💎 들어가며
이번 포스팅에서는 크롤링과 BeautifulSoup와 Selenium 모듈에 대해 공부하면서 포스팅을 작성해보고자 합니다.
1. Crawling
1.1 Crawling Definition
크롤링(Crawling)이란 웹 상의 정보들을 탐색하고 수집하는 작업을 의미합니다.
흔히들 크롤링이 불법이라고 알려져 있지만, 완전히 맞는 말은 아닙니다. 그 이유는 Google의 검색 방식 또한 크롤링을 기반으로 만들어졌기 때문입니다.
하지만, 허가 없이 데이터를 탐색하여 상업적으로 활용하는 것이 불법입니다.
사례. 잡코리아와 사람인
- 잡코리아와 사람인HR: 구인·구직 플랫폼을 운영하는 회사
- 사람인HR이 잡코리아 웹사이트에 게재된 채용정보를 웹크롤링해 무단으로 수집한 후 그대로 자신의 웹사이트에 활용
- 사람인HR 측은 웹크롤링이 보편적인 IT기술이며 인터넷 관련 업계에서 널리 통용되는 영업 수단, 잡코리아의 권리를 침해한 사실이 없다고 주장
이에 법원은 아래와 같이 판결했습니다.
- 잡코리아의 웹사이트가 저작권법상 데이터베이스에 해당(저작권법 제2조 제19호)
- 이를 제작하고 유지하는 데 상당한 투자를 한 잡코리아는 데이터베이스 제작자의 권리(저작권법 제93조)
사람인HR 주장과 달리, 공개된 정보에 대한 웹크롤링이 영업 수단으로 제한 없이 허용되는 것은 아니라는 것입니다.
웹사이트에서 누구나 확인할 수 있더라도 웹사이트 운영자가 상당한 시간과 노력을 들여 데이터베이스화한 정보를 특히나 경쟁업체에서 무단으로 수집·이용하는 행위는 허용되지 않는다는 취지로 풀이됩니다.

1.2 Robots.txt
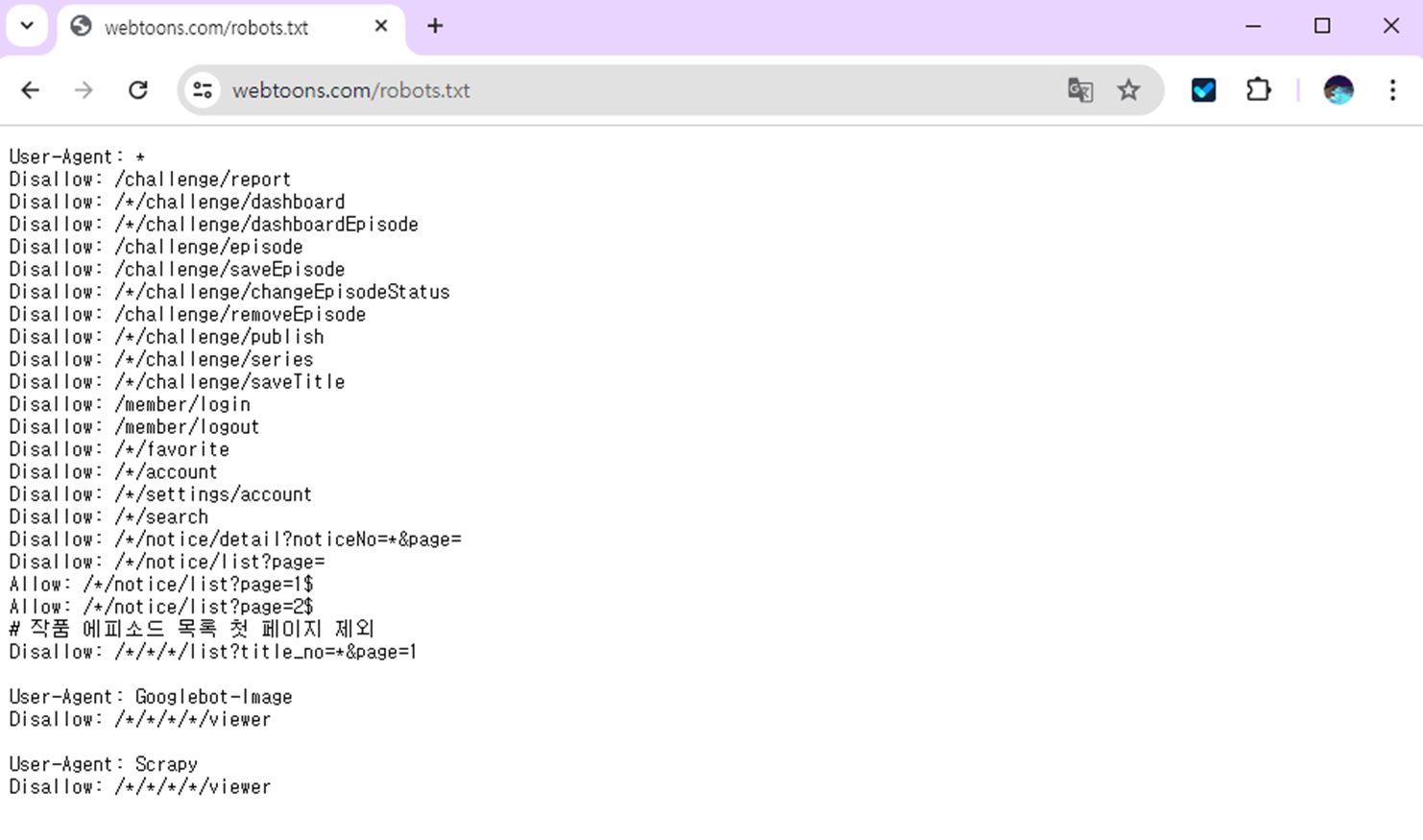
