단어기반 문서 검색에 대해 배워보자. 먼저 문서 검색 (Passage retrieval) 이란 어떤 문제인지에 대해 알아본 후, 문서 검색을 하는 방법에 대해 알아본다. 문서 검색을 하기 위해서는 문서를 embedding의 형태로 변환해 줘야 하는데, 이를 passage embedding 이라고 한다. passage embedding이 무엇인지 알아보는 동시에, 단어 기반으로 만들어진 passage embedding인 sparse embedding, 그 중에서도 자주 쓰이는 TF-IDF에 대해 알아보자.
Passage Retrieval - Sparse Embedding
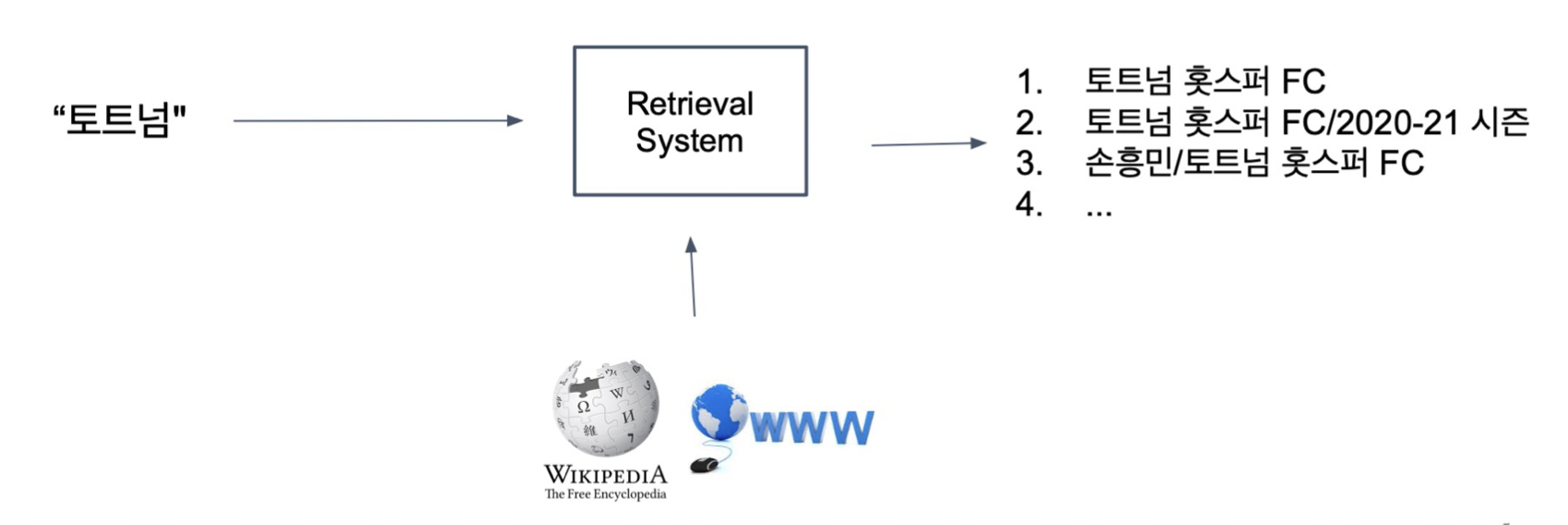
Passage Retrieval
: 질문(query)에 맞는 문서(passage)를 찾는 것
Passage Retrieval with MRC
Open-domain Question Answering: 대규모의 문서 중에서 질문에 대한 답을 찾기 Passage Retrieval과 MRC를 이어서 2-Stage로 만들 수 있음.
