(논문 리뷰, 코드 구현) ImageNet Classification with Deep Convolutional Neural Networks (2012)
딥러닝 논문 리뷰
목록 보기
1/6
step 1
- title
ImageNet Classification with Deep Convolutional Neural Networks
(깊은 Convolutional Neural Networks로 ImageNet 분류)
Abstract
1) 5 개의 convolutional layers와 이 중 몇 개의 계층에는 max-pooling layers이 따라오고, 3개의 fully-connected layers로 구성되어 있고 마지막 계층은 soft-max 계층임.
2) 학습을 더 빠르게 위해, non-saturating neurons과 convolution연산에 GPU를 사용하였다.
3) 과접합(overfitting)을 줄이기 위해서 fully-connected layers에 dropout을 적용하였다.
Figures and Tables
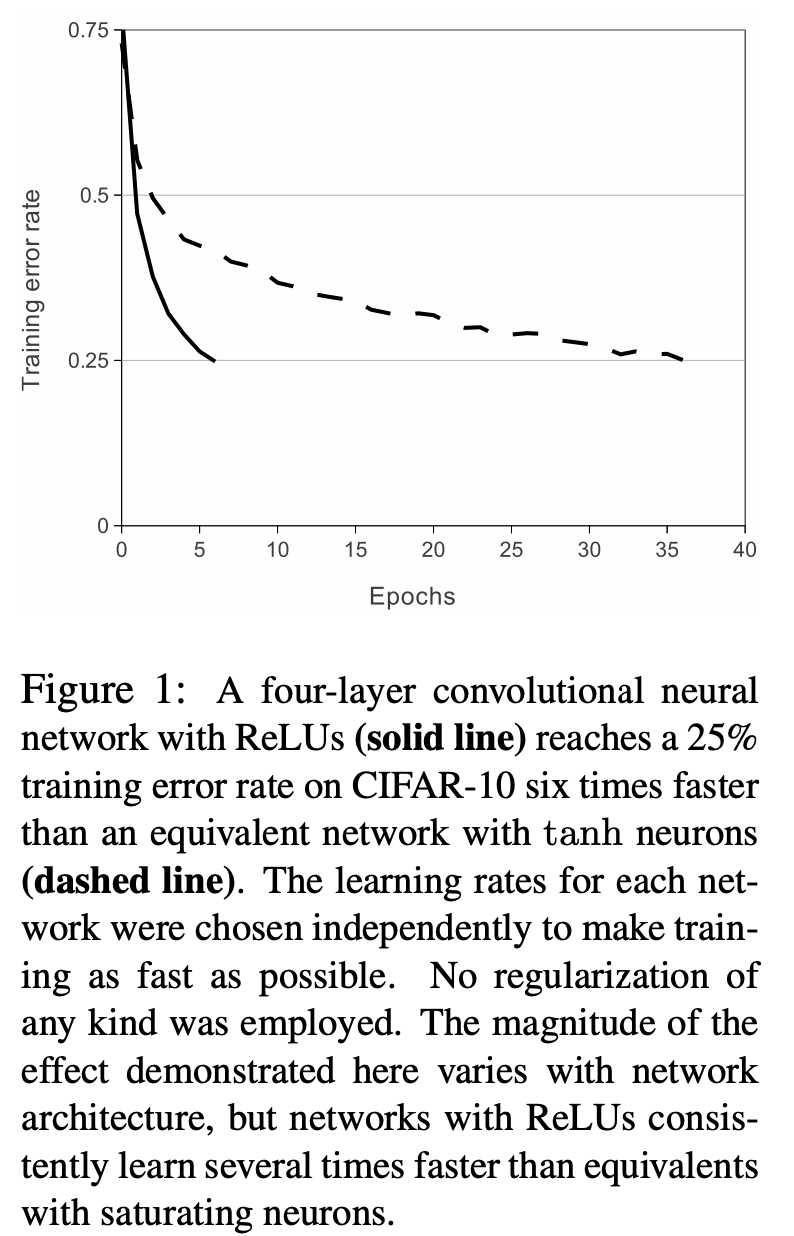
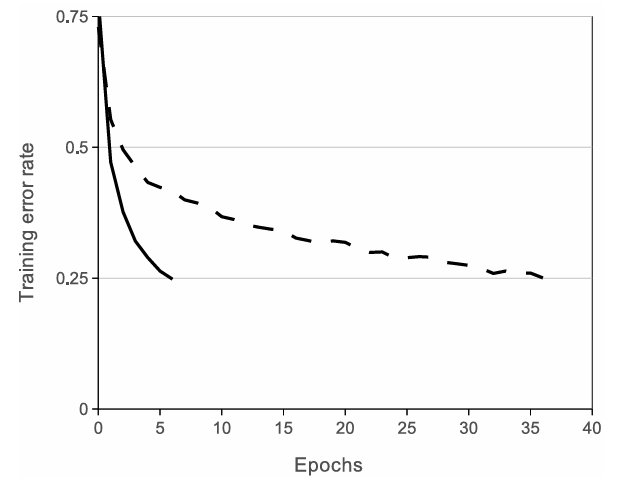
- ReLU와 함께 사용한 4개의 convolutional neural network이 tanh와 사용한 것보다 CIFAR-10에서 6배나 빠르게 25% training error rate에 도달함.
