코드
(공부하면서 배운 효율적인 코드 구현 방법: 1) 구현한 코드를 찾아 작동이 되는 것을 확인. 2) 코드 이해 {3) 주기적 복습 후 처음 부터 구현해 보기} 처음 부터 과거 스토리상 논문을 완벽하게 구현하겠다는 오기를 부리지 말것. 빠르게 처리해야할 일들이 많은 데 시간을 너무 잡아먹고 비효율적인 방법임; 기초가 되면 추후에 익숙해져서 구현하는 것도 늦지 않음.)
Step 1.
Title
: Going deeper with convolutions
Abstract
- Inception라는 깊은 convolutional neural network 구조를 제안함.
- 신경망 안의 컴퓨터 자원의 이용을 향상 시킴.
- 이것은 컴퓨터 예산을 유지하면서 신경망의 깊이와 넓이를 증가하도록 허락에 주는 세심하게 제작된 설계를 통해 달성함.
- 최적화를 위해 헤비안 원리(Hebbian principle)와 다중-규모(multi-scale) 과정을 기반으로 함.
- ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14)에 사용한 특별한 구조를 GoogLeNet(22층의 깊은 네트워크임)이라 부름.
Figures

Figure 1. ILSVRC 2014 분류 챌린지의 1000 클래스로부터 두 개의 구별된 클래스.
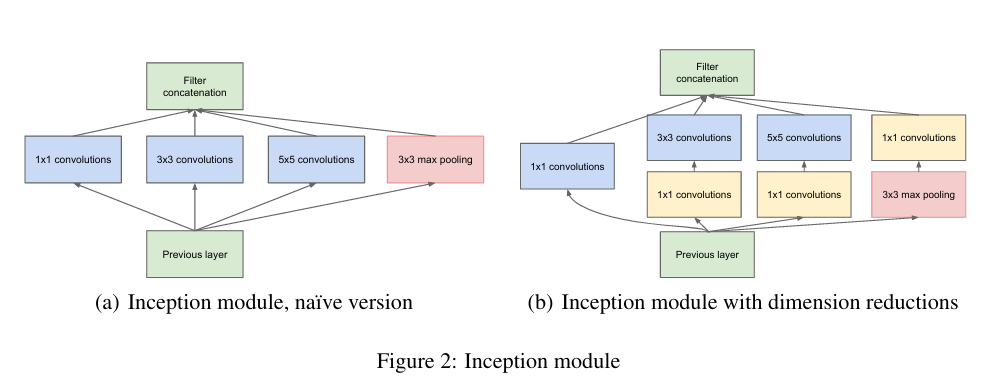
Figure 2. Inception 모듈 [(a) naive version의 Inception Module (b) 차원 감소와 함께 Inception Module]
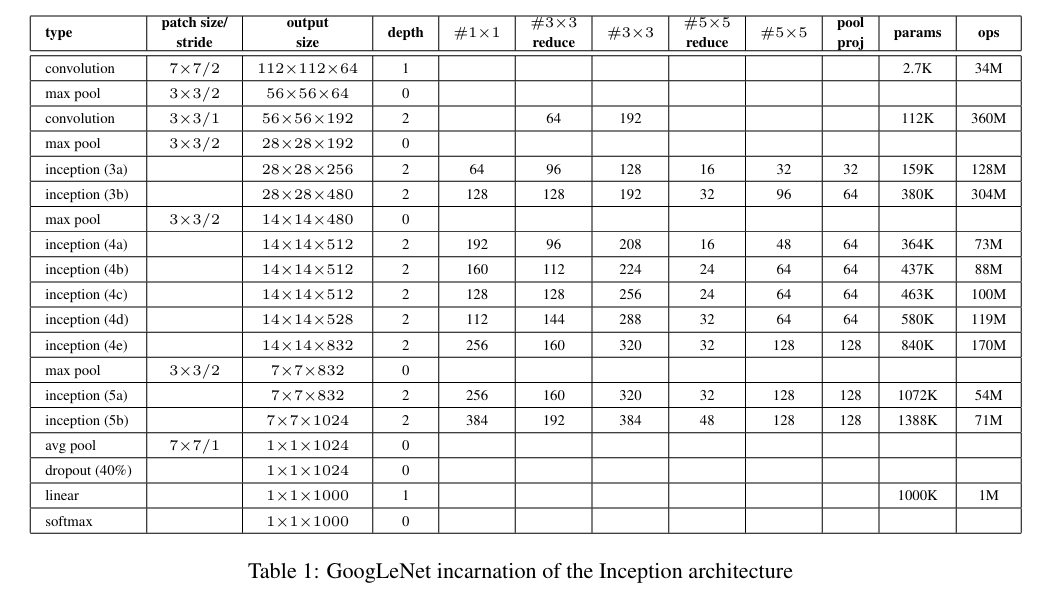
Table 1: Incpetion 구조의 GoogLet incarnation
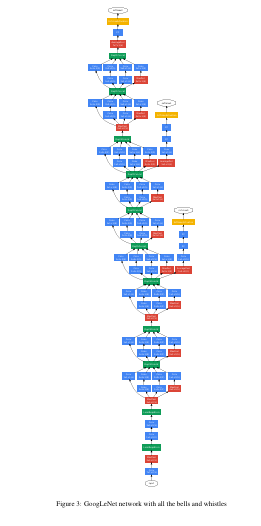
Figure3: 전체 bells과 whistles을 가진 GoogLet Network
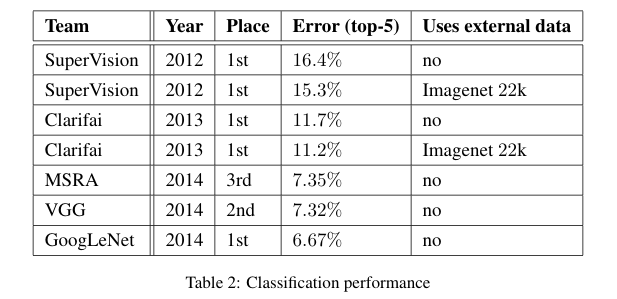
Table 2 : 분류 성능
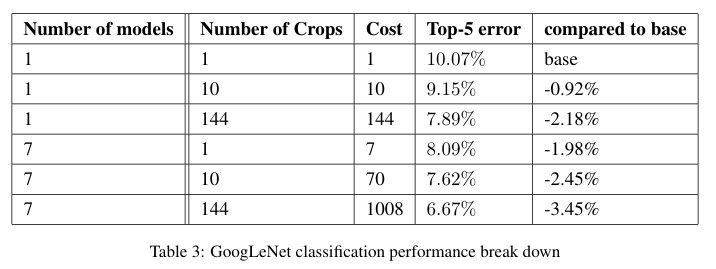
Table 3: GoogLeNet 분류 성능 break down
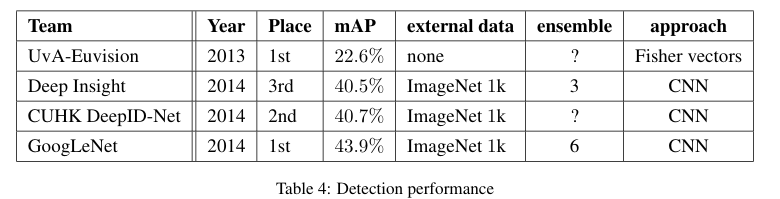
Table 4: 탐지 성능
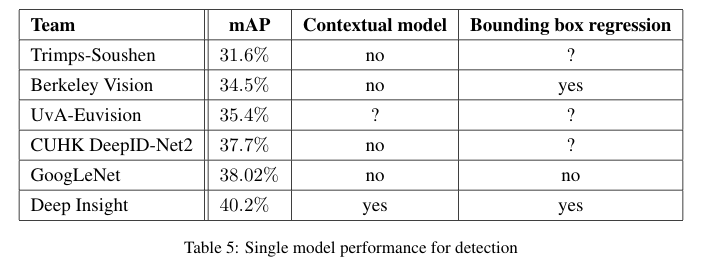
Table 5 : 탐지의 단일 모델 성능
Step 2.
Introduction
- GoogLeNet은 ILSVRC 2014에 제출함.
- 모바일과 embedded computing에 효과적일 수 있음.
- Inception이라 부르는 컴퓨터 비전 구조의 효과적인 깊은 신경망 구조에 초점을 맞춤.
Conclusions
- 손쉽게 이용가능한 밀집된 빌딩 블록들에 의해 근사적인 기대된 최적의 부족한 구조는 컴퓨터 비전에서 신경망을 향상시키는 실현가능한 방법이라는 명확한 증거를 보임.
- 이 방법의 주요 이점은 보통의 증가로도 상당한 품질을 얻을 수 있다는 것임.
Step 3.
