저번 시간에 sementic segmentation Task를 수행하는 FCN의 한계점의 개선방향에 대해 설명하면서 대략적인 DeepLab의 구조와 이론을 살펴보았다. 이번에는 DeepLab계열의 모델들이 어떻게 개선 되어왔는지 비교해보자.
1. Receptive Field를 확장시킨 models
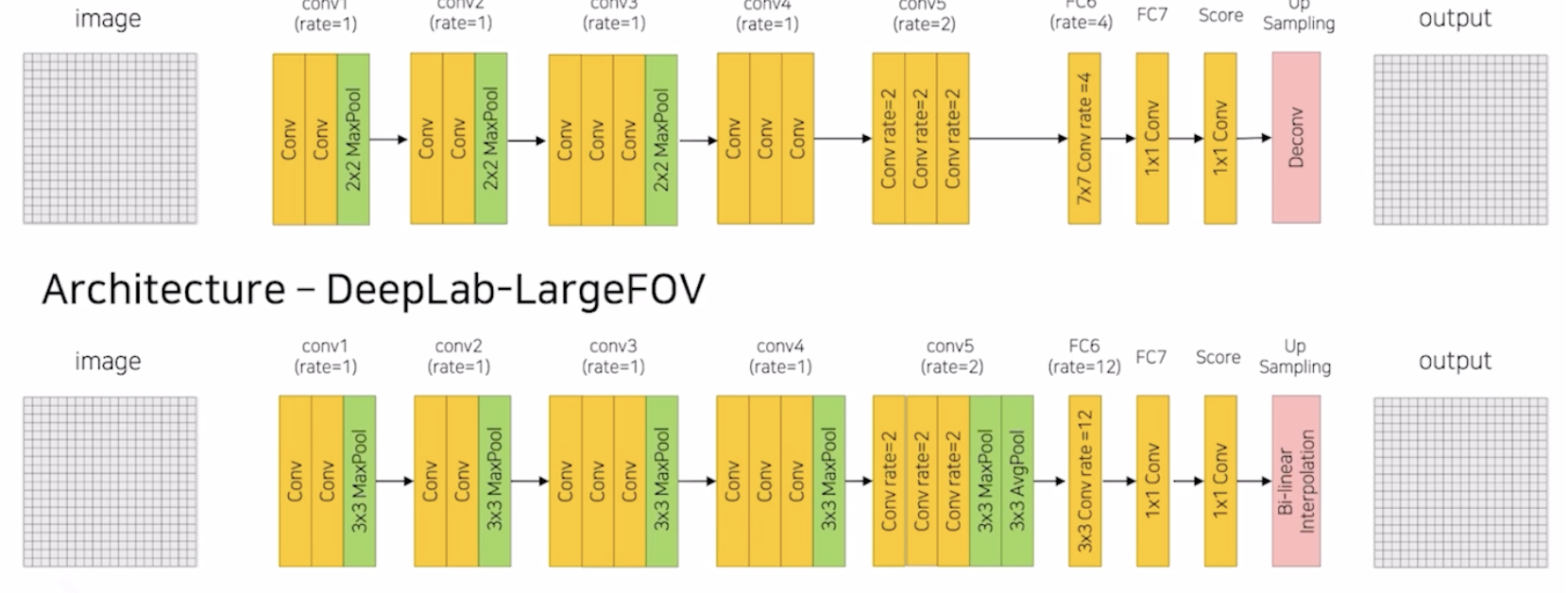
이전 포스팅에서 설명한 DilatedNet과 DeepLab에 대해 리마인드해보자.
