편향(bias)
우리는 흔히 모델이 데이터의 관계를 잘 학습해서 데이터의 관계를 잘 나타내면 편향이 낮다고한다. 반대로 데이터를 잘 학습하지 못해 데이터의 관계를 잘 나타내지 못하면 편향이 높다고 한다.
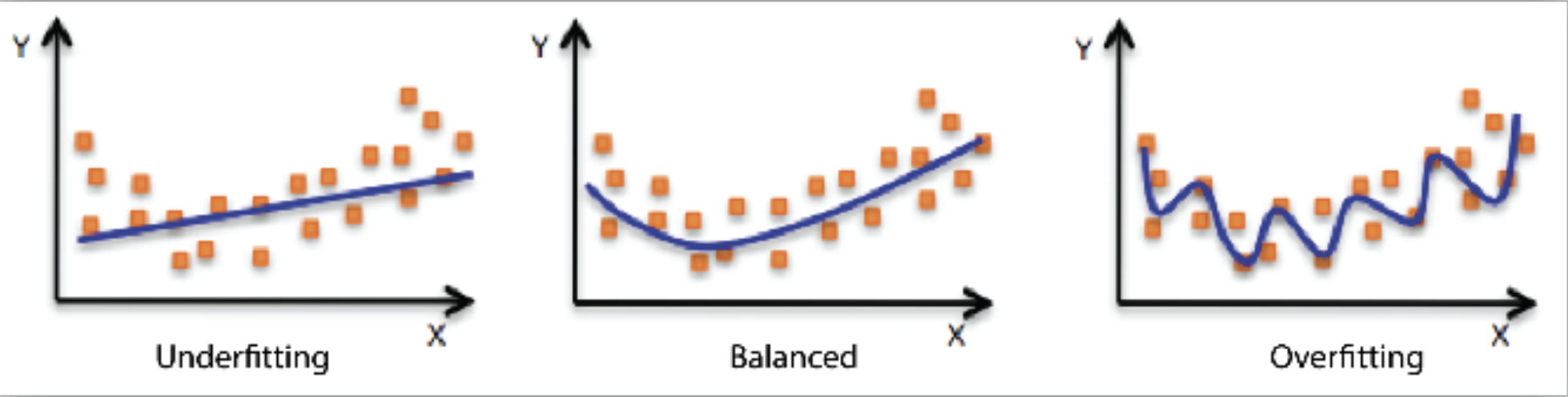
그래프를 보면 주황색 산점도가 feature에 대한 label의 분포이고 파란색 선이 학습 선형모델의 값이다.
- 과소적합(underfitting): 왼쪽의 그래프의 경우 모델이 간단해서 데이터의 분포를 잘 설명하지 못하고있다. 편향이 높다.
- 과적합(overfitting): 오른쪽의 그래프의 경우 복잡한 모델을 사용해서 데이터와 거의 일치하는 그래프를 띄고 있다. 편향이 낮다
그렇다면 복잡한 모델을 사용하여 편향을 낮추면 좋은 모델일까?
분산
- 편향이 낮다고해서 꼭 좋은 모델인 것은 아니다.
분산이란 데이터 셋 별로 모델이 얼마나 일관된 성능을 보여주는지를 분산이라고 한다. 일반적으로 train data와 test data의 성능이 많이 차이나는 모델이라면 분산이 높다고한다.
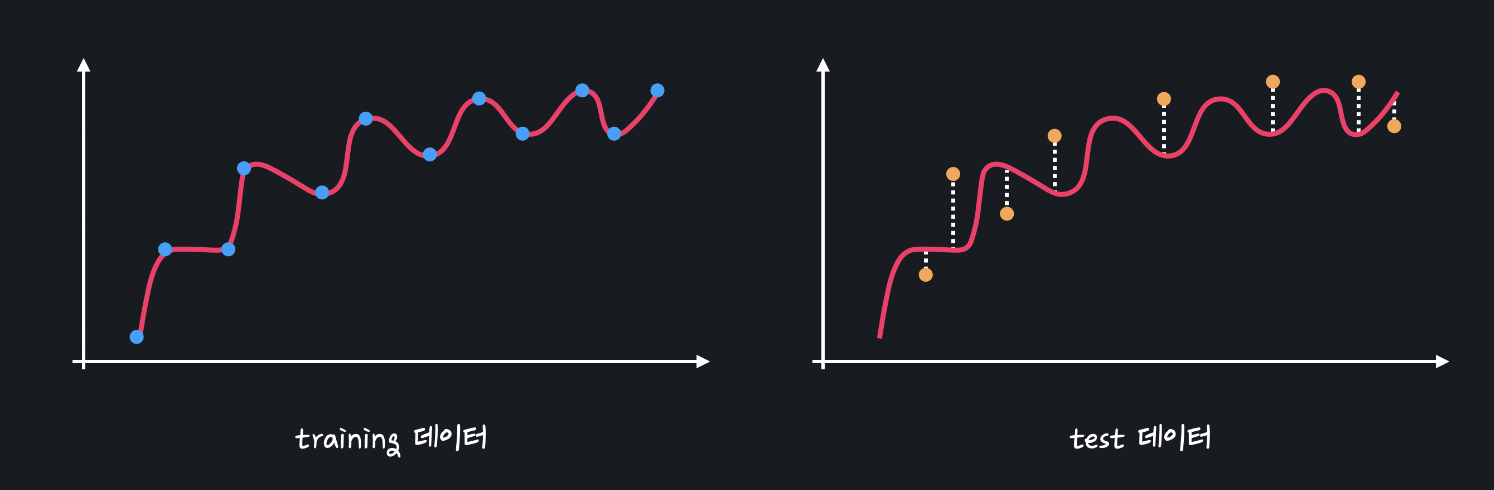
그래프를 보면 학습 모델의 편향이 낮아 train dataset에서는 오차가 0에 수렴하는 그래프를 보이지만.
모델이 train dataset에서의 성능만 신경쓴 나머지 test dataset에서의 성능이 좋지 못하다.
앞서 말한대로 모델이 데이터셋에 대해 일관된 성능을 띄지 못하므로 분산이 높은 모델이다.
좋은 모델을 만들기 위해서는 편향과 분산이 낮은 모델을 만들어야 된다.
편향과 분산의 trade-off
일반적으로 편향과 분산은 trade-off의 관계를 띄고 있다. 다시말해 편향과 분산은 한쪽이 줄어들면 한쪽이 늘어나는 관계이다.
이러한 trade-off 관계에서 적절한 편향과 분산을 갖는 모델을 찾아야한다.
대처 방안
편향이 높을 때
만약 모델이 높은 편향을 갖고 있어 train_data에서도 성능이 안나온다면. 다음과 같은 방법을 사용해 볼 수 있다.
- 더 복잡한 모델 사용: 모델의 layer가 깊어질 수록 데이터의 복잡한 패턴을 표현할 수 있다.
분산이 높을 때
모델이 테스트 데이터셋과 학습 데이터에서의 성능 차이가 많이 난다면 다음과 같은 방법으로 분산을 줄여야 된다.
- 더 많은 데이터: 데이터를 더 확보해서 학습하면 편향에 영향을 미치지 않고 분산을 줄일 수 있다.
- 정규화: 정규화 기법을 사용하면 모델이 train data에 과적합 되는 것을 어느정도 막아 분산을 줄일 수 있다.