그렇다면 어떻게 허가된 데이터를 알 수 있을까요? 바로 robots.txt를 통해 알수 있습니다.
robots.txt 파일은 크롤러가 사이트에서 액세스할 수 있는 URL을 검색엔진 크롤러에게 알려줍니다.
웹사이트에서 url 뒤에 robots.txt를 넣으면 사이트에서 수집 가능한 정보를 알 수 있습니다.
1.3 Scraping VS Crawling
웹 스크래핑과 크롤링은 흔히 크롤링으로 혼용되어 사용되는 용어입니다. 두 용어의 공통점은 특정 웹사이트에서 데이터를 추출하는 것입니다.
주요 차이점은 URL로 해결할 수 없는 동적 데이터를 크롤링을 통해 추출할 수 있다는 점입니다. URL을 통해 HTML을 한번에 다운받느냐,
1.4 언제 막힐 지 모르는 Crawling
크롤링은 사실 언제 동작이 안될지 모릅니다. 그 이유는 HTML을 기반으로 소스가 조금씩만 수정되도, 크롤링에서 지원하지 않을 지도 모르기 때문이죠.
2. Python Module
2.1 BeautifulSoup
Beautiful Soup
웹페이지에서 정보를 쉽게 스크랩할 수 있게 해주는 모듈입니다.
이는 HTML 또는 XML 파서 위에 위치하며 구문 분석 트리를 반복, 검색 및 수정하기 위한 Python 관용어를 제공합니다.
BeautifulSoup는 스크래핑 도구입니다. URL을 통해 받아온 HTML 코드를 분석하는 도구입니다.
크롤링 시에도 사용되는데, 엄밀히 말하면 직접 크롤링을 하는 주체가 아니라 크롤링해온 데이터를 HTML 객체로 파싱해주는 파싱 도구입니다.
2.2 Selenium
Selenium
Selenium WebDriver를 Python 언어로 제작된 모듈로, 웹 브라우저와의 상호작용을 자동화하기 위해 사용됩니다.
