🖊️ 웹 크롤링?
웹 크롤링은 어떤 웹페이지에 접속해 "내가 원하는 특정 조건을 충족하는" 데이터를 추출하는 기술을 말한다. 일명 데이터를 긁어온다- 라고도 표현하는데, 이것이 웹 크롤링 기술의 정의이다.
Python 라이브러리를 이용해 웹 크롤링을 할 때는 BeautifulSoup, Selenium을 주로 사용한다.
(뷰티풀숲, 셀레니움이라고 부른다)
웹 크롤링에는 정적 웹 크롤링과 동적 웹 크롤링이 있는데, 정적 웹 크롤링은 정적인 데이터를 수집하는 방법을 의미하고, 동적 웹 크롤링은 입력, 클릭, 로그인 등과 같이 페이지의 동적의 변화를 통해 확인가능한 동적인 데이터를 크롤링하는 것을 말한다.
정적 웹 크롤링에는 주로 request, BeautifulSoup을 사용하고, 동적 웹 크롤링에는 chromedriver, Selenium을 사용한다.
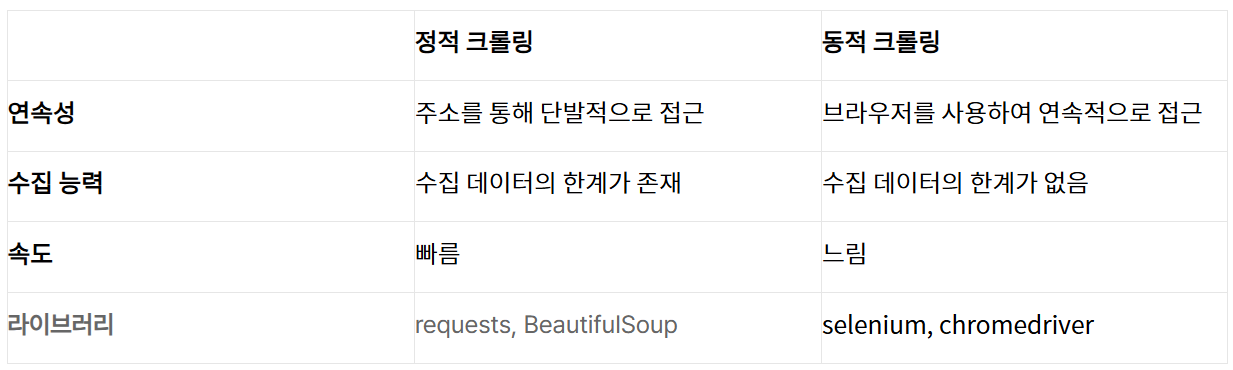
[출처] https://jaaamj.tistory.com/101
✨ BeautifulSoup
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = "https://www.naver.com/"
page = urlopen(url) # url로 페이지 데이터 받아오기
soup = BeautifulSoup(page, 'lxml') # parser의 역할
# 받아온 데이터 결과 출력
print(soup)네이버 웹페이지 웹크롤링 코드

네이버 웹페이지 웹크롤링 결과
BeautifulSoup를 사용할 때는 기본적으로 이렇게
- url 전달
- 받은 url로 접속하여 페이지 데이터 받아오기
- 파서로 페이지 데이터 가공한 후 추출
의 방식으로 사용한다.
이때 파서(parser)는, 내가 원하는 데이터를 특정 패턴이나 순서로 추출하여 정보를 가공해주는 프로그램을 말한다.
파서에는 lxml, html.parser, html5lib 의 3가지 종류가 있는데 각 파서의 파싱 속도를 비교하자면
lxml은 C언어로 구현되어 속도가 가장 빠르고,
html.parser는 lxml과 html5lib의 중간 정도 속도,
html5lib는 웹브라우저 형식으로 html 파일을 분석해서 안정적으로 데이터를 읽어오는 반면에 속도가 가장 느리다는 특징을 갖는다.
