(논문 리뷰, 코드) VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(2015)
딥러닝 논문 리뷰
(https://arxiv.org/pdf/1409.1556v6)
논문 코드 구현 github
*핵심 파악
step1
### 1. Title
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
(큰규격이미지 인식을 위한 매우 깊은 컨벌루젼 네트워크)
2. Abstract
- very small (3x3) convolution filters의 구조를 사용하여 깊이를 증가한 네트워크를 평가하는 결과를 얻음.
- 16 - 19 계층의 깊이에서 상당히 성능이 향상된 것이 보임.
3. ImageNet Challenge 2014 submission을 기초로 함. - 표현은 다른 데이터셋에 잘 일반화
하였다되었다. - 대중적 연구를 위해 두 개의 성능좋은 ConvNet models을 만들었다.
3.Table(or Figures)
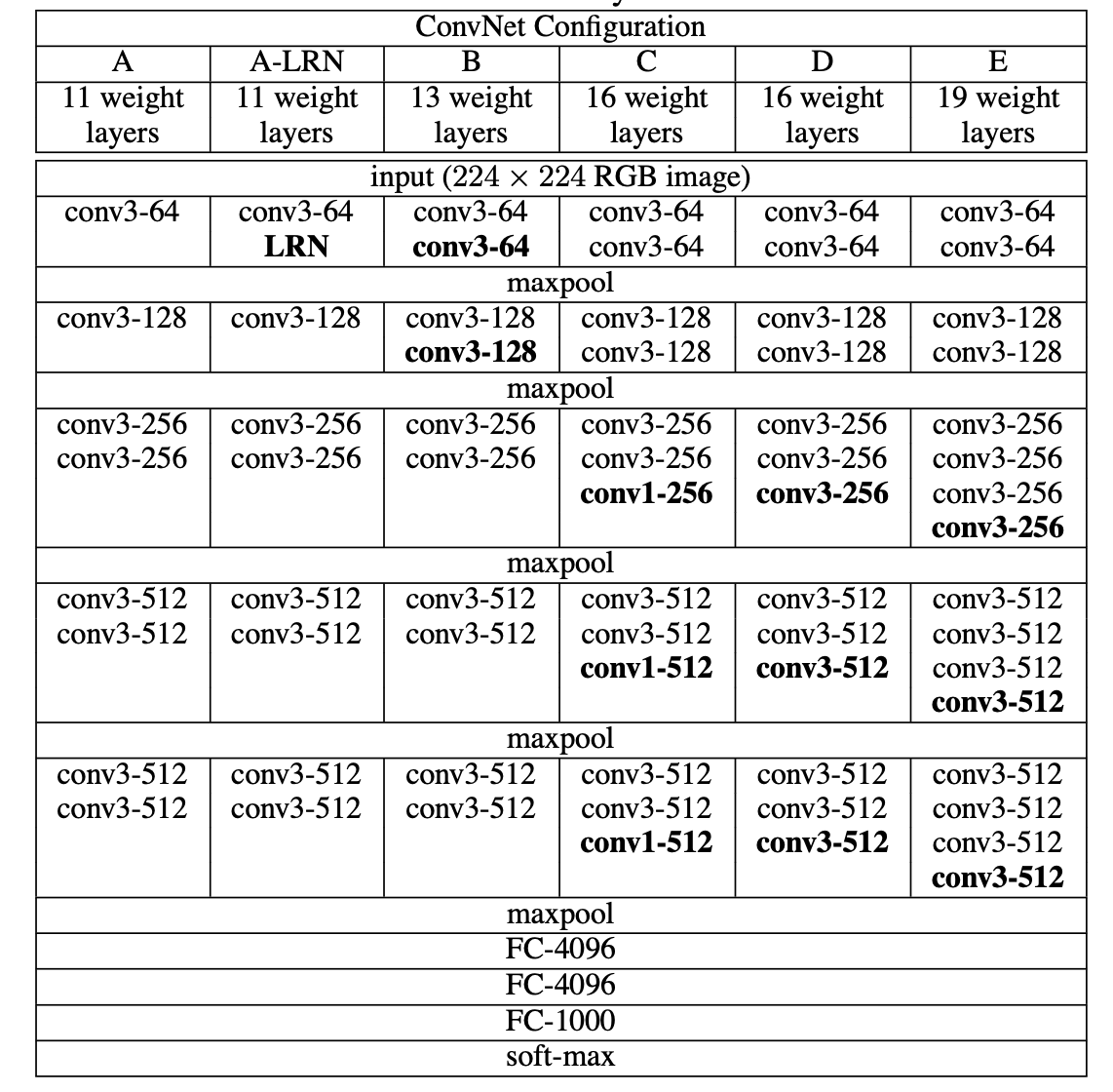
Table1. ConvNet configurations (shown in columns). The depth of the configurations increases from the left (A) to the right (E), as more layers are added (the added layers are shown in bold). The convolutional layer parameters are denoted as “conv⟨receptive field size⟩-⟨number of channels⟩”. The ReLU activation function is not shown for brevity.
Table1. 테이블의 열들은 ConvNet 구성들이다.