Chrome, Firefox, Internet Explorer 등 여러 브라우저 및 드라이버를 지원합니다.
출저: selenium 4.22.0
2.3 Requirements.txt
프로젝트 내에 requirements.txt 파일을 추가해주고, 라이브러리 종속성을 넣어줍니다.
requests
beautifulsoup4
selenium
webdriver_manager이미 프로젝트가 생성되어 라이브러리가 설치된 후라면 freeze, list 명령어를 통해 requirements.txt를 생성할 수 있습니다.
# freeze 명령어 사용 시
pip freeze > requirements.txt
# list 명령어 사용시
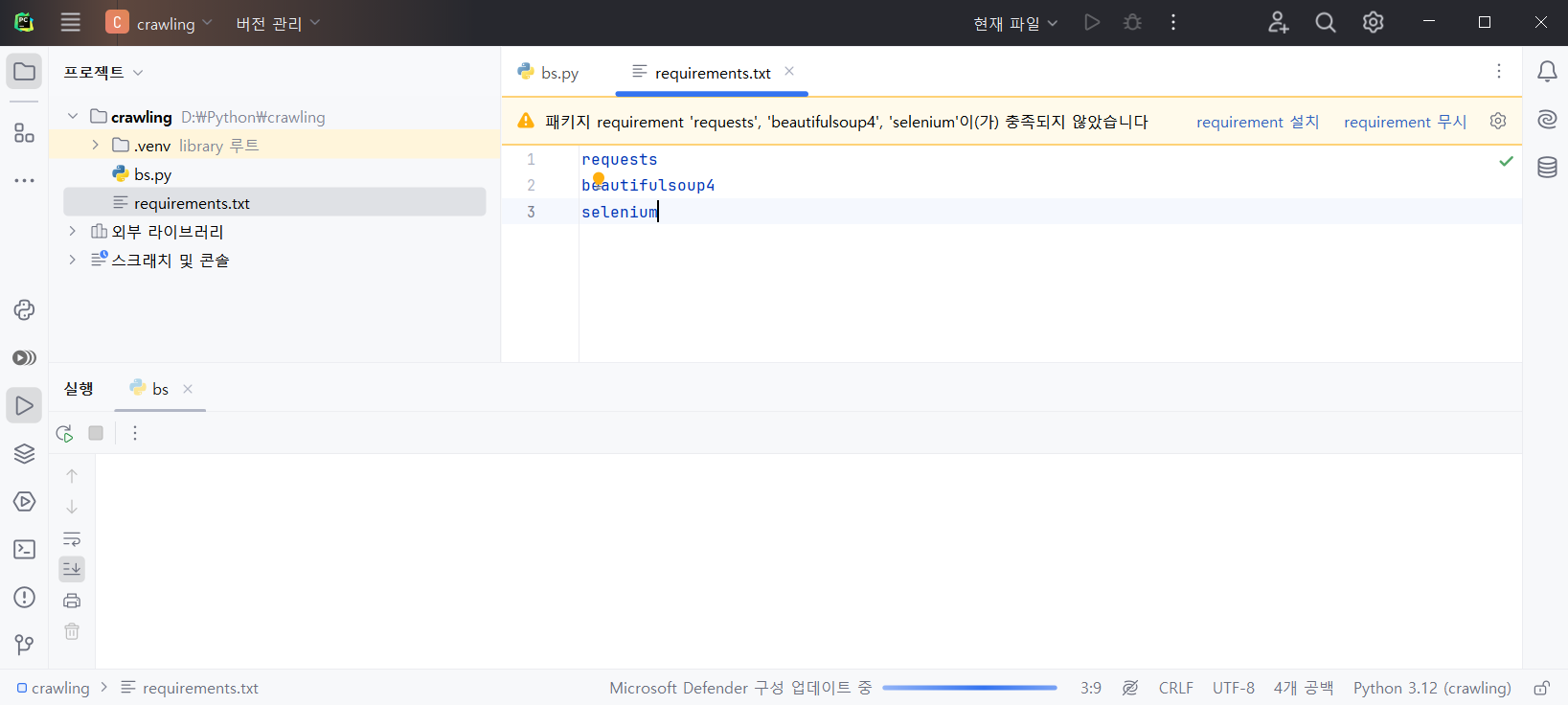
pip list --format=freeze > requirements.txt혹은 이미 requirements.txt가 있는 경우에, IDE가 지원해주지 않는다면 install 명령어를 통해 라이브러리를 설치할 수 있습니다.