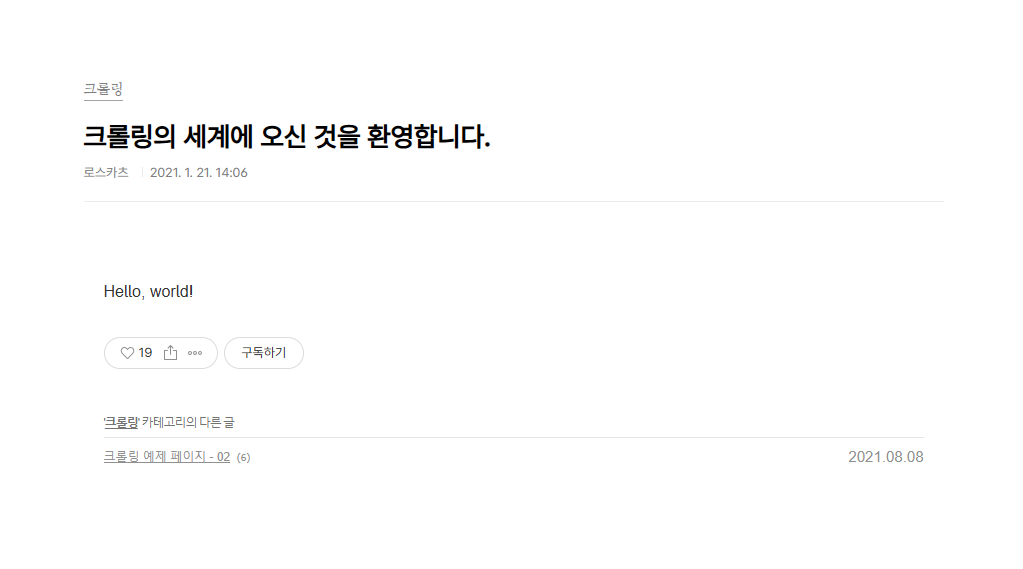
정적 크롤링 예제로 한 번 https://ai-dev.tistory.com/1 페이지의 제목 문장을 긁어오는 걸 시도해보자.
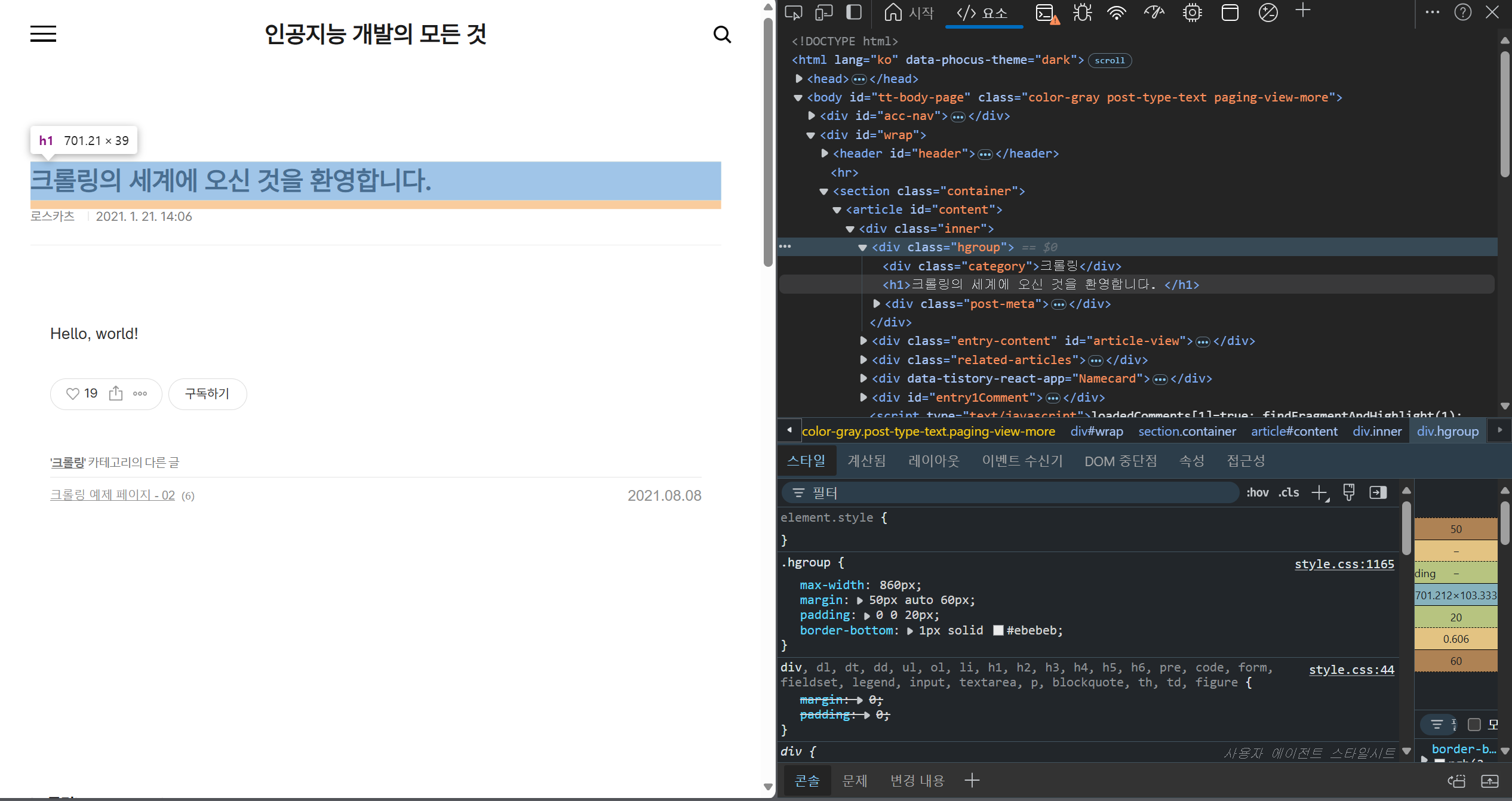
F12번을 눌러 개발자모드로 들어가보면 페이지의 html 요소들을 확인할 수 있는데, 여기서 저 제목 문장인 크롤링의 세계에 오신 것을 환영합니다라는 문구는 h1태그로 감싸져 있고, hgroup이라는 class에 속하는 div태그의 자식인 h1태그의 요소로 동작하므로 해당하는 태그의 데이터가 크롤링되도록 코드를 작성해줘야한다.
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = "https://ai-dev.tistory.com/1" # url 접속
page = urlopen(url) # html 코드 받아오기
soup = BeautifulSoup(page, "lxml") # python이 이해하게끔 parsing# 제목 수집
soup.select_one("div.hgroup > h1").string'크롤링의 세계에 오신 것을 환영합니다. '
여기까지 코드를 실행하면 크롤링하려는 문구가 정확하게 추출된 것을 볼 수 있다.
