Background
앞서 포스팅한 2 stage detector의 경우 높은 정확도를 갖지만 이미지 처리 속도가 매우 느리다는 단점이 있다. 이러한 한계를 갖는 모델을 real world(실상황)에 사용하기란 문제가 있다. 따라서 real world에서 응용 가능한 object detector가 필요해 1 stage detection방식의 모델이 제안 되었다.
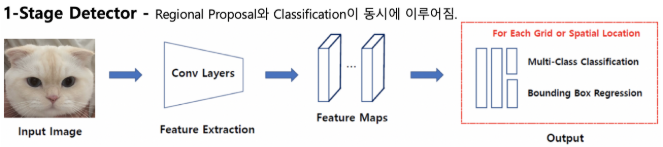
1 Stage Detectors
- Localization, Classfication이 동시에 진행
- 전체 이미지에 대해 특징 추출, 객체 검출이 이우어짐
- 속도가 빠름
- 영역을 추출하지 않고 전체 이미지를 보기 때문에 객체에 대한 맥락적 이해가 높음
Yolo(you only look once)
Yolo는 처음으로 1-stage-detection방식으로 고안되어. 실시간 객체 탐지를 가능하게한 모델이다.
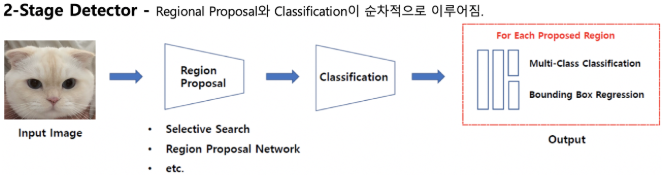
- Region proposal 단계 제거
- 전체 이미지에서 bbox예측과 클래스를 예측하는 일을 동시에 진행
(이미지, 물체를 전체적으로 관찰하여 추론)
Yolo v1
Yolo v1모델의 전체적인 구조는
- 24개의 convolution layer: 특징 추출
- 2개의 fully connected layer: box의 좌표
값 및 확률 계산
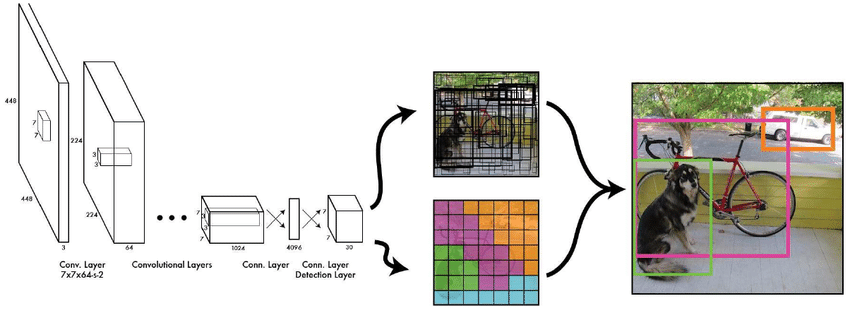
Yolo v1 Pipeline
- 입력 이미지를 S X S 그리드 영역으로 나눈다 (S = 7)