pip install -r requirements.txtPyCharm에서 requirements.txt를 추가해주면, 아래와 같이 설치 여부를 물어봅니다.
3. BeautifulSoup
3.1 기본 구조
beautifulsoup의 사용 방법은 아래와 같습니다.
- 스크랩핑할 웹사이트 URL 지정
- URL을 통해 html을 받아와서 BeautifulSoup 객체로 변환
- bs 객체를 통해 데이터 파싱
import requests
from bs4 import BeautifulSoup, Tag
# 1. URL 지정
url = 'https://news.naver.com/section/105'
# 2.1 데이터 받아오기
response = requests.get(url)
if response.status_code == 200:
html = response.text
# 2.2 BS 객체로 변환
soup = BeautifulSoup(html, 'html.parser')
print(soup)
# 3. 파싱
else:
print(response.status_code)BeutifulSoup는 find() 및 findAll() 메소드를 통해 간편하게 HTML의 정보를 가져올 수 있습니다.
3.2 네이버 뉴스 스크랩핑
위의 코드를 확장하여 네이버 뉴스를 스크랩핑 해보고자 합니다.
문서 구조 파악
우선, 데이터를 파싱하기 위해서는 문서의 구조를 잘 알고 있어야합니다.
웹 사이트에서 수집할 데이터를 분석하고, F12를 통해 개발자 모드를 켜서 해당 데이터를 가져올 부분의 구조를 파악하여 합니다.