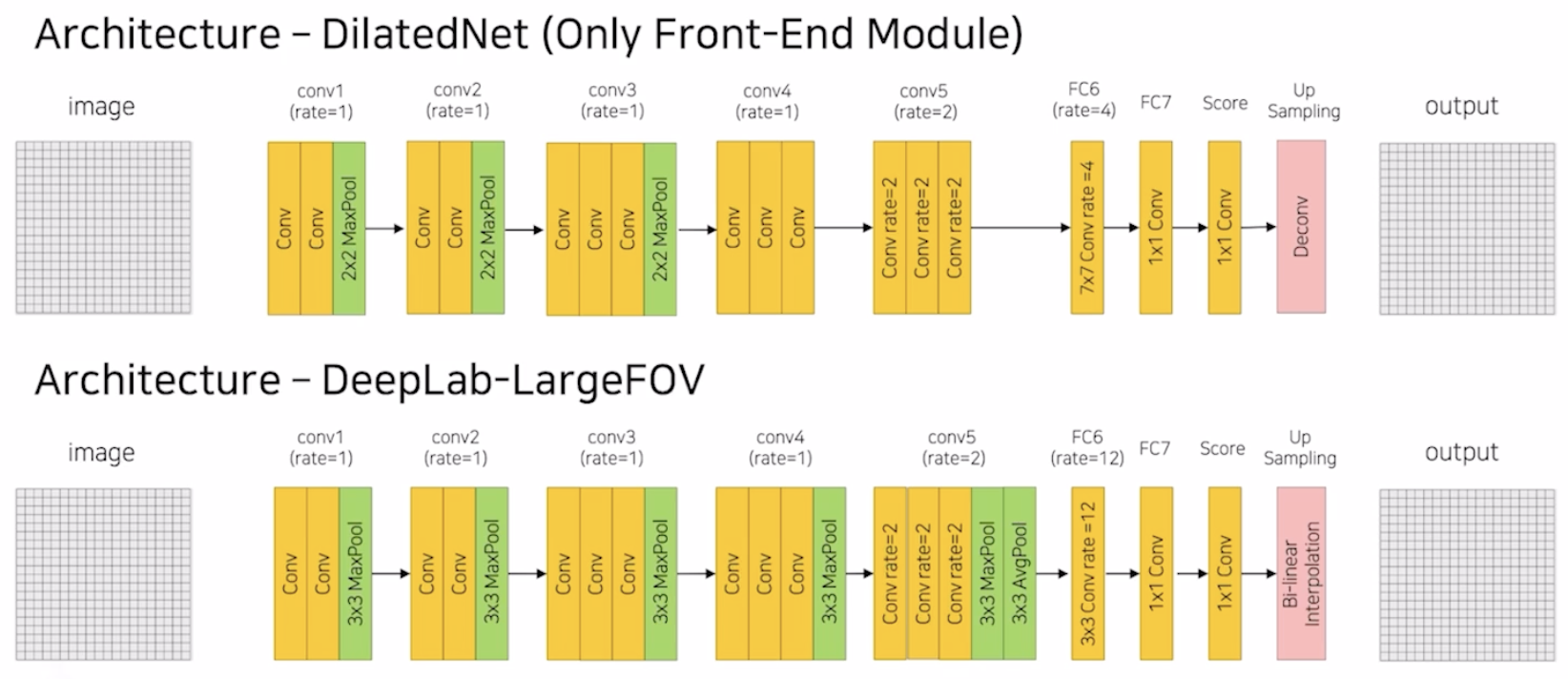
DilatedNet과 DeepLab 모두 conv layer에 Dilated rate를 설정해서 효율적으로 Receptive Field의 크기를 키웠다. 그리고 추가적으로 FCN에서는 5개의 MaxPooling을 사용하여 이미지를 1/32로 줄이고 Decoder에서 32배 키우는 방식인 반면 두 모델은 1/8로 줄이고 Decoder에서 8배 키운다는 차이를 보인다.
1.1 DeepLab v2
DeepLab에서는 v1모델의 결과에 힘입어 v2 모델을 선보였다.