# 게시글 내용 수집
soup.select_one("div.tt_article_useless_p_margin > p").string추가로 게시글 내용을 크롤링하고 싶다면 이 코드를 실행하면 된다.
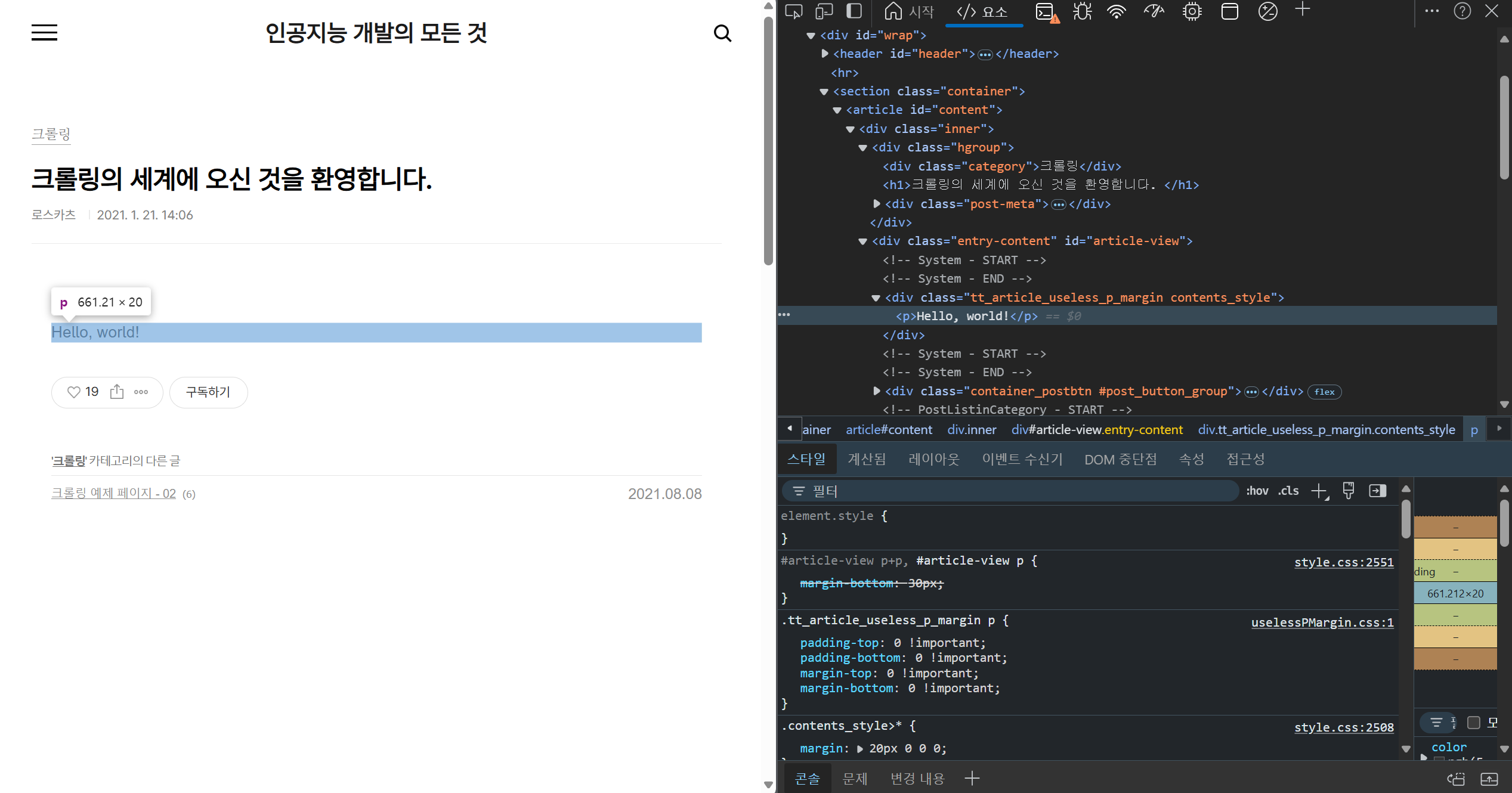 게시글 내용은 tt_article_useless_p_margin이라는 class에 속하는 div 태그의 자식 태그이므로, 위와 같이 해당하는 태그만 크롤링되도록 작성하여 실행하면 게시글 내용을 긁어올 수 있다.
게시글 내용은 tt_article_useless_p_margin이라는 class에 속하는 div 태그의 자식 태그이므로, 위와 같이 해당하는 태그만 크롤링되도록 작성하여 실행하면 게시글 내용을 긁어올 수 있다.
✨ Selenium
from selenium import webdriver
from selenium.webdriver.common.by import By # 웹드라이버 사용
from bs4 import BeautifulSoup # 뷰티풀숩 사용
from urllib.request import urlopen # url 관리
from selenium.webdriver.common.keys import Keys # 키보드 입력 관리(특수키 포함)
import time # time 모듈 가져오기
url = "https://www.naver.com/"
driver = webdriver.Chrome()
driver.get(url)ex.ipynb
Selenium은 webdriver에 포함되어있어서 이를 사용하려면 먼저 webdriver 라이브러리를 import해야한다.
Selenium도 BeautifulSoup과 유사하게 url를 전달해서, 해당 url 페이지의 데이터를 읽어오는 방식이 기본 폼이다.
하지만 BeautifulSoup과는 조금 다르게 데이터 출력 포맷을 해주지 않으면 결과가 다소 불친절하게 나온다.
url = "https://pjt3591oo.github.io/"
driver = webdriver.Chrome()
driver.get(url)
selected = driver.find_element(value = "nav-trigger")
# BeautifulSoup과는 다르게 탐색한 결과가 친절하게 나오지 않음:/
print(selected)
print(selected.tag_name)
print(selected.text)ex.ipynb
이걸 실행하면
 이렇게 뭐가 뭔지 알아보기 힘든 결과값이 출력된다.
이렇게 뭐가 뭔지 알아보기 힘든 결과값이 출력된다.