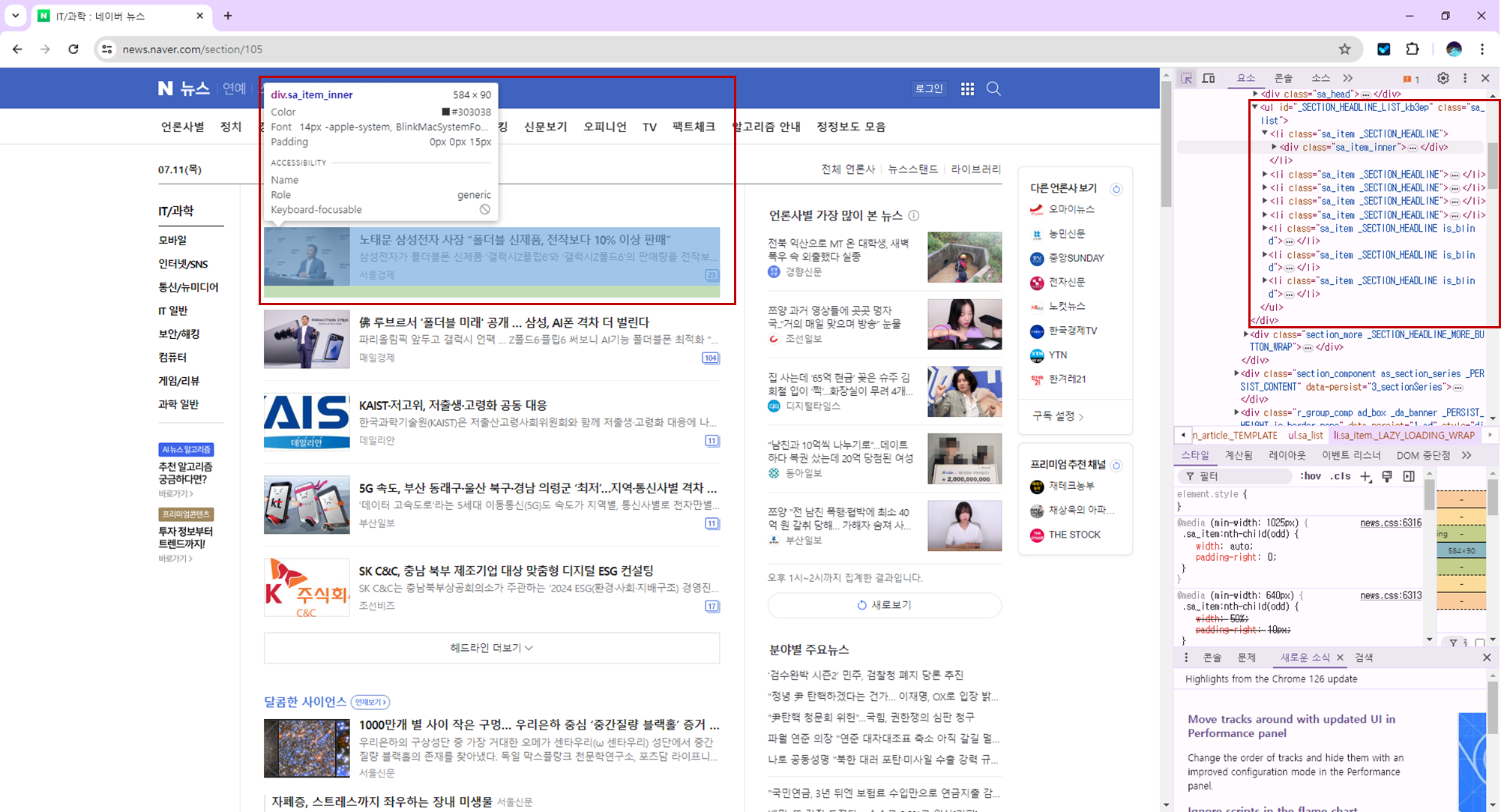
저는 뉴스 기사 목록을 뽑아내볼 생각입니다.
객체로 파싱하기
우선, 기사를 담을 Article 객체를 정의하였습니다.
class Article:
def __init__(self, title, desc, url, image_url):
self.title = title
self.description = desc
self.url = url
self.image_url = image_url
def __str__(self):
return f"Article [ \n\t Title: {self.title}
\n\t Description: {self.description}
\n\t URL: {self.url}
\n\t Image URL: {self.image_url}\n]"그런 다음, 데이터를 파싱하여 Article 객체로 변환하였습니다.
def parse(element: Tag):
try:
a_obj = element.find('a')
img_obj = element.find('img')
desc_obj = element.find('div', 'sa_text_lede')
return Article(img_obj.attrs['alt'],
desc_obj.text,
a_obj.attrs['href'],
img_obj.attrs['data-src'])
except AttributeError:
return None위의 기본 구조에서 파싱 단계를 추가하였습니다.