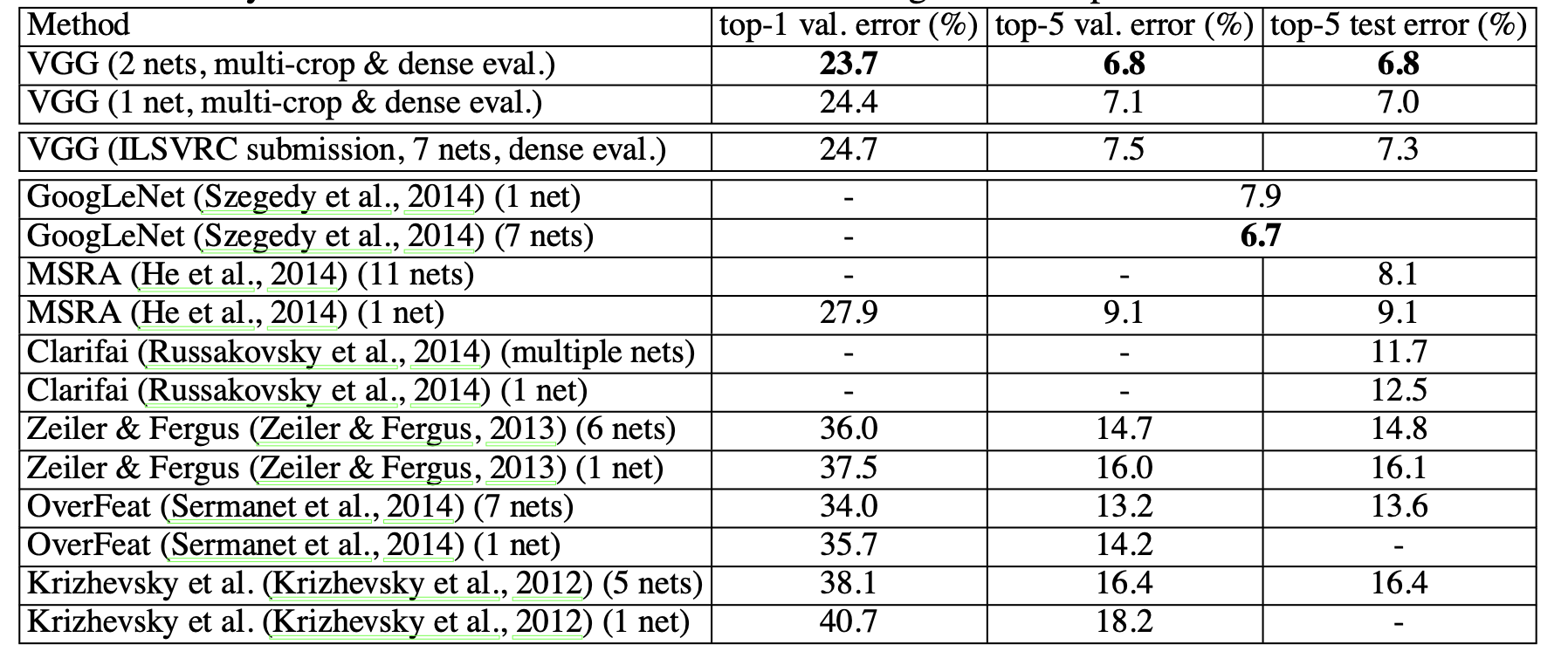
Table 7: Comparison with the state of the art in ILSVRC classification. Our method is denoted as “VGG”. Only the results obtained without outside training data are reported.
Table7. ILSVRC 분류에서 최신 모델들과 비교. (논문의 모델은 VGG로 표시)
step2
4. Introduction
In this paper, we address another important aspect of ConvNet architecture design – its depth. To this end, we fix other parameters of the architecture, and steadily increase the depth of the network by adding more convolutional layers, which is feasible due to the use of very small (3 × 3) convolution filters in all layers.
- ConvNet의 구성에서 깊이가 중요하다는 것을 보여줌.
- 구조의 다른 매개변수들은 고정시킨채 Convolutional layers을 더하며 점진적으로 네트워크의 깊이를 증가시킴.
- 모든 계층에 (3x3) convolution filters를 사용하여 실현가능함.
5. Conclusion
In this work we evaluated very deep convolutional networks (up to 19 weight layers) for large- scale image classification. It was demonstrated that the representation depth is beneficial for the classification accuracy, and that state-of-the-art performance on the ImageNet challenge dataset can be achieved using a conventional ConvNet architecture (LeCun et al., 1989; Krizhevsky et al., 2012) with substantially increased depth. In the appendix, we also show that our models generalise well to a wide range of tasks and datasets, matching or outperforming more complex recognition pipelines built around less deep image representations. Our results yet again confirm the importance of depth in visual representations.
- large-scale image classification을 위해 최대 19계층까지 매우 깊은 convolutional networks를 평가함.
- ImageNet challenge dataset에서 깊이를 표현하는 것은 유익하고 최첨단 성능이라는 것을 입증함.
- In the appendix에서 모델이 광범위한 작업과 데이터셋에서 잘 일반화 된다는 것을 보여줌.
6. 전반적으로 읽기
이해 파악
1. 저자가 뭘 해내고 싶어했는가?
small convolutional filters을 깊게 한 network model도 성능을 낼 수 있다는 것을 보여줌.
2. 이 연구의 접근에서 중요한 요소는 무엇인가?
small convolutional filters를 계층마다 최대한 깊게 쌓음.
- 당신(논문독자)은 스스로 이 논문을 이용할 수 있는가?
기존 모델에서 convnet을 깊게 하는 데 사용할 수 있을 것으로 판단. - 당신이 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
ensemble부분의아이디어에 대해 더 볼 필요가 있음.
(This improves the performance due to complementarity of the models, and was used in the top ILSVRC submissions in 2012 (Krizhevsky et al., 2012) and 2013 (Zeiler & Fergus, 2013; Sermanet et al., 2014).)