- 이 효과의 크기는 신경망 구조에 따라 변칙적이지만, ReLU를 쓴 신경망들은 saturating neurons 보다 몇 배는 빠름. (https://wikidocs.net/148850)
(https://simsim231.tistory.com/93)
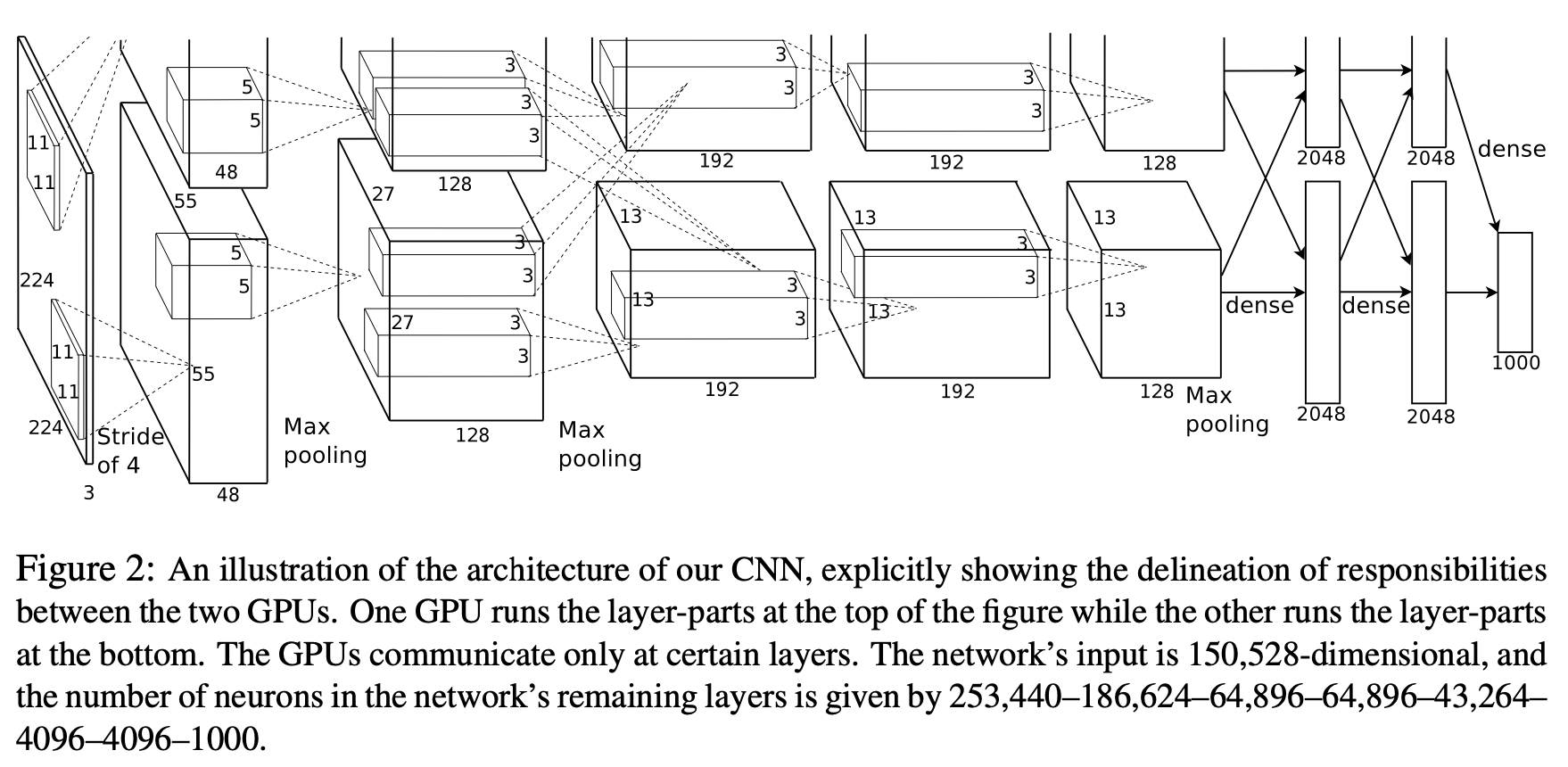
- AlexNet CNN의 구조.
- 두 개의 GPU를 사용하여 묘사.

- (3,11,11)의 convolutional kernels 96개로 (3, 224, 224)입력 이미지들을 첫 번째 convolutional layer에서 학습한 것을 보여줌.
