[Paper Review] Learning from Context or Names? An Empirical Study on Neural Relation Extraction
KG Paper Review
Abstract
- Relation extraction benchmark에서 neural model들이 성공적인 결과를 보여주는데, 어떤 종류의 정보가 RE에 직접적인 영향을 미치는지, 그리고 이러한 모델의 성능을 어떻게 높일 수 있는지에 대한 명확한 정보가 없음
- 따라서, 이 연구에서는 text에서 중요한 두 가지 요소가 미치는 영향을 알아봄
- 두 가지 요소는 textual context와 entity mentions
- 결과는 다음과 같음
- context가 RE model의 예측을 도와주는 main source이지만, entity mention에 대한 정보에도 크게 의존함
- 존재하는 데이터셋에서는 entity mention으로부터 정보가 leak하여 성능이 좋아졌을 것임
- entity-masked contrastive pre-training framework for RE를 제안
Introduction
RE는 text로부터 relational fact를 추출하는 것이 목적이다.
RE로부터 얻어진 구조화된 knowledge를 이용하여 knowledge graph를 구축하거나 완성할 수 있다.
최근 deep learning의 발전으로, neural relation extraction(NRE) 모델들이 sota를 달성하였다.
- NRE model의 성공 → 어떤 요소가 중요한 것인가?
- 두 가지 main source: textual context, entity mentions
- 초기의 RE systems
- 패턴들을 string templates로 만들어놓고, 이 template에 relation을 matching하는 방식 - 이후의 neural models(Socher et al., 2012; Liu et al., 2013)
- 패턴들을 distributed representations로 인코딩하고 이 representation을 이용하여 relation을 예측
- textual context말고 entity mention도 중요한 정보임
- KG에 entity linking을 하게 되면 entity의 type을 알 수 있고, 이를 통해 불가능한 relation을 filtering할 수 있음
결과적으로, context와 entity mention 모두 RE를 위해 중요한 요소인 것임을 알 수 있었음
Pilot Experiment and Analysis
- CNN
- Nguyen and Grishman (2015)의 CNN을 사용
- BERT for RE
- Baldini Soares et al. (2019)
- entity mention을 special marker로 highlight한 뒤에 분류를 위해 entity representations의 concatenation을 사용
- Matching the blanks (MTB)
- Baldini Soares et al. (2019)
- Matching the Blanks: Distributional Similarity for Relation Learning
- RE-oriented pre-trained model based on BERT
- 2개의 문장이 random하게 masking된 entity mention이 있을 때 같은 entity pair를 언급하는지 분류하도록 pre-trained됨
- 데이터셋
- largest supervised RE dataset인 TACRED (Zhang et al., 2017)
- 106,264 instances and 42 relations
- 각 entity에 대해 type도 제공됨
- Input formats
- Context + Mention (C+M)
- RE에서 가장 많이 쓰이는 형태
- 문장과 entity mention의 위치를 알려주기 위해 CNN model에서는 position embedding (Zeng et al., 2014)을, pre-trained BERT에서는 special entity marker (Zhang et al., 2019; Baldini Soares et al., 2019)를 사용
- Context + Type (C+T)
- entity mention을 TACRED에서 주어지는 type으로 대체
- 이를 위해 special token을 사용
- Only Context (OnlyC)
- Entity mention 정보가 들어가지 않게 하기 위해 모든 mention을 [SUBJ]와 [OBJ]의 special token으로 대체해서 넣어줌