이번엔 스타벅스 매장 검색 페이지에서 마포구에 위치한 스타벅스 매장을 검색하는 예제를 실행해보자.
url = "https://www.starbucks.co.kr/store/store_map.do?disp=locale" # 스타벅스 매장 찾기
driver = webdriver.Chrome()
driver.get(url) # 드라이버에게 이 주소로 접속하라고 명령
driver.implicitly_wait(3) # 묵시적 대기, 활성화를 최대 3초까지 기다림
# 서울 클릭
sido = driver.find_elements(By.CSS_SELECTOR, 'a.set_sido_cd_btn')
sido[0].click()
time.sleep(1)
# 마포구 클릭
gugun = driver.find_elements(By.CSS_SELECTOR, 'a.set_gugun_cd_btn') # 해당하는 요소 긁어오기
gugun[13].click()
time.sleep(1)
# 매장명 가져오기
soup = BeautifulSoup(driver.page_source, "lxml")
store = soup.select("li.quickResultLstCon > strong")
for n in store:
print(n.text)ex.ipynb
이를 실행하면
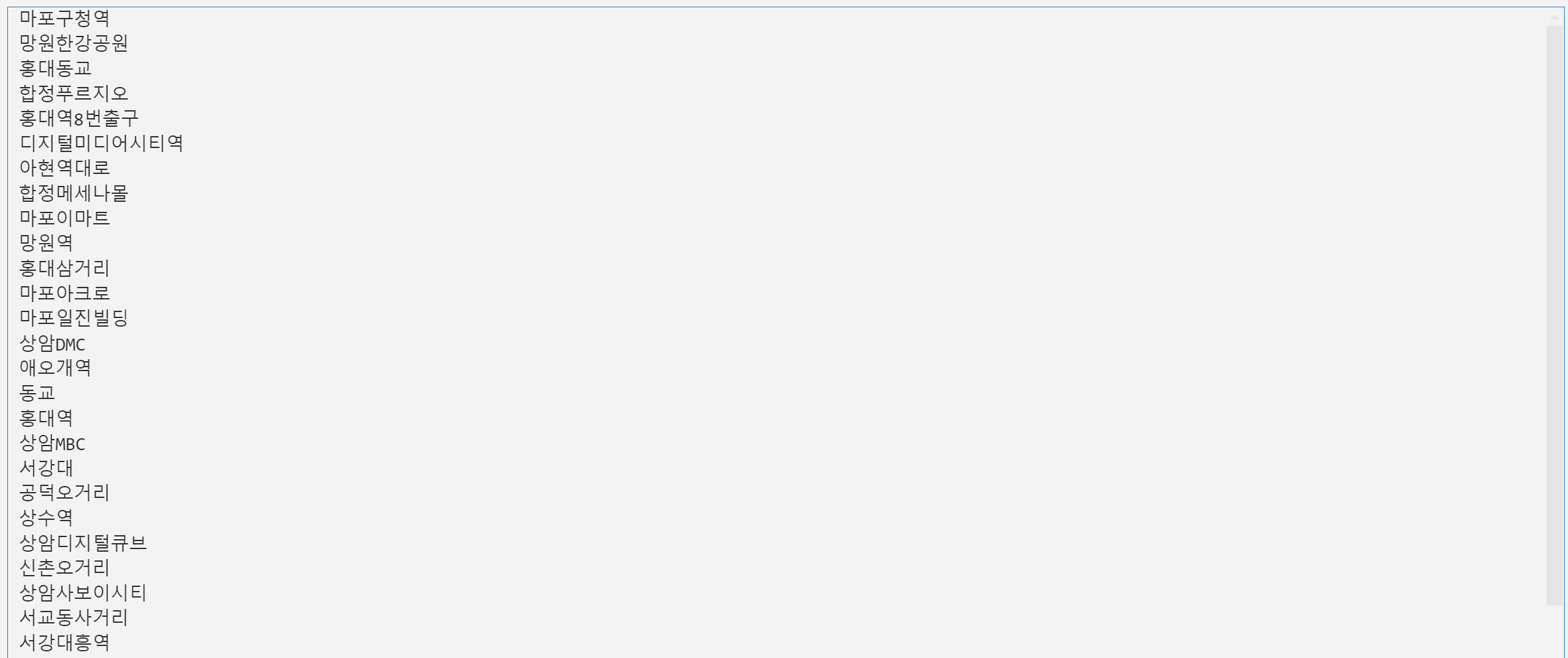 마포구에 위치한 스타벅스 매장의 지점이름이 모두 출력되는 것을 확인할 수 있다.
마포구에 위치한 스타벅스 매장의 지점이름이 모두 출력되는 것을 확인할 수 있다.
Reference
https://velog.io/@developer_khj/Python-Crawling-BeautifulSoup-Selenium#3-beautifulsoup
https://jaaamj.tistory.com/101