- 위의 48개의 kernels은 GPU 1로 학습 한 것이고 아래의 48개의 kernels은 GPU로 학습 함.
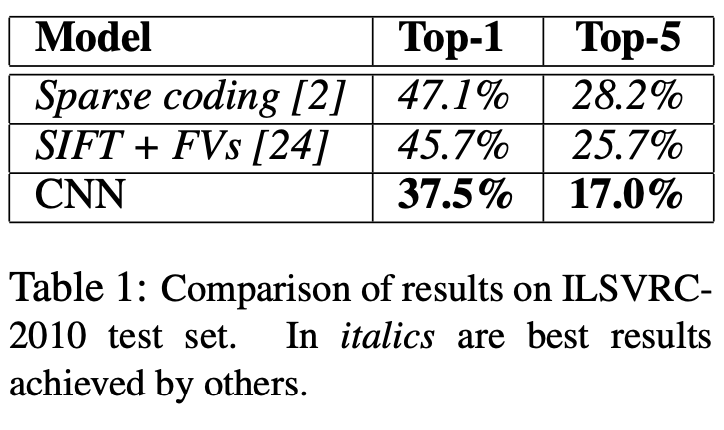
- ILSVRC 2010 테스트셋의 결과 비교.
- CNN이 다른 모델보다 좋은 결과를 얻은 것을 보여줌.
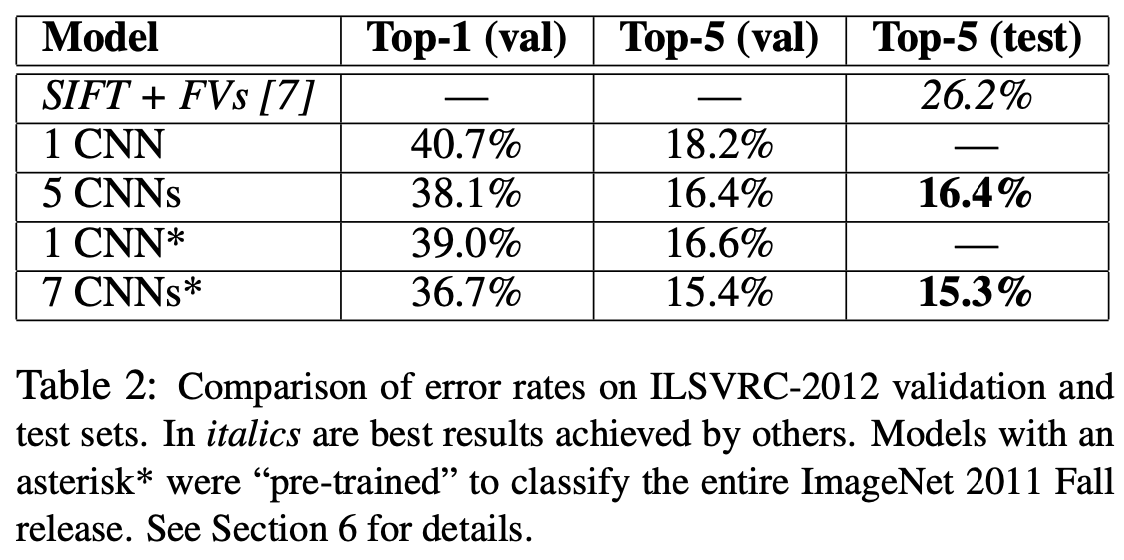
- ILSVRC-2012 검증과 테스트셋의 error rates의 비교.
