU NNAPI Hexagon CoreML 부동점 (32bit) Y Y N Y 훈련 후 FP16 양자화 Y N N Y 훈련 후 동적 범위 양자화 Y Y N N 훈련 후 정수 양자화 Y Y Y N 양자화 인식 훈련 Y Y Y N -
pytorch 모델을 tflite 모델로 변경시키려면 다음과 같은 과정을 진행한다.
-
pytorch → onnx → Tensorflow → TFLite
- Requirement
- ONNX ==1.7.0
- PyTorch ==1.5.1.
- tensorflow==2.2.0 (Prerequisite of onnx-tensorflow. However, it worked for me with tf-nightly build
2.4.0-dev20200923as well) - tensorflow-addons==0.11.2
- onnx-tensorflow == 1.6.0
- pytorch to onnx
import onnx import torch example_input = get_example_input() # exmample for the forward pass input pytorch_model = get_pytorch_model() ONNX_PATH="./my_model.onnx" torch.onnx.export( model=pytorch_model, args=example_input, f=ONNX_PATH, # where should it be saved verbose=False, export_params=True, do_constant_folding=False, # fold constant values for optimization # do_constant_folding=True, # fold constant values for optimization input_names=['input'], output_names=['output'] ) onnx_model = onnx.load(ONNX_PATH) onnx.checker.check_model(onnx_model)- onnx to tensorflow
from onnx_tf.backend import prepare import onnx TF_PATH = "./my_tf_model.pb" # where the representation of tensorflow model will be stored ONNX_PATH = "./my_model.onnx" # path to my existing ONNX model onnx_model = onnx.load(ONNX_PATH) # load onnx model # prepare function converts an ONNX model to an internel representation # of the computational graph called TensorflowRep and returns # the converted representation. tf_rep = prepare(onnx_model) # creating TensorflowRep object # export_graph function obtains the graph proto corresponding to the ONNX # model associated with the backend representation and serializes # to a protobuf file. tf_rep.export_graph(TF_PATH)
- Requirement
-
tensorflow to tflite
TF_PATH = "./my_tf_model.pb" # where the forzen graph is stored TFLITE_PATH = "./my_model.tflite" # protopuf needs your virtual environment to be explictly exported in the path os.environ["PATH"] = "/opt/miniconda3/envs/convert/bin:/opt/miniconda3/bin:/usr/local/sbin:...." # make a converter object from the saved tensorflow file converter = tf.compat.v1.lite.TFLiteConverter.from_frozen_graph(TF_PATH, # TensorFlow freezegraph .pb model file input_arrays=['input'], # name of input arrays as defined in torch.onnx.export function before. output_arrays=['output'] # name of output arrays defined in torch.onnx.export function before. ) # tell converter which type of optimization techniques to use # to view the best option for optimization read documentation of tflite about optimization # go to this link https://www.tensorflow.org/lite/guide/get_started#4_optimize_your_model_optional # converter.optimizations = [tf.compat.v1.lite.Optimize.DEFAULT] converter.experimental_new_converter = True # I had to explicitly state the ops converter.target_spec.supported_ops = [tf.compat.v1.lite.OpsSet.TFLITE_BUILTINS, tf.compat.v1.lite.OpsSet.SELECT_TF_OPS] tf_lite_model = converter.convert() # Save the model. with open(TFLITE_PATH, 'wb') as f: f.write(tf_lite_model) ```
지원하는 연산자가 없다면?
- Tensorflow 연산자를 만든다
- TFLite 연산자로 등록한다
- 연산자를 생성하고 등록한다
- 테스트 및 프로파일링
-
-
CoreML
-
기계학습(Machine Learning)에 의한 이미지 분석, 텍스트 처리 등의 작업을 네트워크를 통하지 않고 기기(아이폰, 아이패드, 맥 등) 내의 AP를 이용하여 수행할 수 있도록 하는 라이브러리
-
Apple 하드웨어를 활용하고 메모리 공간 및 전력 소비를 최소화하여 다양한 모델 유형의 기기 내 성능에 최적화되어 있음
-
Apple 하드웨어에서만 사용 가능
-
pytorch 모델을 coreML로 변환하려면 torchscript 변환 후 coremltools를 사용한다
import torch import torchvision # Load a pre-trained version of MobileNetV2 torch_model = torchvision.models.mobilenet_v2(pretrained=True) # Set the model in evaluation mode. torch_model.eval() # Trace the model with random data. example_input = torch.rand(1, 3, 224, 224) traced_model = torch.jit.trace(torch_model, example_input) out = traced_model(example_input) import coremltools as ct # Using image_input in the inputs parameter: # Convert to Core ML program using the Unified Conversion API. model = ct.convert( traced_model, convert_to="mlprogram", inputs=[ct.TensorType(shape=example_input.shape)] ) # Save the converted model. model.save("newmodel.mlpackage")지원하는 연산자가 없다면?