- Only Mention (OnlyM)
- Entity mention만 남기고 문장 속 나머지 단어는 모두 지움
- Only Type (OnlyT)
- OnlyM과 마찬가지로 Type만 남기고 나머지는 모두 지움
- Context + Mention (C+M)
- Result Analysis
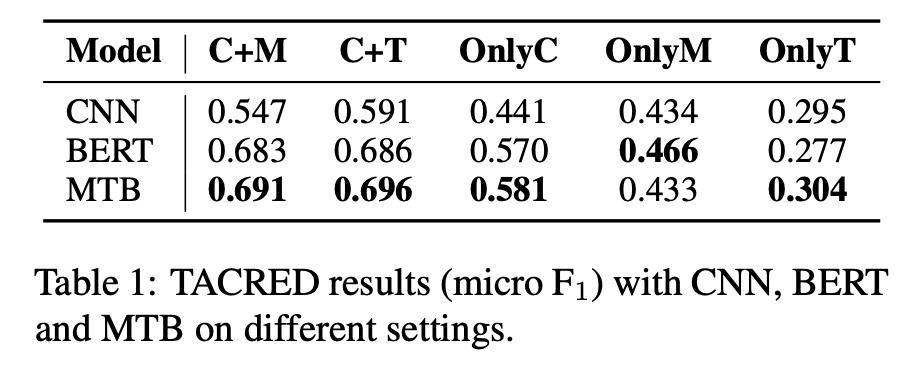
- textual context와 entity mention 모두 relation extraction에 매우 중요한 정보를 주는 것으로 나타남
- entity mention에 있어서 가장 쓸모있는 정보는 type information이었음
- OnlyC, OnlyM, OnlyT는 성능이 훨씬 낮게 나타나는 것을 확인 → 올바른 예측을 하기 위해서는 context와 entity mention이 모두 필요
- mention에 의해 leak되는 superficial cue가 존재하는 것을 확인 - 이것이 RE model의 높은 성능에 기여
- OnlyM에서 모든 세 개의 model에 대해 꽤 높은 성능을 보임
- C+M과 비교하여 OnlyC의 성능 저하를 살펴본 결과 몇 가지 경우에 대해 model이 context를 잘 이해하지 못하고 mention에 대한 얕은 heuristic에만 의존하여 예측하는 것을 확인
- CNN 결과는 BERT, MTB와 약간 다른 형태를 보임
- CNN에서는 OnlyC와 OnlyM이 거의 비슷하고, C+M이 C+T보다 5% 낮게 측정됨
- 이와 같은 결과는 CNN의 제한된 encoding 능력에 의한 것으로 보임 - context를 fully utilize하지 못하고 entity mention만에 의해서 더 잘 overfit
- Case Study on TACRED
- 먼저 C+M과 C+T를 비교
- C+M은 C+T의 correct prediction의 95.7%를 공유
- C+M의 68.1% wrong prediction이 C+T와 같게 나타남
- 이로부터 entity mention에서 얻는 정보 중 가장 이득을 많이 보는 것은 type information임을 예상 가능
- OnlyC가 C+M에 비해 성능 저하가 크게 나타나는 이유
- 모든 OnlyC의 unique wrong predictions를 clustering → 3 classes
- "Wrong": 문장은 clear pattern이지만 모델이 잘못 이해한 경우
- "No pattern": entity mention을 masking한 후에 사람조차도 무슨 관계인지 알기 힘든 경우
- "Confusing": masking한 후에 문장이 애매해지는 경우(예를 들어, city와 country)
- model이 entity mention으로부터의 얕은 heuristic에 의존할 수도 있다는 것을 의미
- 먼저 C+M과 C+T를 비교
Contrastive Pre-training for RE
Textual context와 entity type information 모두 RE model에게 중요하게 작용한다는 것을 확인하였다.
하지만, 몇 가지 경우에 대해 model이 context에서 제대로 된 relational pattern을 이해하지 못하고 entity mention으로부터의 얕은 heuristic에 의존하여 분류하는 것을 확인하였다.
이를 해결하기 위해 → entity-masked contrastive pre-training framework for RE 제안
- RE를 위해 pre-training하는 것을 통해 textual context와 entity types를 더 잘 encoding할 수 있을 것이라 생각
- contrastive learning (Hadsell et al., 2006) 아이디어 차용
- neighbor는 pull하고, non-neighbor는 push하는 것을 통해 representation을 학습
- neighbor instance끼리는 비슷한 representation을 가지게 됨
- "neighbor"를 어떻게 정의하는지가 중요
- distant supervision 으로부터 얻은 영감 - KG에서 같은 relation을 가지는 entity 쌍을 포함하는 문장들을 "neighbor"라 하자!
문장 의 entity mention 와
Knowledge Graph: , relation:
이면 는 "neighbor"로 정의
학습시킬 때 먼저 KG에 있는 relation 의 비율을 추출하고, 이 relation에 연결된 문장 쌍 를 추출
Contrastively하게 학습시키기 위해 random한 N개의 문장 을 뽑아 에 대해 N개의 negative pairs를 만들 수 있게 한다.