Passage Retrieval 방법
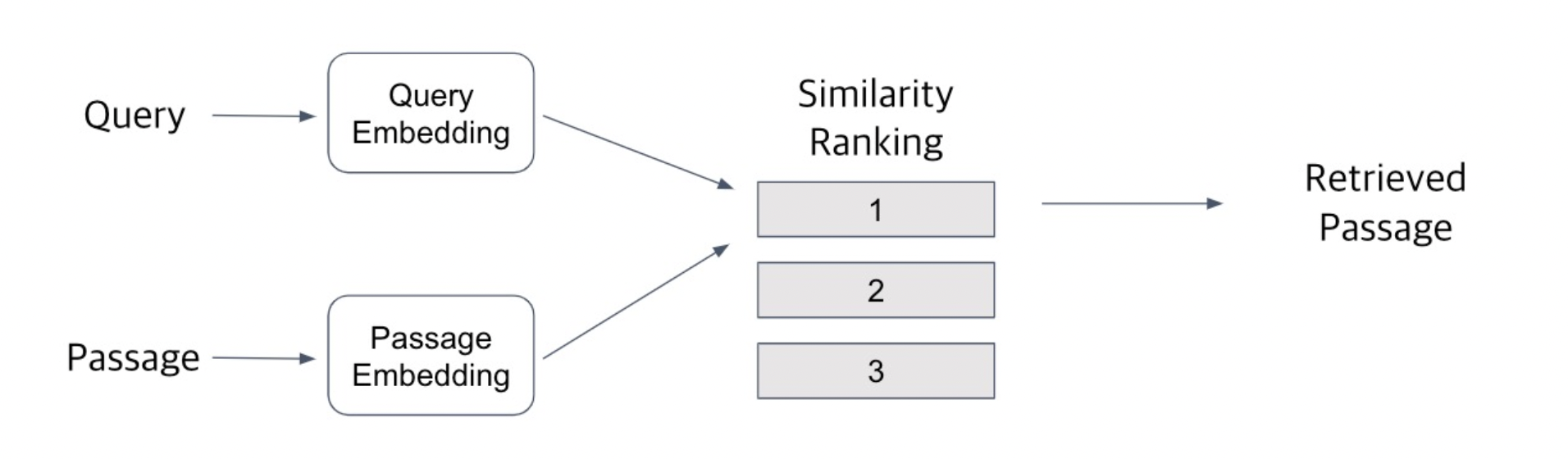
Query와 Passage를 임베딩한 뒤 유사도로 랭킹을 매기고, 유사도가 가장 높은 Passage를 선택
Passage Embedding and Sparse Embedding
Passage Embedding Space
Passage Embedding의 벡터 공간.
벡터화된 Passage를 이용하여 Passage 간 유사도 등을 알고리즘으로 계산할 수 있음.
Sparse Embedding
Bag-of-Words(BoW)
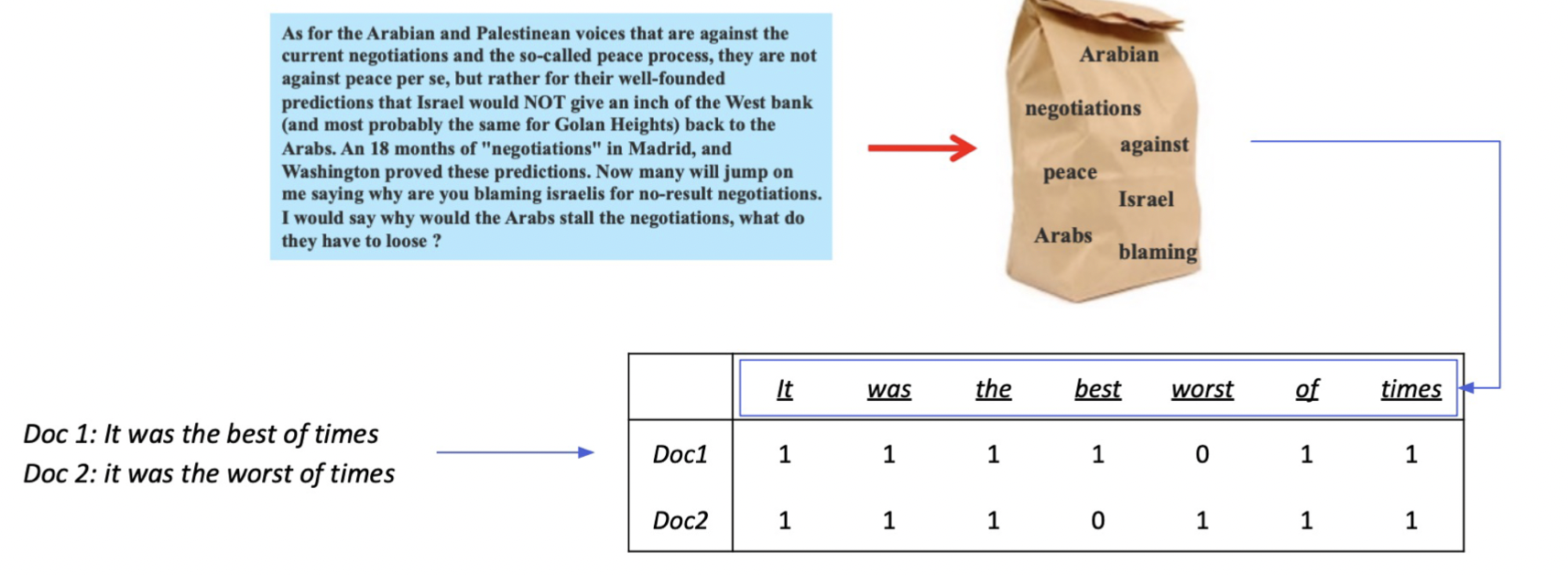
단어가 존재하는지 아닌지에 따라 1, 0으로 표기하기 때문에 한 문서는 vocab size를 가짐.
- BoW를 구성하는 방법 (n-gram)
– unigram (1-gram): It was the best of times => It, was, the, best, of, time
– bigram (2-gram): It was the best of times => It was, was the, the best, best of, of times
unigram의 vocab size가 100이라고 한다면 모든 가능한 bi-gram의 vocab size는 100의 제곱인 10000이다. 2-gram은 unigram이 두 개씩 모여있기 때문에 dimension이 두 배가 되기 때문이다. n을 높게하는 것이 desriable하지는 않고 bi gram이나 trigram이 선호된다. - Term value 를 결정하는 방법
– Term이 document에 등장하는지 (binary)
– Term이 몇번 등장하는지 (term frequency), 등. (e.g. TF-IDF)
Sparse Embedding 특징
- Dimension of embedding vector : number of terms
– 등장하는 단어가 많아질수록 증가
– N-gram의 n이 커질수록 증가 - Term overlap을 정확하게 잡아 내야 할 때 유용.
- 반면, 의미(semantic)가 비슷하지만 다른 단어인 경우 비교가 불가
--> 특정 단어가 문서에 포함되어 있는지 아닌지를 파악하기에는 매우 유용하다.