- 모델 중간 언어(MIL) 연산자를 등록
- 1단계의 사용자 지정 연산자를 사용하도록 연산자를 정의
- 모델을 변환
- 1단계에서 제공된 바인딩 정보를 준수하여 Swift에서 사용자 지정 연산자를 구현
-
-
Pytorch Mobile
- Pytorch 에코시스템을 그대로 이용하면서 모바일 환경에 배포 가능하게 제공
- 아직 베타단계라 GPU, DSP, NPU등에 사용에 제한이 있음 (향후 지원 예정)
- 안드로이드, IOS 사용 가능
-
MNN
- 알리바바에서 제공하는 효율적이고 가벼운 딥 러닝 프레임워크
- 장치 내 추론 뿐만 아니라 학습도 지원
- OpenCV같은 이미지 처리 모듈도 지원 (100K 정도로 가벼움)
- 압축, 변환, 증류 등 다양한 최적화 도구 지원
-
Qualcomm Neural Processing SDK
- Snapdragon을 사용하는 기기에 대해 가속을 지원
- 런타임에서 로딩, 실행 및 스케줄링을 제어하기 위한 API
- 퀄컴 하드웨어에서 사용가능 (안드로이드, Linux)
-
MACE
- Xiaomi에서 만들었음. Mobile AI Compute Engine의 약자
- 런타임은 NEON, OpenCL 및 Hexagon으로 최적화되었으며 Winograd 알고리즘을 도입하여 컨볼루션 작업 속도를 높였음
- 그래프 수준 메모리 할당 최적화 및 버퍼 재사용이 지원됨
- Android, iOS, Linux 및 Windows 장치에서 사용 가능
-
Paddle lite
- paddle-paddle에서 파생된 오픈소스 딥러닝 프레임워크
- 다양한 하드웨어 및 장치를 지원하도록 설계되었음.
- Android and iOS, embedded Linux, Windows, macOS and Linux
-
NCNN
- Tencent에서 제공하는 크로스 플랫폼 추론 프레임워크
- 웹에서도 사용할 수 있는 웹 어셈블리도 지원
- Linux / Windows / macOS / Raspberry Pi3, Pi4 / Android / NVIDIA Jetson / iOS / WebAssembly / AllWinner D1 / Loongson 2K1000
-
-
참고한 자료
- https://reader.elsevier.com/reader/sd/pii/S2352864821000298?token=F9C4ECAE9824D07236ECFF84A8ABA9FC6BD9B7E0ADB0AE1D69D6E090FF6CE90A1F2CF7874EAE32E998B51558E08779CB&originRegion=us-east-1&originCreation=20230502032917
- https://towardsdatascience.com/on-the-edge-deploying-deep-applications-on-constrained-devices-f2dac997dd4d
- https://gaussian37.github.io/dl-concept-dwsconv/
- https://machinethink.net/blog/mobile-architectures/
- https://avivnavon.github.io/blog/parameter-sharing-in-deep-learning/
- https://www.alsemy.com/post/multitask-learning의-이해
- https://towardsdatascience.com/my-journey-in-converting-pytorch-to-tensorflow-lite-d244376beed
- https://developer.android.com/google/play/expansion-files?hl=ko
- https://gaussian37.github.io/dl-concept-quantization/
- https://simpling.tistory.com/50
- https://arxiv.org/pdf/1904.05049.pdf
- https://www.tensorflow.org/lite/guide/ops_custom?hl=ko
- https://coremltools.readme.io/docs/custom-operators

Deep learning for super-resolution