- *(asterisk)는 ImageNet 2011 Fall의 전체를 분류하기 위한 "pre-trained"(사전 학습된) 모델임.

- (좌측) 8개의 ILSVRC-2010의 테스트 이미지들이다.
모델에서 가장 확률이 높은 5개의 라벨들을 보여주고 있다. - (우측) 첫 번째 열은 ILSVRC-2010 테스트 이미지들이다. 나머지 6개 열들은 학습한 이미지들임.
step2
Introduction
- 현재 필수적으로 머신 러닝 방법론이 객체 인식에 사용됨.
- 성능을 향상시키기 위해 대량의 데이터셋을 모았고, 과적합을 방지하기 위한 더 좋은 기술을 사용함.
- 지금까지 데이터셋은 수만개로 작았음 (e.g., NORB [16], Caltech-101/256 [8, 9], and CIFAR-10/100 [12]).
- 지금은 GPU덕분에 심각한 과적합(over-fitting)없이 CNN을 적용할 수 있음.
- 120만개의 학습 데이터에도 신경망의 크기는 과적합을 만듬.
- 그래서 과적합을 막기 위한 효과적인 몇 가지 방법을 사용함.
- 최종 신경망은 5개의 convolutional과 3개의 fully-connected layers임.
- 어떠한 convolutional layer을 제거하면 낮은 성능을 얻어, 신경망의 깊이는 상당히 중요해 보임.
- 신경망 사이즈는 이용가능한 GPU의 메모리 양으로 제한되어 있음.
- 우리의 결과는 더 큰 데이터 셋과 더 빠른 GPUs로 향상시킬 수 있음.
(## Results)
Discussion
- 크고, 깊은 convolutional neural network는 순수히 지도 학습을 사용한 모델에 비해 최고 수준의 성과를 냄.
- 하나의 convolutional layer가 제거 된다면 성능이 하락함.
- 따라서 깊이는 우리의 결과들을 성취하는 데 중요함.
- 실험을 간단화하기 위해, 어떠한 비지도사전학습을 사용하지 않음(도움이 될 것을 알고 있어도).
- 따라서, 우리의 결과는 신경망을 더 크게 하거나, 학습을 더 오래하면 향상시킬 수 있음.
step3 (모델 코드 구현)
Datasets
- image를 중심의 256x256 patch로 자름.
- 학습 데이터의 각 픽셀을 평균(mean activity)을 뺀 것을 제외하고 사전 처리하지 않음 (원시 RGB 픽셀들의 값들임)
Architecture
- Figure 2에 신경망 구조를 요약함 (총 8개의 계층 : 5개의 convolutional과 세 개의 fully-connected임)
ReLU Nonlinearity 사용
- 25% training error의 도달을 빠르게 함.
Training on Multiple GPUs
Local Response Normalization
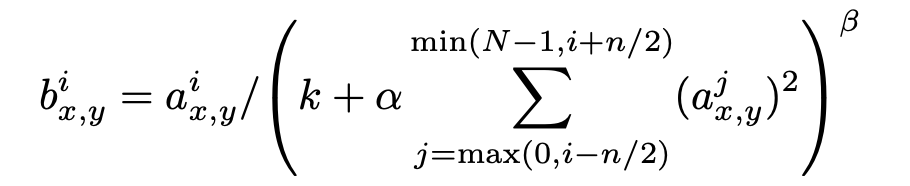
- k, n, , 는 하이퍼파라미터임.