- 각 그리드 영역 마다 B개의 Bounding box와 Confidence score를 개산한다(B = 2)
- confidence score: 오브젝트가 존재할 확률 x IOU
- 각 그리드 영역 마다 C개의 class에 대한 해당 확률 계산(C = 20)
3-1. 하나의 그리드 셀을 슬라이딩하여 2개의 class scores를 계산 총 88개(7x7x2)의 class score를 계산
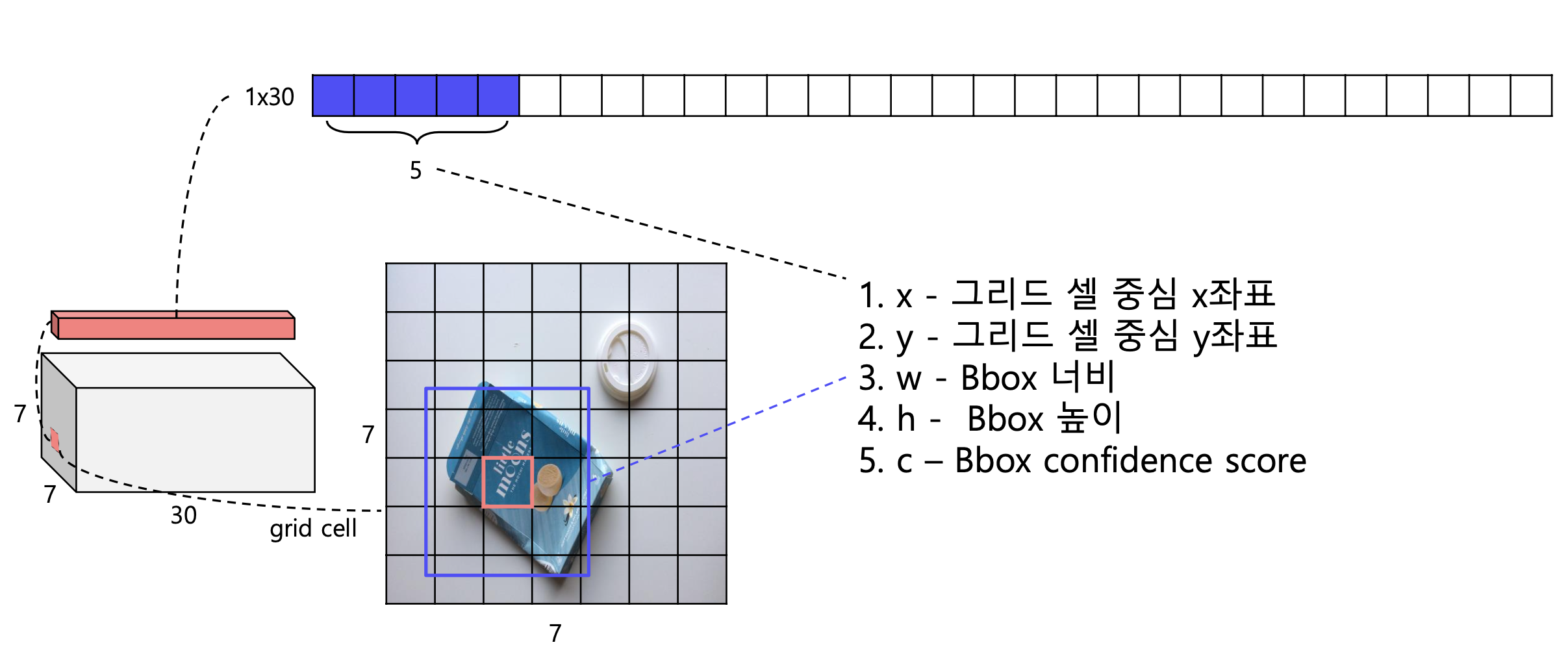
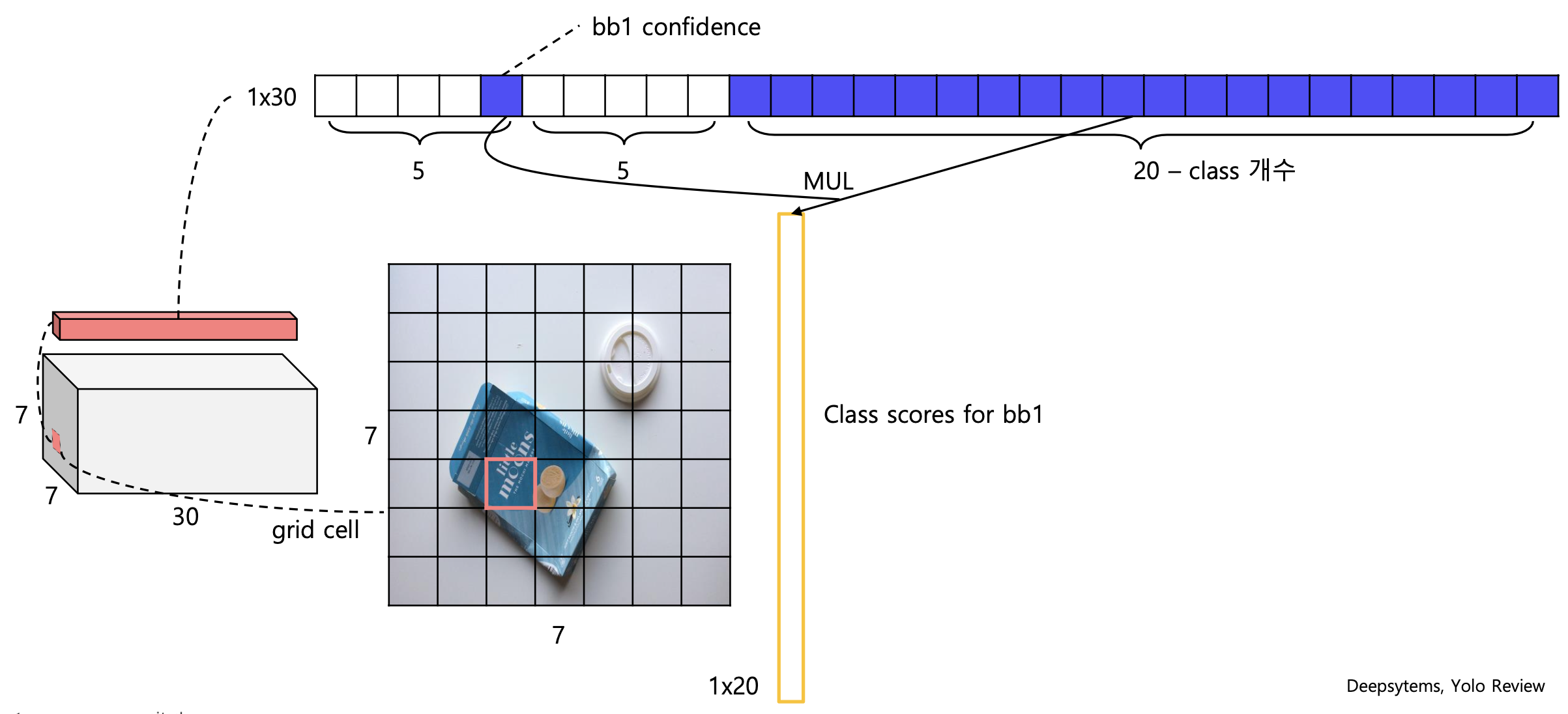
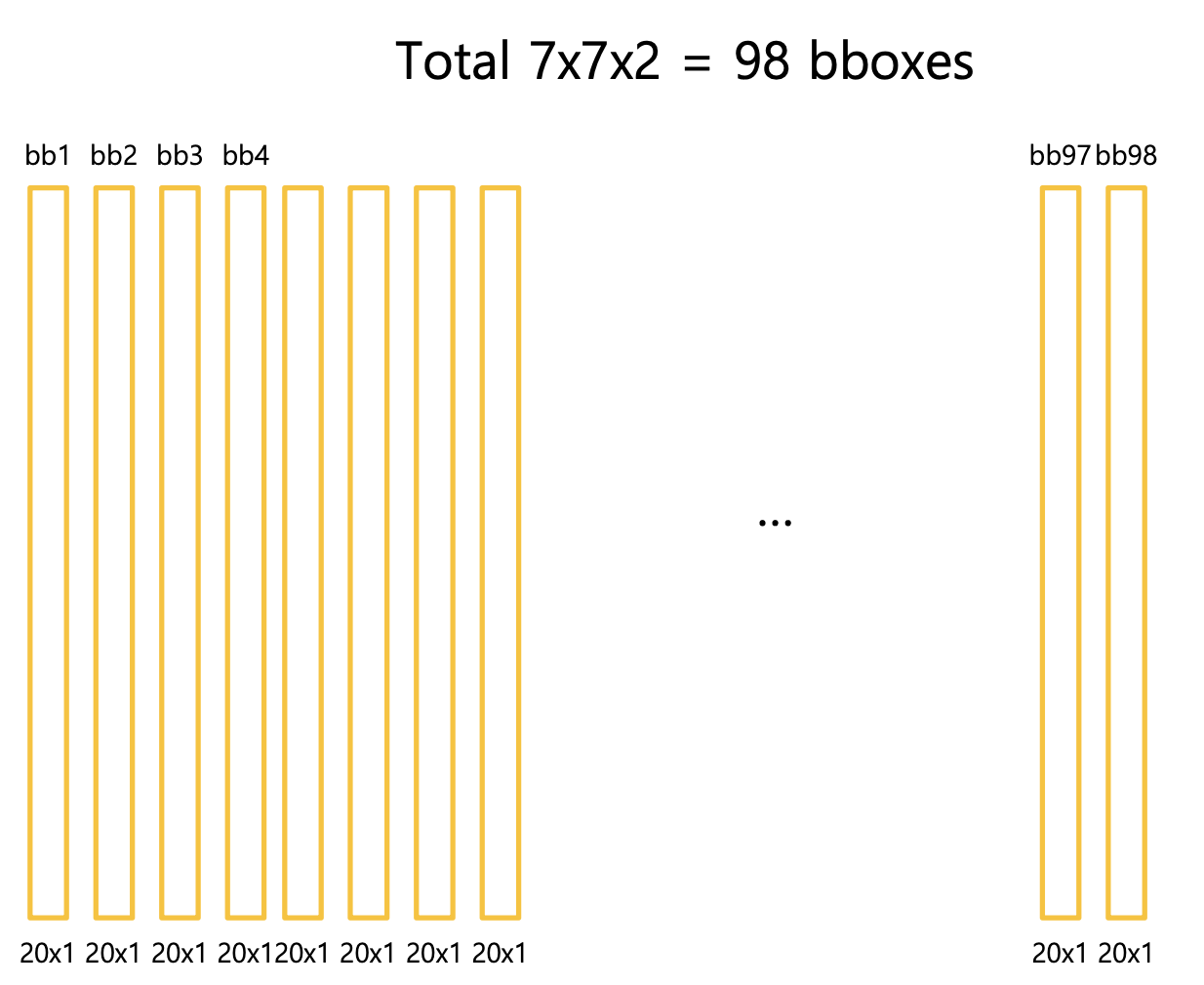
4. 앞서 구한 class score를 thresh hold이하는 제거하고 내림차순 정렬하여 NMS알고리즘 진행
Loss function
Yolo v1모델의 loss function은 아래와 같다

Result
- Faster-RCNN에 비해 6배 빠른 속도
- 다른 real-time detector에 비해 2배 높은 정확도
- 이미지 전체를 보기 때문에 클래스와 사진에 대한 맥락적 정보를 가지고 있음
- 물체의 일반화된 표현을 학습, 사용된 데이터 셋 외 새로운 도메인에 대한 이미지에 좋은 성능을 보임
SSD
앞서 설명한 Yolo는 2stage에 비해 매우 빠른 이미지 처리 속도를 보이고 있다. 하지만 그리드 영역 보다 작은 크기의 물체는 검출 불가능하고 신경망을 통과하여 마지막 feature만 사용하기 때문에 정확도가 하락한다는 한계점이 존재한다. SSD는 이러한 한계점을 극복하고자 시작한다.
