
Spark SQL의 query를 통한 데이터 집계와 DataFrame의 API를 활용한 데이터 처리의 차이를 분석하고, 어떤 방식이 더 효율적인지 알아보자
개요
Spark는 대규모 데이터 처리와 분석 환경을 쉽게 제공해주어, 실무에서 많이 사용되는 프레임워크 중 하나이다. 예전엔 Spark의 RDD를 이용해 Spark를 다루었다면, 현재는 조금 더 추상화 레벨이 높은 DataFrame을 이용해 Spark를 사용한다. 하지만 Spark DataFrame을 사용하다보면 궁금한 점이 하나 생긴다. 바로 Spark SQL에서 직접 쿼리를 수행하는 것과 DataFrame API(e.g. withColumn, groupBy, ..)를 사용하는 것 중, 어느 것이 성능 상 더 효율적일까 하는 질문이다. 두 방법 모두 같은 동작을 수행하도록 코드를 작성할 수 있는데, 그렇다면 어떤 것을 이용해야 더 효율적인 코딩이 가능한지 궁금해진다. 🤔
사용 방법
Spark SQL과 DataFrame API를 비교하기 전, 먼저 두 가지의 사용 방법에 대해 알아보자. 참고로 필자는 pyspark를 이용하기 때문에 pyspark 기준으로 설명할 예정이다. 물론 pyspark도 JVM 위에서 돌아가기 때문에 다른 언어에서 동작하는 방식도 비슷하지 않을까 생각한다.
예를 들어 다음과 같이 human 테이블이 있다고 가정하자.
| id | name | age | gender | city |
|---|---|---|---|---|
| 100 | datast | 33 | M | Seoul |
| 101 | sea | 26 | M | Jeju |
| 102 | lala | 25 | F | Gangneung |
| 103 | yei | 14 | M | Busan |
| 104 | garten | 21 | F | Incheon |
| 105 | iron | 44 | M | Seoul |
| 106 | mios | 29 | F | Seoul |
| 107 | kei | 18 | F | Busan |
| 108 | annian | 28 | M | Seoul |
그리고 다음과 같은 요청을 하려고 한다.
각 도시별로 나이가 40 이하인 사람들이 몇 명이 살고 있는지, 나이의 평균값과 같이 알려줘.
결과는 많이 거주하고 있는 순서대로 보여줬으면 좋겠어.
이때 Spark SQL과 DataFrame API는 각각 다음과 같이 방식으로 데이터를 처리할 수 있다.
Spark SQL 방식
# human_df contains 'human' data
human_df.createOrReplaceTempView("human")
result_df = spark.sql("""
select city, count(*) as `count`, avg(age) as `avg age`
from human
where age <= 40
group by city
order by 2 desc
""")
result_df.show()Spark DataFrame API 방식
# human_df contains 'human' data
import pyspark.sql.functions as F
result_df = human_df.filter(human_df["age"] <= 40) \
.groupby(["city"]) \
.agg(F.count(human_df["id"]).alias("count"), F.avg(human_df["age"]).alias("avg age")) \
.sort("count", ascending=False)
result_df.show()결과
+---------+-----+-------+
| city|count|avg age|
+---------+-----+-------+
| Seoul| 3| 30.0|
| Busan| 2| 16.0|
| Jeju| 1| 26.0|
|Gangneung| 1| 25.0|
| Incheon| 1| 21.0|
+---------+-----+-------+보이는 것과 같이 Spark SQL을 이용하기 위해선 먼저 DataFrame을 테이블 형태로 변환해야 한다. 그리고 그 테이블을 이용해 SQL을 직접 작성한 뒤, 해당 쿼리문을 spark가 실행하도록 만들고 결과를 DataFrame 형태로 받아온다.
반면 DataFrame API는 DataFrame에서 제공하는 함수들을 이용해 데이터 요청 업무를 수행한다. 중간에 aggregate 하는 부분에서도 이미 정의되어 있는 pyspark.sql의 함수를 이용한다.