이와 같이 positive 문장 쌍과 negative 문장 쌍이 공존하는 상태에서 model은 어떤 문장이 와 같은 relation을 가지는지 분류해야 한다.
- pre-training하는 동안 entity mention을 암기하거나 이를 통해 shallow feature를 뽑아내는 것을 막기 위해 entity mention을 special token [BLANK]로 random하게 masking
- (Baldini Soares et al., 2019)
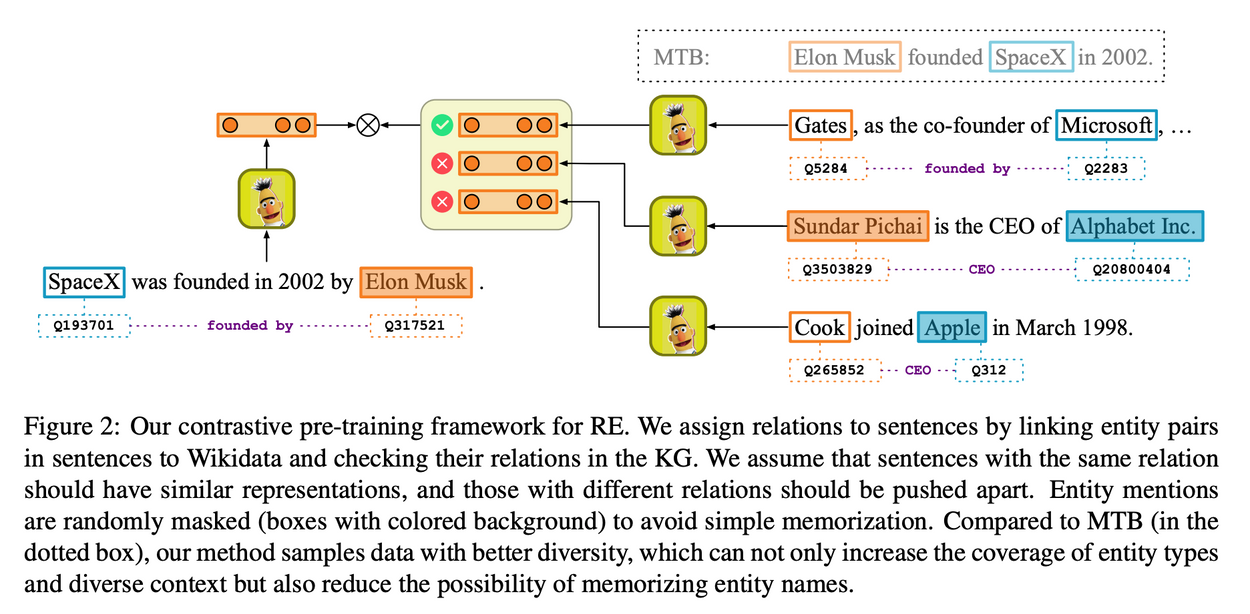
- 예시 문장
- "SpaceX was founded in 2002 by Elon Musk"
- "As the co-founder of Microsoft, Bill Gates ..."