YOLO vs SSD
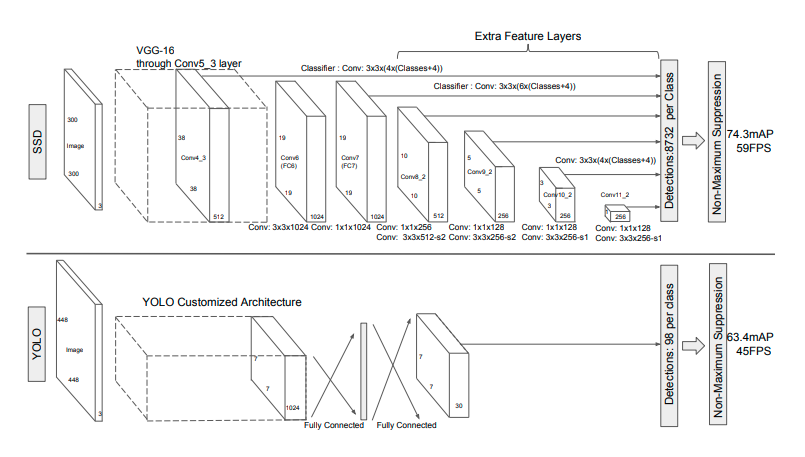
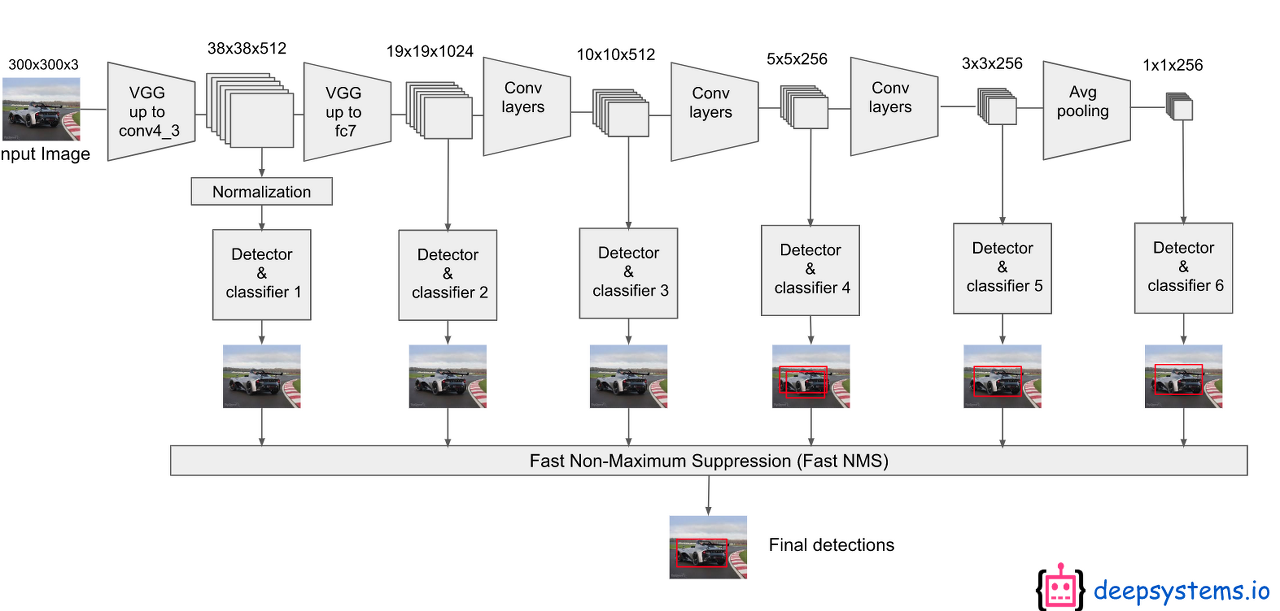
SSD는 먼저 300x300 크기의 이미지를 입력받아서 이미지 넷으로 pretrained된 VGG의 Conv5_3층까지 통과하며 피쳐를 추출한다. 그 다음 이렇게 추출된 피쳐맵을 컨볼루션을 거쳐 그 다음 층에 넘겨주는 동시에 Object Detection을 수행한다. 이전 Fully Convolution Networ에서 컨볼루션을 거치면서 디테일한 정보들이 사라지는 문제점을 앞단의 피쳐맵들을 끌어오는 방식으로 해결했다.