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
arr = list(map(lambda x: parse(x),
soup.find_all("li", {"class": "sa_item"})))
for article in arr:
print(article)
else:
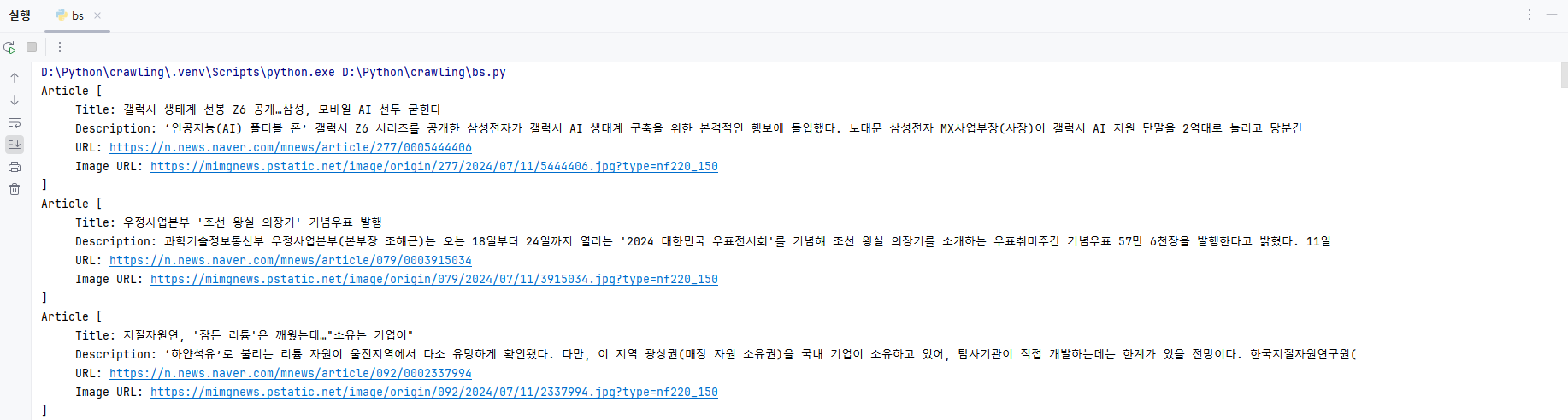
print(response.status_code)결과 화면
기사 목록이 객체로 아주 예쁘게 뽑힌 것을 볼 수 있습니다.😊
4. Selenium
일반적인 정적 웹페이지는 https 모듈로 데이터를 뽑을 수 있지만, 동적인 기능이 들어가면 (ex. 로그인, 검색, 버튼 클릭 등) 동작이 불가능합니다.
4.1 기본 구조
우선 Selenium을 사용하는 방법은 다음과 같습니다.
- WebDriver 로딩
- WebDriver로 동적 행위 (로그인, 검색 등)
- 현재 html을 받아와서 파싱해서 처리
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.ie.webdriver import WebDriver
from webdriver_manager.chrome import ChromeDriverManager
def crawler(url, seconds=1) -> WebDriver:
service = Service(ChromeDriverManager().install())
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.get(url)
time.sleep(seconds)
return driver
def get_bs(html) -> BeautifulSoup:
return BeautifulSoup(html, 'html.parser')
if __name__ == '__main__':
url = 'https://www.google.com'
# 1. 드라이버 로딩
driver = crawler(url)드라이버를 통해 url을 로딩하면 아래와 같이 자동으로 웹페이지가 뜹니다.
4.2 구글링 구현하기
구글 홈페이지를 띄워두고, 키워드를 넣어 검색한 페이지의 목록을 가져오는 코드를 작성해보려고 합니다. 위의 코드를 확장하여 구글링을 구현해보도록 하겠습니다.
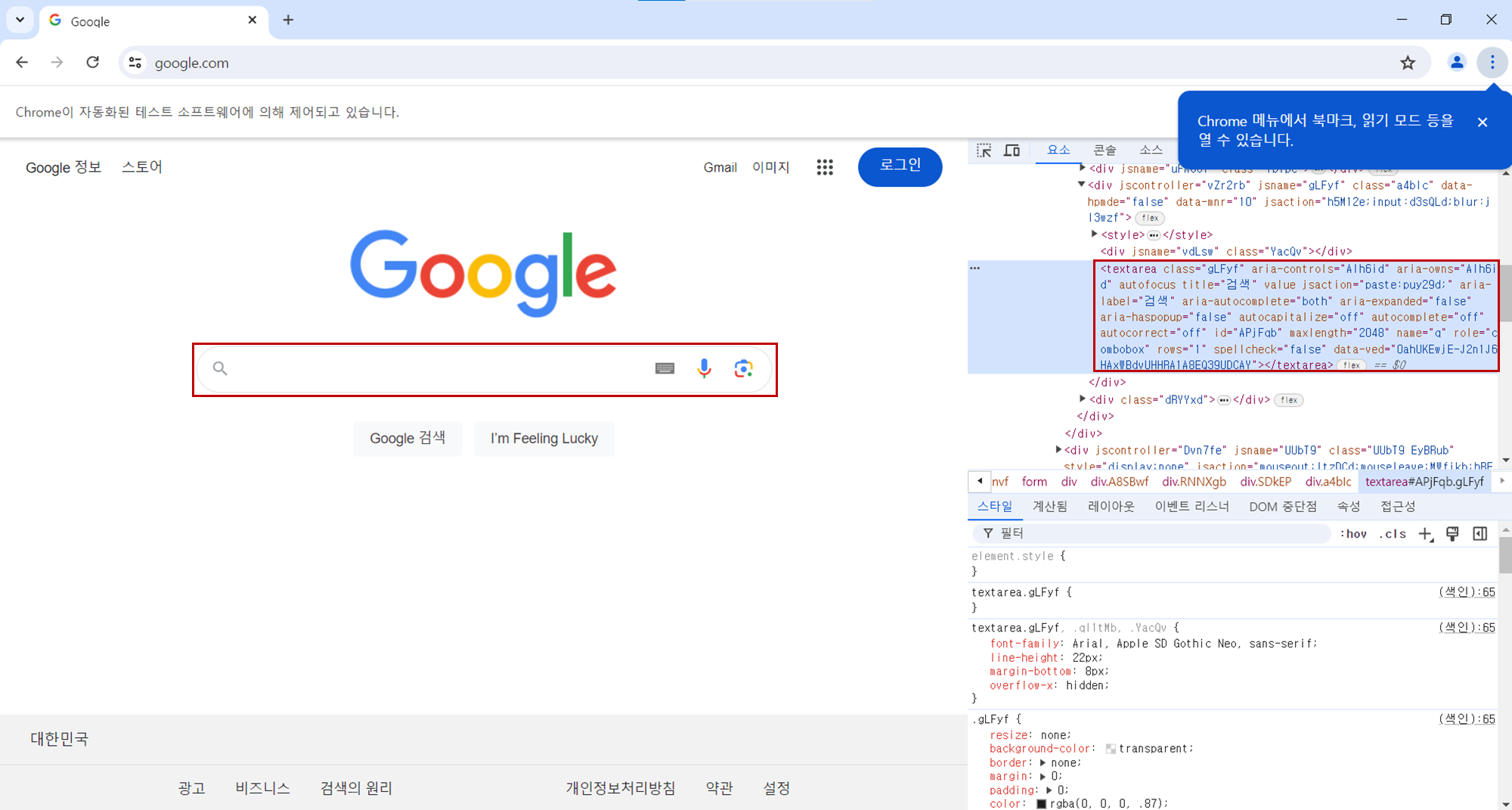
동적 행위
우선, 구글 홈페이지를 켜고 검색 영역을 분석합니다.