- KG 안에 (SpaceX, founded by, Elon Musk), (Microsoft, founded by, Bill Gates) 모두 존재
- "Sundar Pichai is the CEO of Alphabet Inc."와 "Cook joined Apple in March 1998."은 founded by라는 relation을 가지고 있지 않으므로 negative sample로 간주됨
- 이는 Fig. 2의 왼쪽에 있는 문장인 "SpaceX was founded in 2002 by Elon Musk"과는 다른 representation을 가질 것으로 예상
- 학습하면서 각 entity mention은 random하게 masking됨
- main problem
- 문장이 아무런 관계를 나타내지 않는다거나, 우리가 예상하려는 관계와 다른 관계를 나타내는 것
- 예를 들어, "SpaceX"와 "Elon Musk"는 founded by라는 relation을 나타낼 수도, CEO 또는 CTO라는 relation을 나타낼 수도, 또는 아무런 관계를 나타내지 않을 수도 있음
- "Elon Musk answers reporters' questions on a SpaceX press conference"
- 이 예시 문장에서는 아무런 관계를 나타내지 않음
- But, 이러한 noise problem은 우리의 목적에 있어서는 critical하지 않음
- goal은 BERT와 같은 raw pre-trained model과 비교하여 RE에 좀 더 알맞는 representation을 얻는 것
- downstream task를 위해 directly train하는 model이 아니기 때문에 이 정도 noise는 acceptable prompt
- MTB (Baldini Soares et al., 2019)와 비교
- MTB는 2개의 sampled sentences를 고를 때 같은 entity pair를 공유해야 한다는 좀 더 까다로운 조건을 적용
- 이는 noise를 조금 줄일 수 있지만 다양성이 감소하고 type information을 학습하기 어려움
- BERT와 같은 Transformer 구조 이용
- Input format으로는 Baldini Soares et al. (2019) 와 같이 entity mention에 special marker를 사용
- "SpaceX was founded by Elon Musk" → "[CLS][E1] SpaceX [/E1] was founded by [E2] Elon Musk [/E2] . [SEP]"
- 2가지 objective
- Contrastive Pre-training Objective
- Fig. 2에서 주어진 positive 문장 쌍 와 negative 문장 쌍들 에 대해, Transformer encoder를 통해 각 문장들의 relation-aware representation을 얻음
- h, t는 special token [E1], [E2]의 position이고, 연산자는 concatenation을 나타냄
- 의 representation이 점점 가까워지도록 학습하여 비슷한 representation을 가진 문장들에 대해 같은 relation을 예측할 수 있도록 함