이처럼 두 가지 방식으로 코딩이 가능한데, 어떤 방식을 이용해야 효율적으로 데이터 처리가 가능할까? 간단히 생각했을 때 SQL 방식은 spark가 대신 해당 쿼리를 수행하므로 더 비효율적일거라 생각이 들지만, 반대로 spark에서 SQL에 대한 최적의 처리 방식이 구현되어 있다면 해당 방법을 이용하는 것이 더 좋을 수 있다.
비교
결론부터 말하면 처리 방식은 동일하다..! 🫢 엄밀히 말하면 성능적인 측면에서 큰 차이는 없다. 그 이유는 Spark 자체가 JVM 위에서 동작하는데, 이때 py4j(python for java) 라이브러리를 의존성을 갖게된다. 해당 라이브러리에는 java_gateway.py 파일이 존재하는데, 이 파일에서 직접 JVM을 불러와 사용한다.
SparkSession의 sql 함수 (Spark SQL 방식)
def sql(self, sqlQuery: str, **kwargs: Any) -> DataFrame:
formatter = SQLStringFormatter(self)
if len(kwargs) > 0:
sqlQuery = formatter.format(sqlQuery, **kwargs)
try:
return DataFrame(self._jsparkSession.sql(sqlQuery), self)
finally:
if len(kwargs) > 0:
formatter.clear()6번째 줄을 보면 _jsparkSession이라는 JavaObject를 사용하는 것을 알 수 있다. 이 객체에서 sql을 실행하는데, 해당 객체의 클래스가 바로 py4j의 java_gateway.py 파일에 정의된 클래스이다.
Spark DataFrame의 groupBy 함수 (Spark DataFrame API 방식)
def groupBy(self, *cols: "ColumnOrName") -> "GroupedData":
jgd = self._jdf.groupBy(self._jcols(*cols))
from pyspark.sql.group import GroupedData
return GroupedData(jgd, self)DataFrame의 경우도 2번째 줄을 보면 _jdf라는 JavaObject를 사용하는 것을 알 수 있다. 따라서 두 방식 모두 JVM을 불러와 그 위에서 동작함을 알 수 있다.
참고: Spark RDDs vs DataFrames vs SparkSQL
위 결과를 증명이라도 하듯 이미 실험을 해본 사람이 존재한다. 물론 이 사람은 단순히 속도 비교만 했기 때문에 완벽한 결과라고 볼 수는 없겠지만 그래도 참고가 되리라 생각한다. (심지어 게시글도 2016년도..)
아래 사진은 위 사이트에서 실험한 결과이다. 보이는 것과 같이 Spark SQL과 Dataframe API와의 속도 차이는 크지 않다는 걸 알 수 있다. 자세한 내용은 해당 링크에 들어가서 확인할 수 있다.
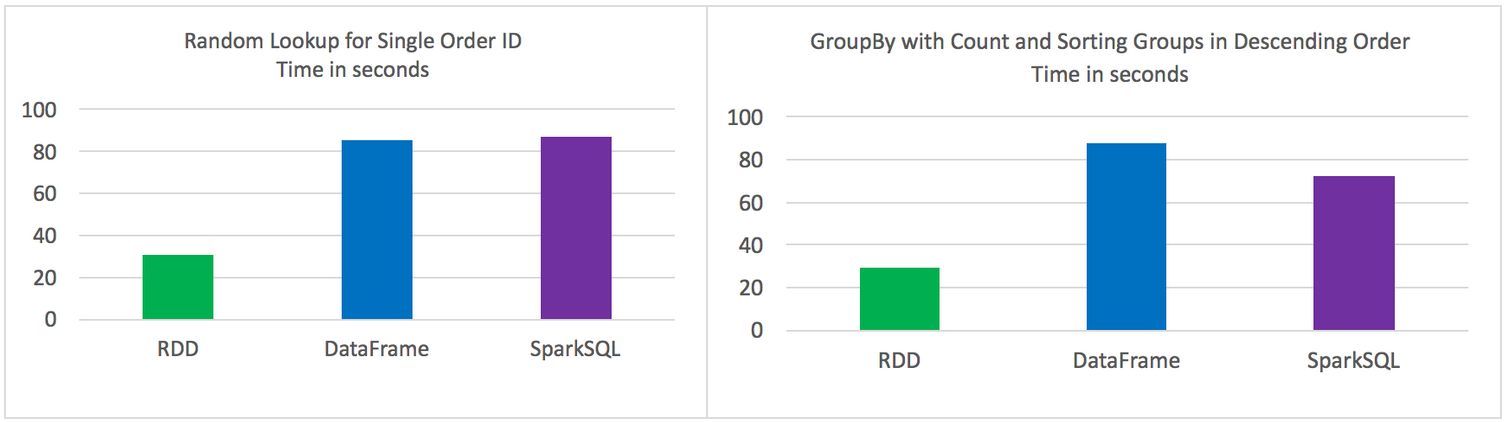