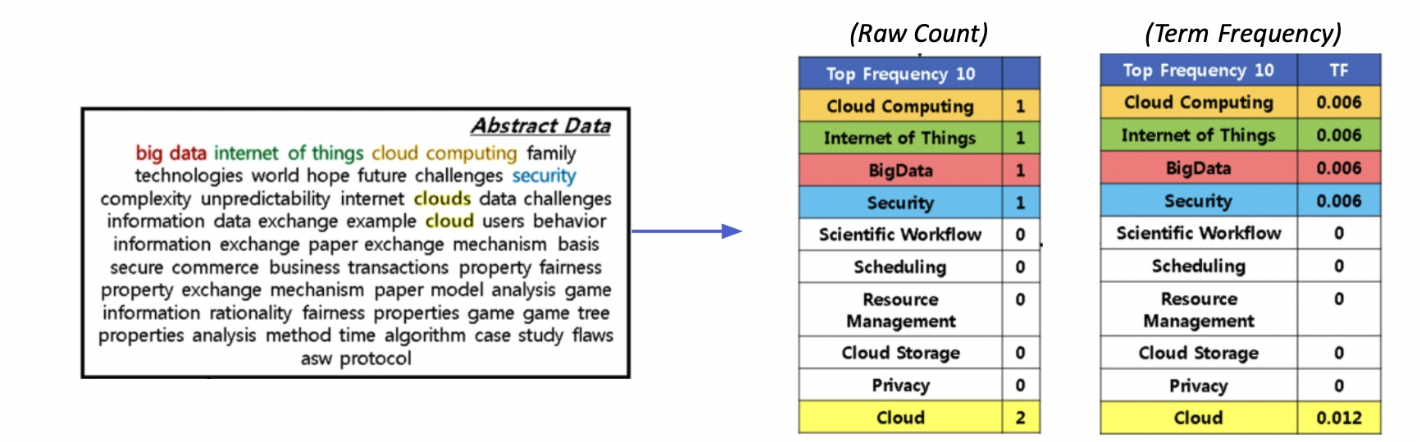
TF-IDF(Term Frequency – Inverse Document Frequency)
• Term Frequency (TF): 단어의 등장빈도
• Inverse Document Frequency (IDF): 단어가 제공하는 정보의 양
ex) It was the best of times
It, was, the, of: 자주 등장하지만 제공하는 정보량이 적음
best, times: 좀 더 많은 정보를 제공
Term Frequency (TF)
해당 문서 내 단어의 등장 빈도
1. Raw count
2. Adjusted for doc length: raw count / num words (TF)
3. Other variants: binary, log normalization, etc.
Inverse Document Frequency (IDF)
단어가 제공하는 정보의 양
DF = Term t가 등장한 document의 개수
N = 총 document의 개수
TF-IDF for term t in document d
- ‘a’, ‘the’ 등 관사 ⇒ Low TF-IDF
: TF는 높을 수 있지만, IDF가 0에 가까울 것
(거의 모든 document에 등장 ⇒ N ≈ DF(t) ⇒ log(N/DF) ≈ 0) - 자주 등장하지 않는 고유 명사 (ex. 사람 이름, 지명 등) ⇒ High TF-IDF : IDF가 커지면서 전체적인 TF-IDF 값이 증가
TF-IDF로 유사도 구하기
목표: 계산한 TF-IDF를 가지고 사용자가 물어본 질의에 대해 가장 관련있는 문서를 찾자
1. 사용자가 입력한 질의를 토큰화
2. 기존에 단어 사전에 없는 토큰들은 제외
3. 질의를 하나의 문서로 생각하고, 이에 대한 TF-IDF 계산
4. 질의 TF-IDF 값과 각 문서별 TF-IDF 값을 곱하여 유사도 점수 계산
5.가장 높은 점수를 가지는 문서 선택
BM25
Code 실습
데이터셋의 집합을 Corpus로, tokenizing을 실시한 뒤
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(tokenizer=tokenizer_func, ngram_range=(1,2))ngram_range는 (1,1)일 때 only unigram, (1,2)일 때 unigram과 bigram, (2,2)일 때는 only bigram을 사용하는 것을 의미한다.
fit() 함수를 통해 corpus를 학습시키고, 학습된 vectorizer의 transform()함수를 통해 변환한다.
Retrieval 단계는 다음과 같다.
먼저 내가 원하는 Query 질문을 가져와서 Tf-idf vectorizing을 진행하고, corpus를 tf-idf로 학습시킨 matrix와의 유사도를 inner product로 계산한다. 결과값은 Corpus 개수만큼의 값이 나올 것이고, 각 Corpus 중 유사도가 가장 높은 Top k개의 Context데이터를 가지고오는 방식으로 Retrieval을 실시한다.
sorted_result = np.argsort(-result.data)
doc_scores = result.data[sorted_result]
doc_ids = result.indices[sorted_result]np.argsort는 꽤 유용해보인다. 알아두자.