- Masked Language Modeling Objective
- BERT의 language understanding 능력을 유지하고 catastrophic forgetting을 방지하기 위해 BERT의 masked language modeling (MLM)을 그대로 사용
- Input에 있는 token을 random하게 masking하여 model로 하여금 masking된 token을 예측할 수 있도록 하여, contextual representation을 학습할 수 있도록 함
- MLM loss =
- Contrastive Pre-training Objective
- 전체 training loss
Experiment
- Supervised RE
- Pre-defined 된 relation set 이 존재하고 데이터셋의 각 문장은 에 속한 relation 중 하나를 가지고 있음
- 몇몇 benchmark는 N/A 또는 no_relation이라는 special relation이 존재 - 주어진 문장에 아무런 관계가 없음을 의미
- 사용한 데이터셋
- TACRED (Zhang et al., 2017)
- SemEval-2010 Task 8 (Hendrickx et al., 2009)
- Wiki80 (Han et al., 2019)
- ChemProt (Kringelum et al., 2016)
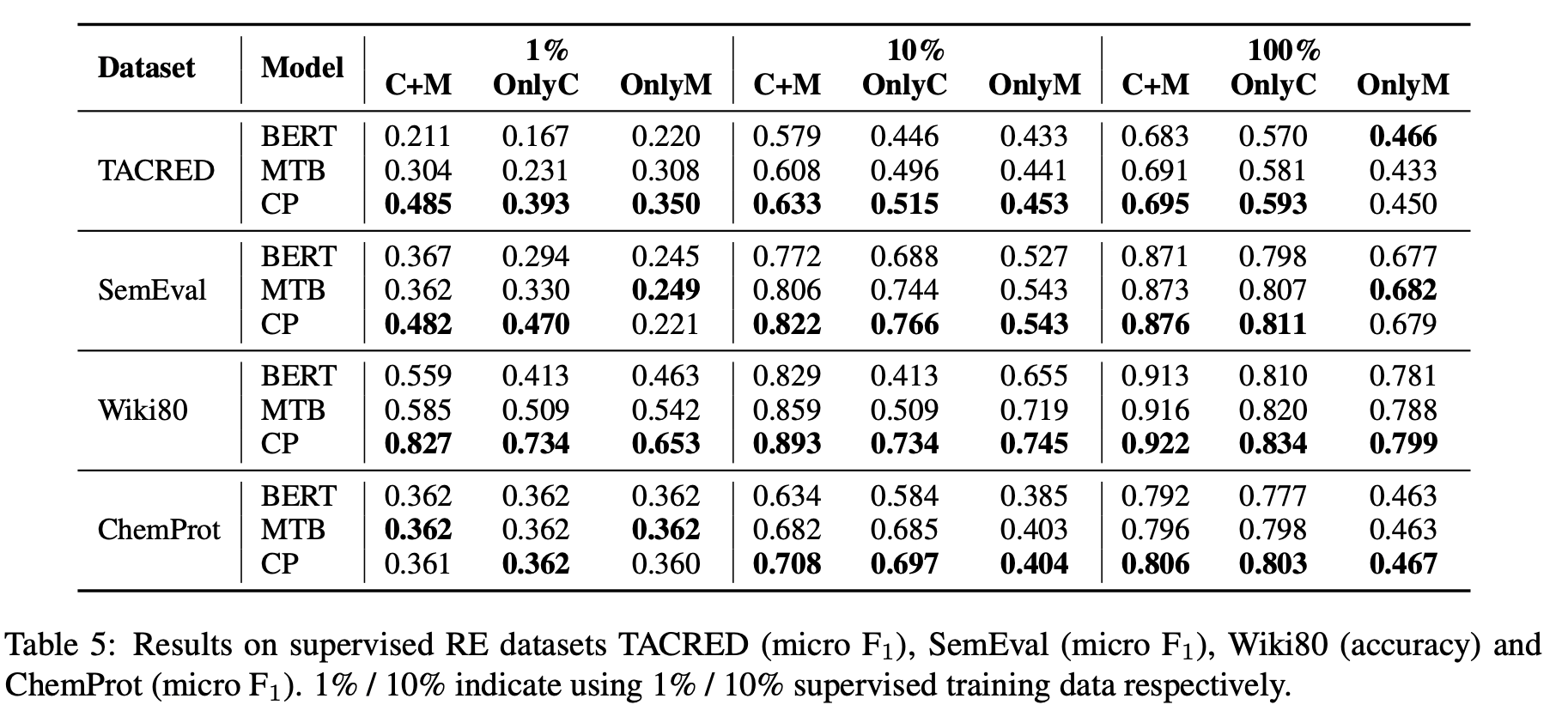
- 1%, 10% setting을 통해 low-resource scenario에 대해 simulation
- Few-Shot RE
- 전형적인 형태 ⇒ N-way K-shot RE (Han et al., 2018)
- 각 evaluation에 대해, N개의 relation types, K개의 examples for each type, 몇 개의 query examples가 추출되고 model은 주어진 samples에 대해 query들을 분류해야 함
- FewRel (Han et al., 2018; Gao et al., 2019) dataset을 사용
- Prototypical Networks 이용 (Snell et al., 2017; Han et al., 2018) but 약간의 변경
- [CLS]만 사용하는 것이 아니라 entity marker token을 추가 사용
- similarity 계산에 Euclidean distance를 쓰지 않고 dot production을 사용
- RE Models
- BERT
- MTB
- CP (contrastive pre-training framework for RE)
- MTB와 CP가 Wikidata를 pre-training에 사용하고, Wiki80과 FewRel 데이터셋이 Wikidata를 기반으로 만들어졌으므로 Wiki80과 FewRel의 test set에 있는 모든 entity pair를 pre-training data에서 제외함
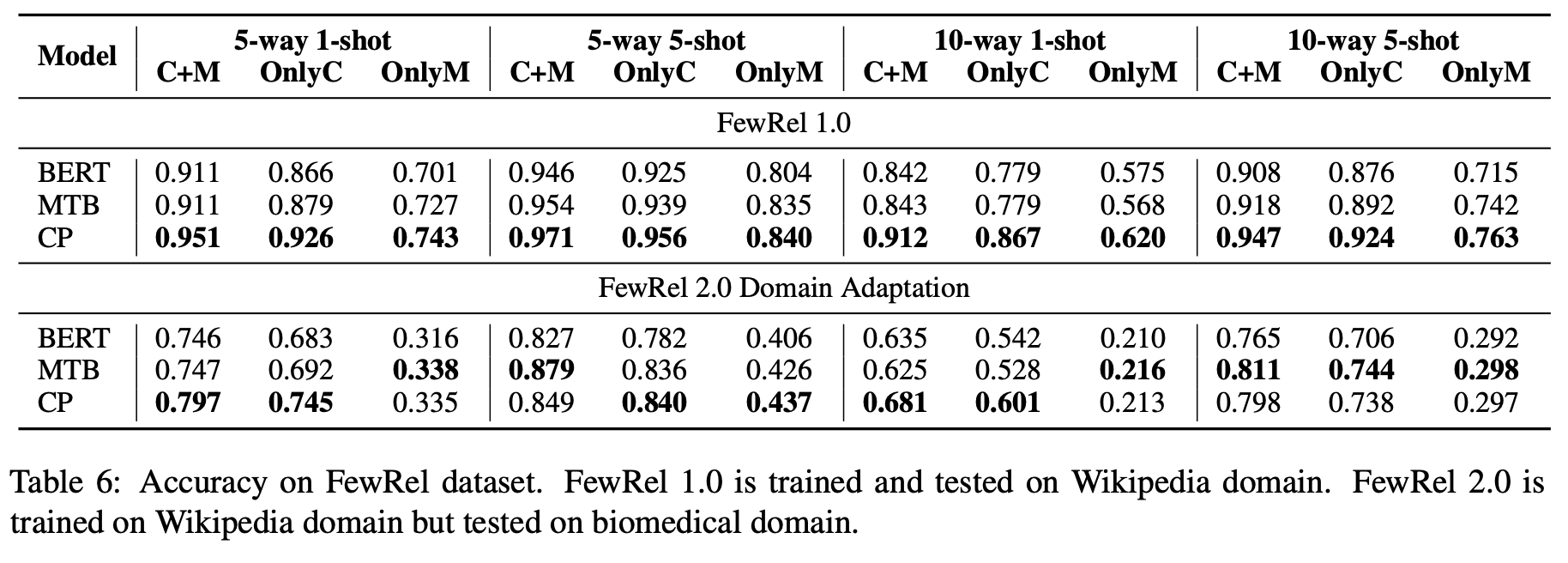
- MTB와 CP 둘 다 다양한 setting과 데이터셋에 대해 성능이 향상됨을 볼 수 있음 → RE-oriented pre-training의 효과가 나타남