어찌보면 당연한 결과일 수 밖에 없다.. 필자는 DataFrame API가 좀 더 효율적인 방법, 혹은 파이썬 레벨에서 최적화 되는 방식이 있을 줄 알았지만 그런건 없었고, 정말 Dataframe은 API의 역할만 하는 것이였다.. 🥲
두 방식의 장단점
그렇다면 다시 한번 질문이 생긴다. 두 방식의 성능 차이가 크지 않다면 어떤 걸 이용하는게 더 좋을까? 이 질문에 대한 해답은 모두가 잘 알고 있을테지만,, 간단하게 말하면 각자의 선택에 따라 다르다..! 하지만 선택을 하기 위해 각각의 장단점에 대해 알아볼 필요가 있는데 이를 표로 한번 정리해봤다.
| Spark SQL | Spark DataFrame API | |
|---|---|---|
| 장점 | 1. SQL이 익숙한 사람에게 편리하다 | 1. 각각의 실행 과정을 모듈화 할 수 있다 |
| 2. 쿼리가 하나로 되어 있어 이해하기 쉽다 | 2. 컴파일 에러시 코드 수정이 용이하다 | |
| 3. 간단한 로직의 경우 빠르게 처리가 가능하다 | 3. 쿼리 문법 외에도 제공하고 있는 다양한 함수를 활용할 수 있다 | |
| 단점 | 1. 쿼리에 대한 유지보수가 어렵다 | 1. API 사용에 대한 학습이 필요하다 |
| 2. 에러가 났을 경우 확인하기 어렵다 | 2. 코드가 길어지다보면 동작을 이해하기 어려워진다 | |
| 3. 쿼리가 길어질 경우 가독성이 떨어진다 | 3. 일부 케이스에 대해선 SQL이 훨씬 간단하게 질의를 처리할 수 있다 |
Spark SQL의 장점은 DataFrame API의 단점이고, DataFrame API의 장점은 Spark SQL의 단점임을 알 수 있다. 이처럼 각자가 커버하는 것들이 다르기 때문에 모두에게 최고의 선택지란 존재하지 않는다. 또한 위에선 장점이라한 부분도 어떤 사람에게선 단점이 될 수도 있다. (SQL을 모르는 사람이면 SQL을 배우는 것 부터 단점이 될 수 있다) 결국 어떤 방식을 사용하던 상황에 맞게 선택지를 골라야 하며, 주어진 요구사항을 잘 해결할 수 있는 방향으로 개발을 진행해야 한다. 👩💻
결론
- Spark SQL과 DataFrame API는 둘 다 JVM을 호출하여 쿼리를 수행하므로 성능 상 큰 차이가 없다.
- Spark SQL의 경우, 읽고 이해하기 쉽다는 장점이 있지만, 쿼리에 대한 유지보수가 어렵다는 단점이 있다.
- DataFrame API의 경우, 각각의 과정을 모듈화 할 수 있다는 장점이 있지만, 복잡한 로직의 경우 이해하기 어렵다는 단점이 있다.

작성해주신글이 쉽게 설명해주셔서 그동안 이해하지 못한부분도 많이 알게 되었는데요
요즘에 SCALA 를 공부하고 있어서 궁금한 점이 있어서요
SPARK 가 지원하는 언어중에 SCALA 와 PYTHON 이 대중적으로 사용하는데
SCALA 가 PYTHON 보다 처리 속도가 빠른것으로 알고있습니다.
DATAFRAME 을 SCALA 로 작성하여 사용하는것과 SPARK SQL 사용하는것에서도 속도차이는 없는지 궁금합니다.