논문에서 deep이라는 용어의 의미는 “Inception module”형태의 새로운 조직 레벨을 소개하는 것과 더욱더 신경망 깊이를 직접 증가시키는 것을 의미함.
2 Related Work
- Inception layers은 여러번 반복되어 22-layer depp model 일 때 GoogLeNet이라 함.
- 1x1 convolution 사용함.
: computational bottlenecks 제거함.
: penalty없이 깊이와 너비를 증가시킬 수 있음.
3. Motivation and High Level Considerations
가장 직접적으로 성능을 높이는 방법은 층을 늘리는 것이다. 하지만 결점이 두 개가 있는 데 하나는, 모델의 매개변수가 많아져, 과적합이 될 수 있다. 두 번째는, 모델이 커짐에 따라 컴퓨터 자원이 더 필요하다.
이 문제점들을 해결하기 위해 기본적인 방법은 전결합을 (심지어 컨벌루션 안의)공간적인 연결된 구조로 이동하는 것이다. 이것은 Hebbian principle와 연결된다.
4 Architectural Details
5 GoogLeNet
- ILSVRC14 competition에 적용한 특별한 Inception모델.
- Table 1에 GoogLeNet을 서술함. (Figure.3과 같이 보면 이해가 잘 됨.)
- Inception modules안에 포함된 모든 convolutions는 rectified linear activation을 사용함.
- receptive field의 크기는 224x224임(RGB color channels with mean subtraction.
- "#3x3 reduce"와 "#5x5 reduce"는 3x3과 5x5 convolutions을 사용하기 전에 reduction layer안에 1x1 filters의 개수를 의미함.
- 'pool proj' colum 안은 max-pooling 이후 앞에 던져진 1x1 filters의 개수도 의미함.
- 모든 이러한 reduction/projection layers은 rectified linear activation을 사용함.
- 오직 layers만 셋을 때 22 layers 깊이임. (pooling까지 셋을 경우 27 layers 이고 만들어진 blocks을 독립적으로 전체 layers의 개수는 약 100개임).
- 하지만, 심지어 fully connected layers을 제거한 이후에도 dropout의 사용은 필수적으로 남음.
- 5x5 filter size와 stride 3인 average pooling layer의 결과 4x4x512(4a), 4x4x528(4d) 출력임.
- 차원 축소를 위한 128개 filters를 가지는 1x1 convolution와 rectified linear activation.
- 1024 units의 fully connected layer와 rectified linear activation.
- 70% dropped outputs의 비율의 dropout layer.
- classifier에서 softmax loss의 linear layer.