- CP는 C+M, OnlyC, OnlyM 모두에서 성능 향상이 일어나는데, 이는 CP가 context understanding과 type information extraction을 둘 다 잘하도록 학습됨을 의미함
- C+M과 OnlyC에서의 성능 향상은 모든 경우에 대해 나타남
- biomedical domain 관련 데이터셋인 ChemProt과 FewRel 2.0에 대해서도
- 이는 CP가 다른 도메인에 대해서도 효과적인 relational pattern을 학습한다는 것
- CP가 Wikipedia와 관련된 TACRED, Wiki80, FewRel1.0에서 OnlyM에 대해 뛰어난 성능을 보임
- CP가 mention으로부터 type information을 추출하는 더 좋은 ability가 있음을 의미
- low-resource와 few-shot setting에서 CP가 상당한 성능을 보여줌
- 이러한 setting에서는 relational pattern을 context로부터 뽑아내기 더 어렵고, mention으로부터 overfit하기 쉬움 - 제한된 training data 때문
- 하지만 CP는 상대적으로 textual context를 잘 이용하여 성능이 좋게 나타나는 것으로 보임
Related Work
- Development of RE
- methodologies
- pattern-based methods
- feature-based methods
- kernel-based methods
- graphical models
- RNNs for RE
- neural RE
- to solve the data deficiency problem
- distant supervision
- few-shot learning
- methodologies
- Pre-training for RE
- RE-oriented pre-trained model (Baldini Soares et al., 2019)
- proposed matching the blanks
- inject entity knowledge in the form of entity embeddings
- RE-oriented pre-trained model (Baldini Soares et al., 2019)
- Analysis of RE
- how RE models learn from context and mentions (Han et al., 2020)
- Alt et al. (2020) pointed out that there may exist shallow cues in entity mentions
Conclusion
- Context와 entity mention 모두 relation extraction을 위한 중요한 정보를 제공한다.
- 존재하는 RE dataset은 entity mention을 통해 leakage가 발생하여 생각하는 것만큼 context를 이해하는 능력이 없을 수 있다.
- context와 entity types를 더 잘 이해하는 entity-masked contrastive pre-training framework for RE를 제안한다.