- k = 2, n = 5, = 10-4고 = 0.75로 설정함.
- ReLU nonlinearity 적용 이후 적용함.
Overlapping Pooling
- pooling size z가 3이고 stride = 2을 적용함.
- non-overlapping schems s = 2, z =2 보다 error가 감소함(0.4% and 0.3%).
Overall Architecture
- 총 8개의 계층으로 구성 됨 (처음 5개는 convolutional이고 나머지 세 가지는 fully-connected이고 마지막 fully-connected layer은 1000-way softmax임)
- 2, 4, 5번째 convolutional layers are connected only to those kernel maps in the previous layer which reside on the same GPU.
- 3번 째 convolutional layer는 두 번째 layer의 모든 kernel maps에 연결되어 있음.
- Rsponse-normalization layers는 1, 2 번째 convolutional layers에 따라옴.
-Max-pooling layers는 response-normalization layers 뿐만 아니라 5 번째 convolutional layer에 따라옴. - ReLU는 모든 convolutional과 fully-connected layer에 적용됨.
- 첫 번째 convolutional layer는 (3, 11, 11) kernel size에 filter number 96개이고 stride는 4임.
- 두 번째 convolutional layer는 첫 번째 convolutional layer을 거친 후 response-normalized와 pooled를 적용한 데이터를 받ㄷ고, filters는 (48, 5, 5)size에 256개의 kernels임.
- 세 번째, 네 번째, 다섯 번째 convolutional layers는 pooling과 normalization layers와 연결하지 않음.
- 세 번째 convolutional layer는 (256, 3, 3) size인 kernels이 384개이고 두 번째 convolutional layer에서 normalized와 pooled를 통과하여 출력된 특성과 연결되어 있음.
- 네 번째 convolutional layer는 (192, 3, 3) size의 384개의 kernels임.
- 다섯 번째 convolutional layer는 (192, 3, 3) size의 256 개 kernels을 가지고 있음.
- fully-connected layers는 각각은 4096개의 뉴런들을 가짐.
Reducing Overfitting
- 학습 데이터로 사용한 ILSVRC의 1000 classes도 매우 많은 매개변수들을 학습하기에는 결과적으로 충분하지 않아 상당한 과적합이 생김.
- 과적합을 피하기 위한 두 가지의 주요한 방법을 서술함.
Data Augmentation
- 과적합을 피하기 위한 가장 공통된 방법은 데이터를 증강하는 것임.
- horizontal reflections
- 256 x 256 images로 부터 random 224 x 224 patchs ( and horizontal reflections)를 추출함.
- test시에는 다 섯개의 224 x 224 patches(4개의 corner patches와 center patch)를 추출하고 horizontal reflections함 (모두 10개의 patches).
- 그리고 예측의 평균은 10개 patches의 신경망의 softmax layer에 의해 만듬.
- 두 번째 데이터 증강 방법은 RGB channels의 세기를 대체하는 것임.
Dropout
- 첫 번째, 두 번째 fully-connected layers에 이용함 (p = 0.5로 설정).
Details of learning
- SGD를 사용함 (momentum = 0.9, weight decay = 0.0005).
- batch_size = 128임.
- 각 계층의 가중치를 초기화함 (평균은 0, 표준 편차는 0.01로 Gaussian distribution을 따름).
- 두 번째, 네 번째, 다섯 번 째 convolutional layers와 fully-connected hidden layers의 편향을 constant 1로 초기화하고 나머지 layers의 편향은 constant 0으로 초기화함.
- learning rate는 동등하게 사용.
- validation error rate가 멈추면 10으로 나누어 진행.
- learning rate의 초기값은 0.01임.
- 대략 90 cycles을 신경망을 학습시킴(두 개의 NVIDIA GTX 580 3GB GPUs로 5~6일 걸림).