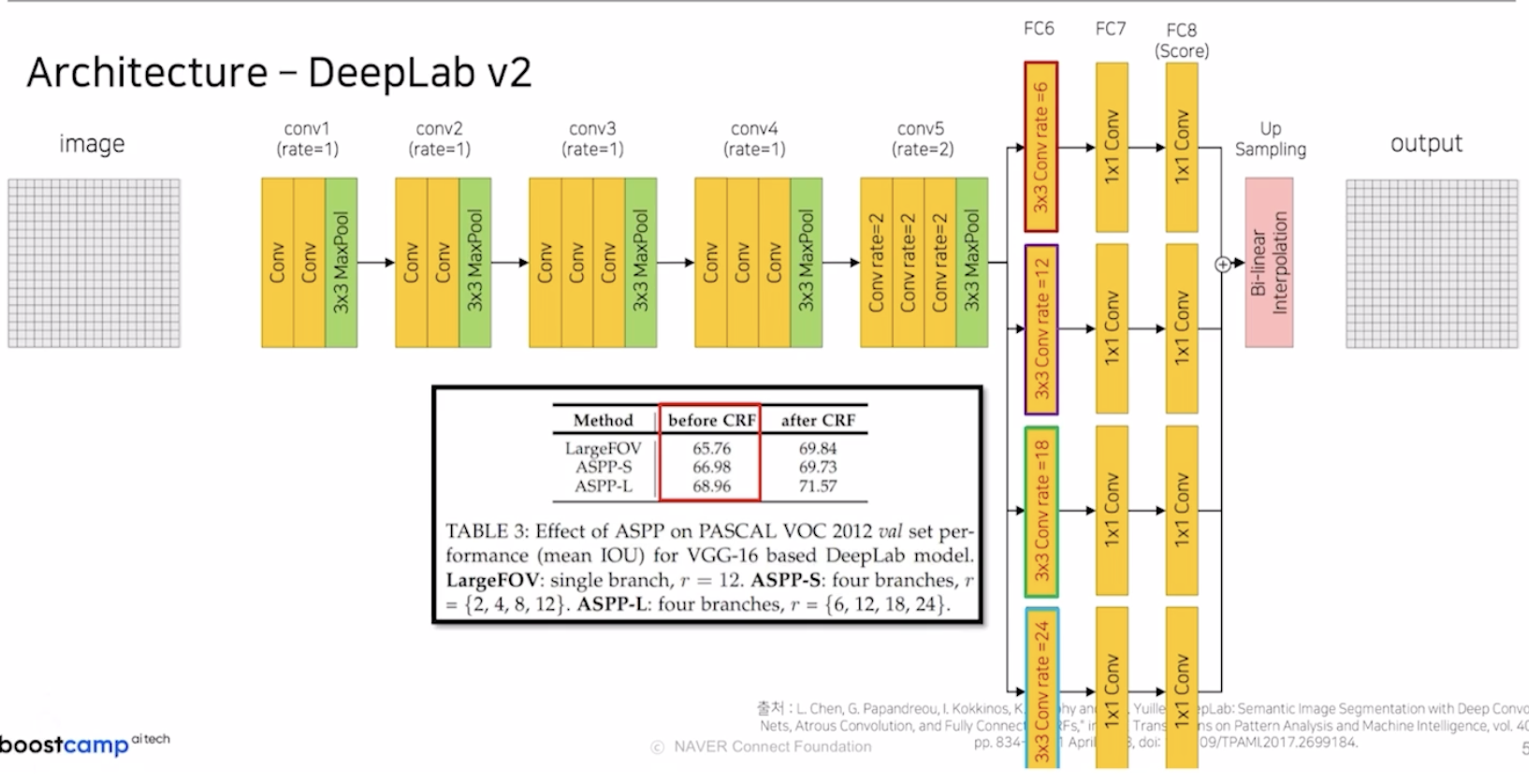
backbone구조는 기존 v1 model과 동일하지만 conv5에서 AvgPool 부분이 제거 되었다. 그리고 v1 model에서는 한 가지의 Dilated rate를 사용했지만 v2부터는 4개의 다양한 rate를 사용한다. 논문에서는 이를 ASPP-S라는 명칭을 사용한다.
이렇게 4개의 rate를 사용하면 다양한 크기의 객체를 탐지할 수 있다는 장점이 있다.
ResNet backbone
DeepLab v2는 ASPP 외 Backbone Network로 ResNet을 사용하는 것을 볼 수 있는데 코드와 함께 살펴보자.
#input image size: 512
#------------------------------------------------------------------
#conv1
#------------------------------------------------------------------
#input size 512 -> output 256
conv1_block = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(num_features=64),
nn.ReLU())
# image size 256 -> 128
maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
#------------------------------------------------------------------
#conv2
#------------------------------------------------------------------
conv2_sub_block = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=256)
)
#skip connection을 위한 identity block
# input image의 channel사이즈를 conv2 block을 거쳐서 나온 output의 channel과 맞춰주기 위함
#image size는 in과 out이 같으므로 channel만 맞춰주면 됨
identity_block = nn.Sequential(
nn.Conv2d(in_channels=64, out_channel=256, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=256)
)
#------------------------------------------------------------------
#conv3
#------------------------------------------------------------------
conv2_sub_block = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=128, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
# image size 128 ->64 , 2번째부터는 downsampling을 적용하지 않음
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=512, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=512)
)
identity_block = nn.Sequential(
nn.Conv2d(in_channels=256, out_channel=512, kernel_size=1, stride=2, padding=0),
nn.BatchNorm2d(num_features=512)
#------------------------------------------------------------------1.2 PSPNet
PSPNet은 3가지 문제를 제기한다.