class Post:
def __init__(self, platform, url, title, content):
self.platform = platform
self.url = url
self.title = title
self.content = content
def __str__(self):
return f"""Post [\n\tplatform: {self.platform}
\n\t url: {self.url}
\n\t title: {self.title}
\n\t content: {self.content}\n]"""
def parse(element: Tag):
try:
platform = element.find('span', {'class': 'VuuXrf'}).text
url = element.find('a').attrs['href']
title = element.find('h3').text
content = element.find('div', {'class': 'VwiC3b'}).text
return Post(platform, url, title, content)
except AttributeError:
return None
if __name__ == '__main__':
url = 'https://www.google.com'
keyword = 'Python Selenium'
driver = crawler(url)
# 1. 검색 영역을 찾아 키워드를 넣고 검색
# By.ID, By.TAG_NAME, By.NAME, By.CSS_SELECTOR, By.CLASS_NAME, By.XPATH
input_box = driver.find_element(By.CSS_SELECTOR, "textarea.gLFyf")
input_box.send_keys(keyword)
input_box.submit()
driver.implicitly_wait(10)
# 2. 검색한 데이터를 Post 객체로 파싱
soup = get_bs(driver.page_source)
container = soup.find_all('div', class_='MjjYud')
arr = list(map(lambda x: parse(x), container))
for i in arr:
print(i)
driver.close()input 영역을 찾아 키워드를 넣고 제출합니다. 검색 버튼이 따로 없기 때문에 submit 메소드로 검색합니다.
