- 파이썬의 고성능 과학 계산용 패키지
- 일반 list에 비해 빠르고,메모리 효율적
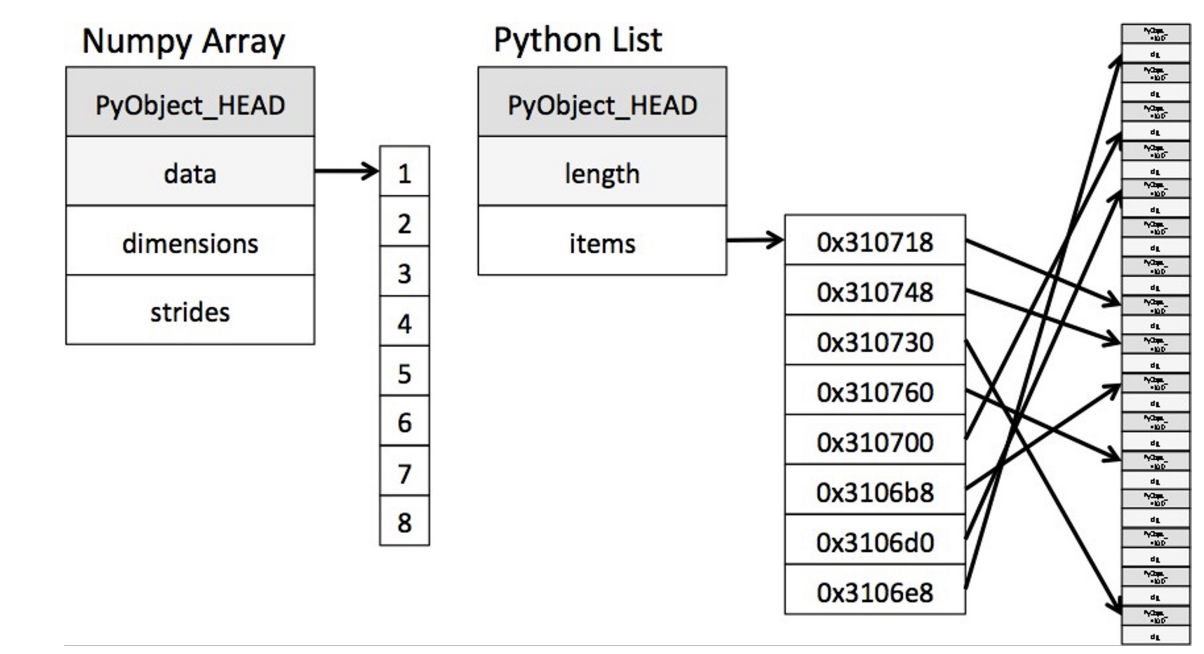
numpy array vs python list
- numpy array: 메모리에 차례대로 데이터가 저장 되어있음
- python list: 리스트에에 주소값이 들어있다.
# is는 메모리의 워치를 저장
a = [1,2,3,4,5]
b = [5,4,3,2,1]
print(a[0] is b[-1]) # 파이썬에서 1의 메모리 주소는 같기때문에 True가 나온다
n_a = np.array(a)
n_b = np.array(b)
print(n_a[0] is n_b[-1]) #넘파이 배열에는 1의 메모리 주소가 서로 다르다
배열 생성
- 파이썬 list와 달리 동적타이핑을 지원하지 않기 때문에, 하나의 데이터 type만 넣을 수 있음
test_array = np.array(['1','2',5.0,8],float) #array([1., 2., 5., 8.])
- shape: numpy array의 차원을 반환함
np.array(a).shape #(3,3)- dtype: 배열 전체 데이터의 type을 반환함
test_array.dtype #dtype('float64')handling shape
-
reshape(): array의 shape을 변경함
-
flatten(): 다차원 array를 1차원으로 변환
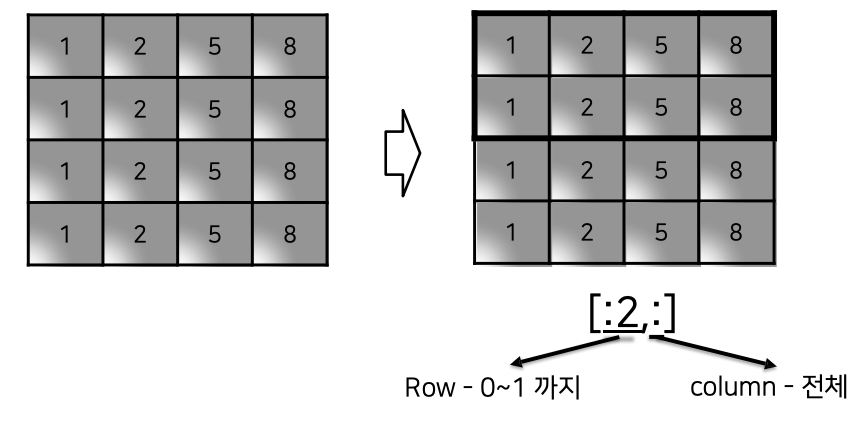
slicing for numpy
- list와 달리 행과 열 부분을 나눠서 slicing이 가능함
creation function
- np.arange(): array의 범위를 지정하여,값의 list생성
- np.zeros():0으로 초기화된 배열을 생성
- np.ones(): 1로 가득찬 배열 생성
- np.empty(): shape만 주어지고 비어있는 배열생성(메모리에 이전에 쓰던 값이 남아 있음)
- np.identity(): 단위 행렬 생성
- np.eye(): 대각행렬이 1인 행렬(identity와 달리 정방행렬이 아니어도 된다)
- np.diag(matrix): 배열의 대각 행렬을 추출함
np.arange(0,10,0.5) #array([0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5, 5. , 5.5, 6. ,6.5, 7. , 7.5, 8. , 8.5, 9. , 9.5])
random_sampling
- 데이터 분포에 따른 sampling으로 array생성
- np.random.uniform(): 균등분포 생성
- np.random.normal(m,s,d): 평균이 m이고, 표준편차가 s인 d차원의 정규분포 생성
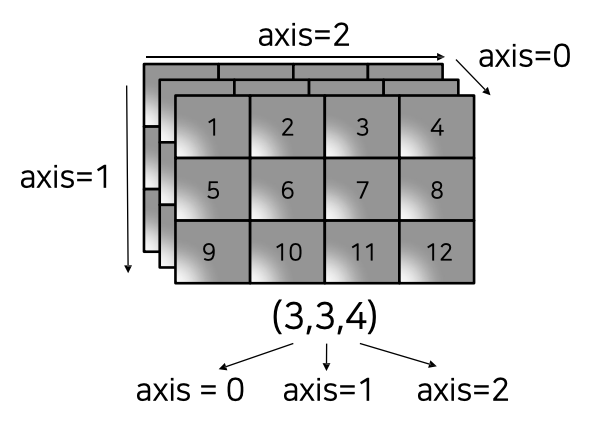
axis
- operation function을 실행할 때 기준이 되는 dimension
operation function
- test_array.sum(): 배열의 합을 구함
- test_array.mean():배열의 평균
- test_array.std():표준편차
- np.concatenate((a,b),axis = 0)
camparision
- np.all(a>5): a의 모든 원소가 5보다 크면 true (and연산)
- np.any(a<3): a의 원소중 하나가 3보다 작으면 True(or 연산)
- np.where(a>5): a의 원소들중 5보다 큰 인덱스 반환

잘하자