Super-Resolution에서의 INT8 변환 회고

개요
AI 반도체 장비 회사와 협업해 자사 Super-Resolution 모델을 INT8로 변경해야하는 작업을 수행해야했다. 처음엔 예제도 충분하고 INT8 Calibration 작업을 수행하기만 하면 되는 간단한 작업이었다. 그런줄 알았다…
문제 발생
문제는 Calibration 변환 이후 생겼다. 예제 상에선 1000회 정도면 성능이 비슷하게 나와야하는데 이미지가 전체적으로 어둡게 나오는 현상이 발생한 것.

원본 이미지

Pytorch로 변환한 이미지

Entropy Calibration 100회

Entropy Calibration 1000회
기존 Pytorch 이미지와 비교해봤을때, Int8 변환과정에서 전체적인 밝기가 떨어지는 현상이 발생했다. Calibration 횟수를 늘려봐도, Calibration 알고리즘을 변경해봐도 전체적인 밝기가 많이 떨어지고, 성능이 제대로 나오지 않는 문제였다.
문제 해결 방법 강구
그러던 중 관련 내용과 비슷한 문제점을 해결한 논문이 기억나 다시 읽어보았다. "Extremely Lightweight Quantization Robust Real-Time Single-Image Super Resolution for Mobile Devices" 라는 논문에서 해결의 힌트를 찾을 수 있었다.
논문에선,
Linear output activation function is very common among super resolution models and it helps with the model optimization. Although, not strictly enforced when the model converges we are pretty sure that the output will be bounded in between 0-255 (or 0-1.0). However, if such a model is quantized, the quantized output tend to be dull and accuracy can drop about 5-7dB compared to float16/32 model. The reason we believe is the following; during the earlier steps of training, the output is not guaranteed to be in between 0-1.0 and intermediate activations can also be unbounded or might contain outliers. Later on, if we continue with training the training data enforces boundedness in the model output indirectly. However, the intermediate activations of the model are not acted upon and the model may converge to a point near where its intermediate activations are unbounded, since model usually visits these points in the early stages of the training. These allowed intermediate unbounded activations create outliers (very large a few numbers). The outliers in intermediate layer activations, when uint8 quantized leads to some important information carrying, comparably low amplitude values to be zeroed out. Hence effective signal energy reaching to the last layer drops, which results in dull colors and drastic PSNR drops.
학습시 activation을 통과한 값이 무한대로 가는 경향이 있기 때문에, 중간 계층에서도 무한대로 가거나 굉장히 큰 특이치를 포함하고 있을 수 있다고 한다. 이렇게 생성된 특이치는, int8 변환시에 상대적으로 낮은 진폭 값을 0으로 만든다. 따라서 마지막 층에 도달했을 때, 신호 에너지가 떨어져 칙칙한 색상을 띄게 된다고 한다.
논문에서는 해결 방법으로 Cilpped ReLU 라는 것을 제안했다. 기존 ReLU 함수는 값이 0 이상이기만 하면 무한대의 값을 지닐 수 있는데, Clipped ReLU는 1을 넘어가는 값은 1로 처리해 값이 무한대로 발산하는 현상을 없앨 수 있다.
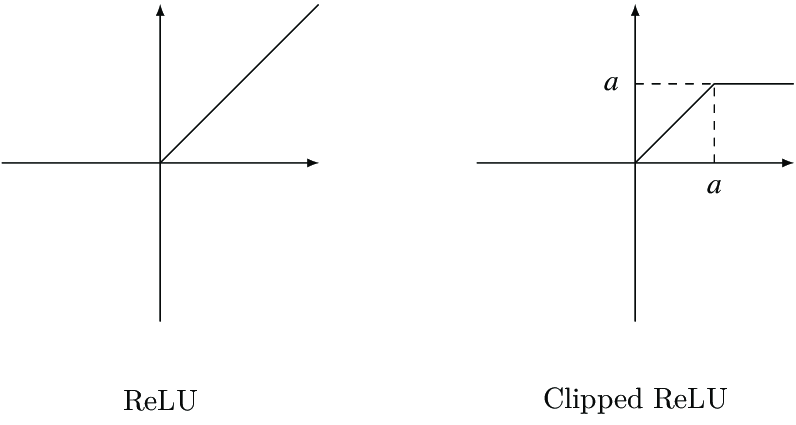
논문에서도, 모든 Activation을 바꾸는 것이 아닌 마지막단의 Activation만 Clipped ReLU로 변경하였다고 한다. 기존 Super-Resolution 모델 코드에서 마지막 단의 ReLU activation을 Clipped ReLU로 변경하는 작업을 수행했다.
그리고 어차피 기존 모델은 해당 장비에 올리기에 메모리가 너무 컸기 때문에 모델 크기를 줄여 처음부터 다시 학습했다. (이 부분은 뒷 부분에서 문제가 된다.)
class ClippedReLU(nn.Module):
def __init__(self):
super(ClippedReLU, self).__init__()
def forward(self, x):
return x.clamp(min=0., max=1.)문제 해결

원본

Pytorch 원본

문제 해결후 Entropy Calibration 1000회
앞선 모델보다 파라미터 수가 많이 줄었기 때문에 열화 개선 성능은 떨어지지만, INT8 변환시에도 Pytorch 모델과 인지적 차이가 크게 발생하지 않고, 밝기가 줄어드는 문제가 해결되었다.
Knowledge Distillation
하지만 문제는 앞서 장비에 올리기 위해 파라미터 수를 줄였기 때문에 기존 모델 대비 성능이 나오지 않는 문제가 있었다. 열화 개선 성능이 떨어지는 것은 두고볼 수는 없는 문제였다. 파라미터 수가 줄었더라도 차이가 없게 보이는 방법이 없는지 찾던 도중 Knowledge Distillation 기법에 대해 알게 되었다.
Knowledge Distillation은 이름의 뜻과 같게 지식을 증류시키는 방법이다. 간단하게 설명하자면 모델은 Teacher 모델과 Student 모델 둘로 나뉘어 Student는 자신 스스로 학습한 Loss와, Teacher에게서 나온 결과물을 비교해 Loss를 내어 그 두 Loss를 통해 학습하는 방법이다.

단순 학습 결과물 (850000회)

KD 학습 결과물 (850000회)
좌측은 Knowledge Distillation 없이 열화를 세게 주어 학습시킨 결과물이고, 우측은 Knowledge Distillation을 적용하여 같은 열화를 주어 학습시킨 결과물이다.
우측 이미지가 테두리 부분에서의 열화 제거 성능이 더 뛰어난 결과물을 볼 수 있다.