-
객체들간 관계를 catch하지 못하는 것
상황: 호수 주변에 있는 boat를 car라 예측하는것
원인: boat의 외관이 car와 비슷함
idea: 주변 특징을 고려 -
비슷한 category를 혼동함
상황: skyscraper를 building이라 예측
원인: 마천루와 빌딩이 비슷해 보임
idea: category간의 관계를 사용해서 해결(global contextual information) -
무늬가 비슷하고 작은 object를 잘 탐지 못함
상황: pillow를 bed sheet로 예측
원인 pillow의 객체 사이즈가 작을 뿐만 아니라 bed sheet의 커버와 같은 무늬 예측이 한계
idea: 작은 객체들도 global contextual information사용
Actual Receptive Field
FCN의 경우 5번의 max pooling으로 feature map을 줄이고 receptive field를 충분히 키웠을 것 같은데 왜 위와 같이 객체 간의 관계를 제대로 포착하지 못했을까?
PSP 논문에서는 이론적인 Receptive field의 크기와 실제 Receptive field간 크기 차이가 나기 때문이라고 주장한다.

표를 보면 pooling을 진행할 수록 이론과 실제 receptive field 차이가 점점 커지는 것을 볼 수 있다.
Global avgpooling
PSPNet에서는 이를 해결하기위해 Global avgpooling이라는 것을 통해 해결하고자 한다.
- 1x1, 2x2, 3x3, 6x6의 출력을 갖는 AvgPooling을 적용
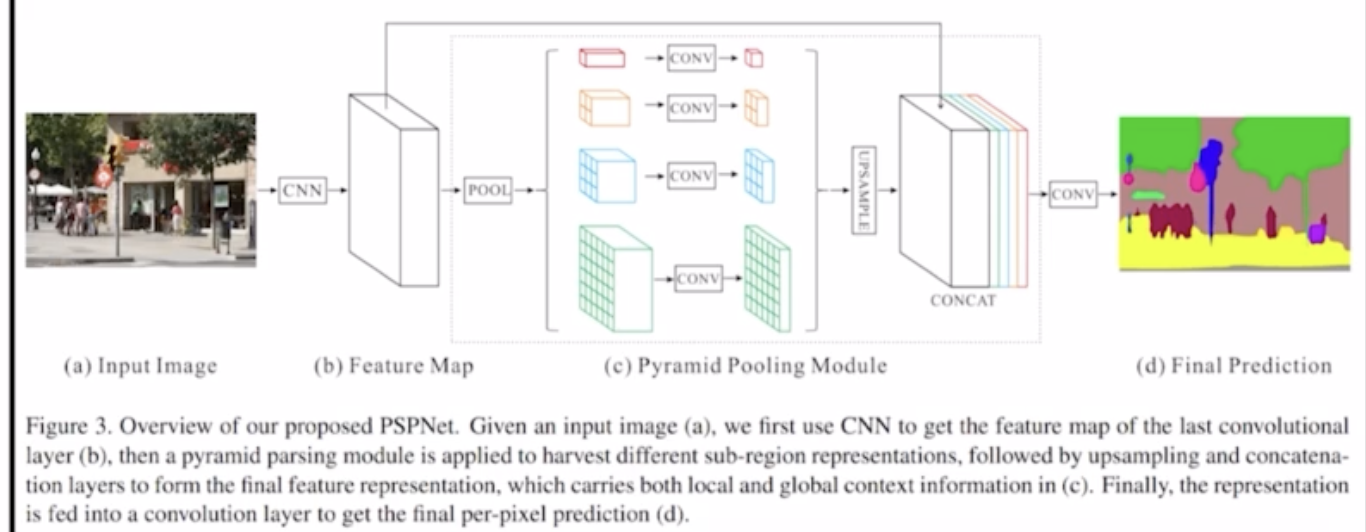
- 동일한 feature map에 출력이 1x1, 2x2, 3x3, 6x6의 출력을 갖도록 다양한 avgpooling을 진행
- 각각의 avgpooling을 거쳐서 나온 결과에 conv를 적용하여 channel size를 1, 출력 feature map의 사이즈를 입력 feature map과 동일하거 맞춤
- concat 진행
1.3 DeepLab v3
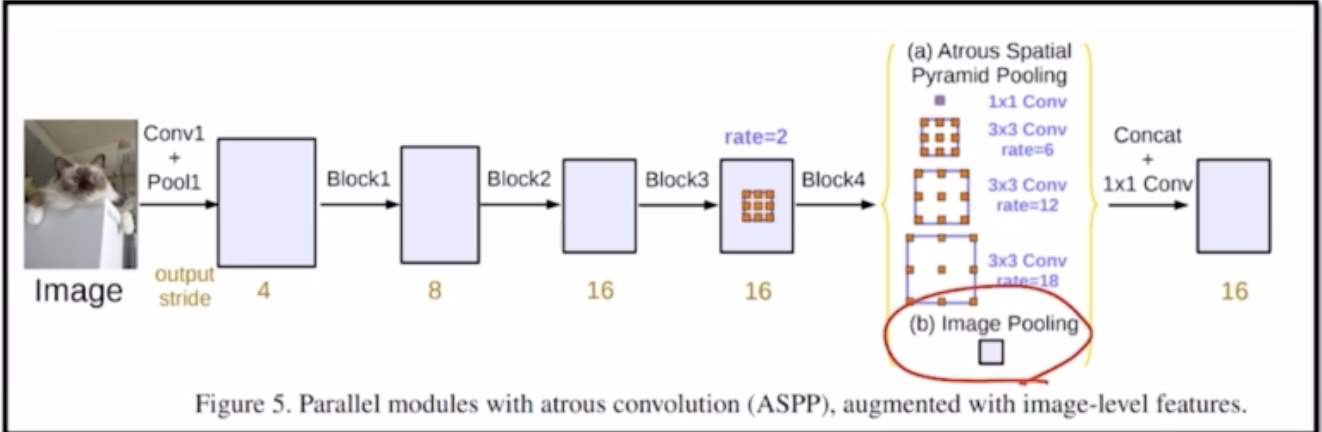
기존 v2의 pyramid pooling 부분에 dilated rate 24를 제거하고 1x1의 출력을 갖는 global avgpooling이 추가됨
1.4 DeepLab v3 +
기존 v3와 달리 Encoder & Decoder구조로 되어있다.
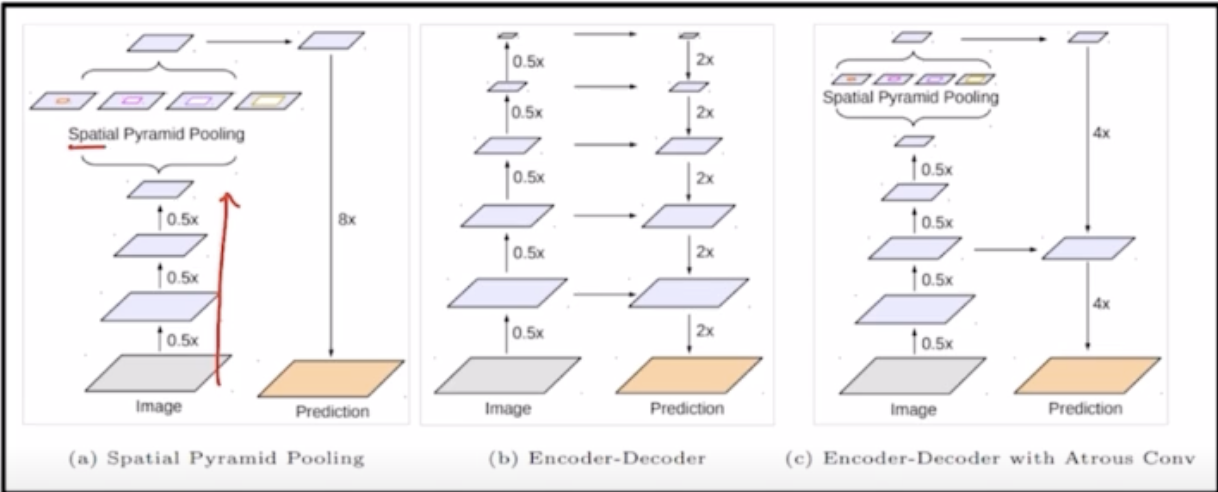
(c): v3+