4.3 결과 화면
Post [
platform: 위키독스
url: https://wikidocs.net/91474
title: 2.8 사이트 자동화하기 - selenium 사용법(1)
content: 코딩 실력 향상 100% 보장, 실전 파이썬 데이터 수집 강의 (도움 안되면 환불가능) ... Selenium 라이브러리를 사용하는 이유는 다음과 같습니다. 1. 자바스크립트 ...
]
Post [
platform: 티스토리
url: https://spectrum20.tistory.com/entry/python-Selenium-%ED%81%AC%EB%A1%AC-%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80
title: [python] Selenium chrome에서 시작하기 (+ 크롬 브라우저 ...
content: 2023. 10. 15. — [python] Selenium chrome에서 시작하기 (+ 크롬 브라우저, element, driver, alert 다루기) · 크롬드라이버 설치 · 코드. 파이썬 환경에 필요한 ...
]
Post [
platform: 티스토리
url: https://thecho7.tistory.com/entry/Python%EA%B3%BC-Selenium%EC%9D%84-%ED%99%9C%EC%9A%A9%ED%95%9C-%EC%9B%B9-%ED%81%AC%EB%A1%A4%EB%A7%81-%EC%8B%A4%EC%8A%B5-1
title: Python과 Selenium을 활용한 웹 크롤링 실습 - 1 1 - 조연 블로그
content: 2023. 8. 28. — Python과 Selenium을 활용한 웹 크롤링 실습 - 1 1 · Selenium 설치 · 브라우저 시작 · 웹사이트 탐험하는 방법 · Selenium 기본 기능 · 관련글 · 댓글.
]5. Image 다운로드
5.1 urlretrieve
# Test URL
url = "https://www.residentadvisor.net/images/events/flyer/2017/7/no-0713-986042-front.jpg"
def download_image(url, filename):
urlretrieve(url, filename)
if __name__ == "__main__":
download_image(url, "testPhytonImg.jpg");5.2 403 Forbidden
403 Forbidden
작동중인 서버에 클라이언트의 요청이 도달했으나, 서버가 클라이언트의 접근을 거부할 때 반환하는 HTTP 응답 코드이자 오류 코드다.
출저 - Wiki
Image 다운로드하는데 403 에러가 뜬다.
이유는 User-Agent 정보가 없어서 그렇습니다.
User-Agent
user agent는 HTTP 요청을 보내는 디바이스와 브라우저 등 사용자 소프트웨어의 식별 정보를 담고 있는 request header의 한 종류이다.
- 형태: Mozilla 정보/버전 + 운영체제 정보 + 렌더링 엔진 정보 + 브라우저
출저 - User-agent 정확하게 해석하기
User-Agent는 쉽게 말해 접속하는 장치(브라우저, 디바이스)의 정보인데, request 라이브러리를 통해 요청할 경우 로봇(크롤러)라 판단하여 접속을 막는 것입니다. 쉽게 말해, 보안 조치라고 생각하면 됩니다.
코드를 조금 수정하여 header에 User Agent를 추가하여 요청해면 데이터를 다운받을 수 있습니다. (이렇게 수집된 데이터를 활용해서는 안됩니다)
import urllib.request
# Test URL
url = "https://www.residentadvisor.net/images/events/flyer/2017/7/no-0713-986042-front.jpg"
def download_image(url, filename):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537',
}
req = urllib.request.Request(url, None, headers)
res = urllib.request.urlopen(req)
f = open(filename, 'wb')
f.write(res.read())
f.close()
if __name__ == "__main__":
download_image(url, "testPhytonImg.jpg");출저 - Stack Overflow
💎 Reference