SSD는 여기서 착안하여 각 단계별 피쳐맵에서 모두 Object Detection을 수행하는 방식을 적용한 것이다. 이를 더 자세한 그림으로 표현하면 아래와 같다.
default box가 3개 일때 예시
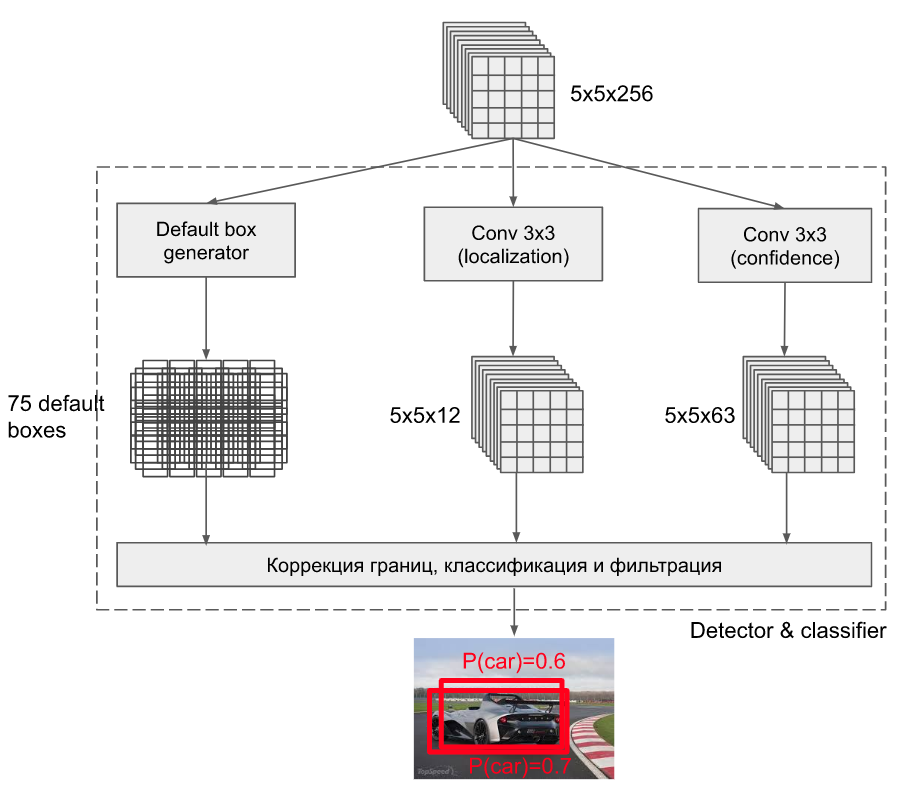
만약 default box의 개수가 3개라면 각각 pretrained된 convolution layer에서의 출력 값에 3x3 conv 연산을 진행해 물체의 localization과 confidence score를 출력하는 것을 볼 수 있다.
localization: 4(4개의 좌표)x3(3개의 default box)
confidence: 21(21개의 객체) x 3 (3개의 Default box)
Default Box
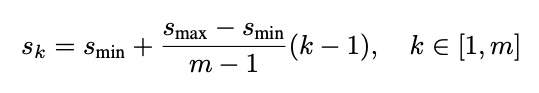
SSD
SSD의 특징을 보면 아래와 같다.
- 6개의 서로 다른 scale의 feature map에 모두 detection을 수행
- 큰 feature map에서는 작은 물체 탐지
- 작은 feature map에서는 큰 물체 탐지
- Fully connected layer대산 conv layer를 사용하여 속도 향상
- 서로 다른 비율과 scale을 갖는 Default box 사용 (anchor)
