BoostCamp_level2_Pstage_MRC
1.Boostcamp week11 day1 level2 MRC Overview
기계독해 & 파이썬 베이직 소개기계독해란?기계독해 평가방법 언어처리를 위한 파이썬 베이직 기계독해 데이터셋 들여다 보기 추출기반 기계독해추출기반으로 기계독해 접근하기Hugging Face와 BERTBERT를 기계독해에 fine-tune 해보기생성기반 기계독해생성기반으로
2.Boostcamp week11 day1
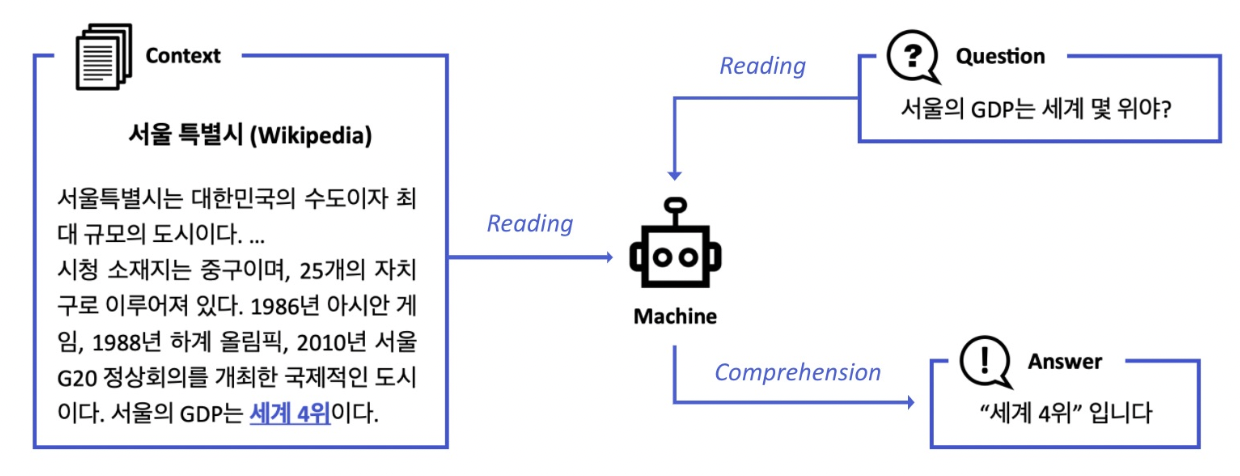
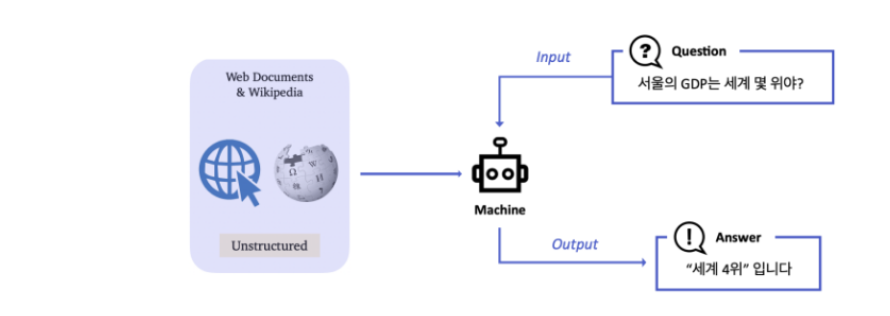
Question Answering (QA)은 다양한 종류의 질문에 대해 대답하는 인공지능을 만드는 연구 분야이다.다양한 QA 시스템 중, Open-Domain Question Answering (ODQA) 은 주어지는 지문이 따로 존재하지 않고 사전에 구축되어있는 Kn
3.Boostcamp week11 day2 Extraction-based MRC
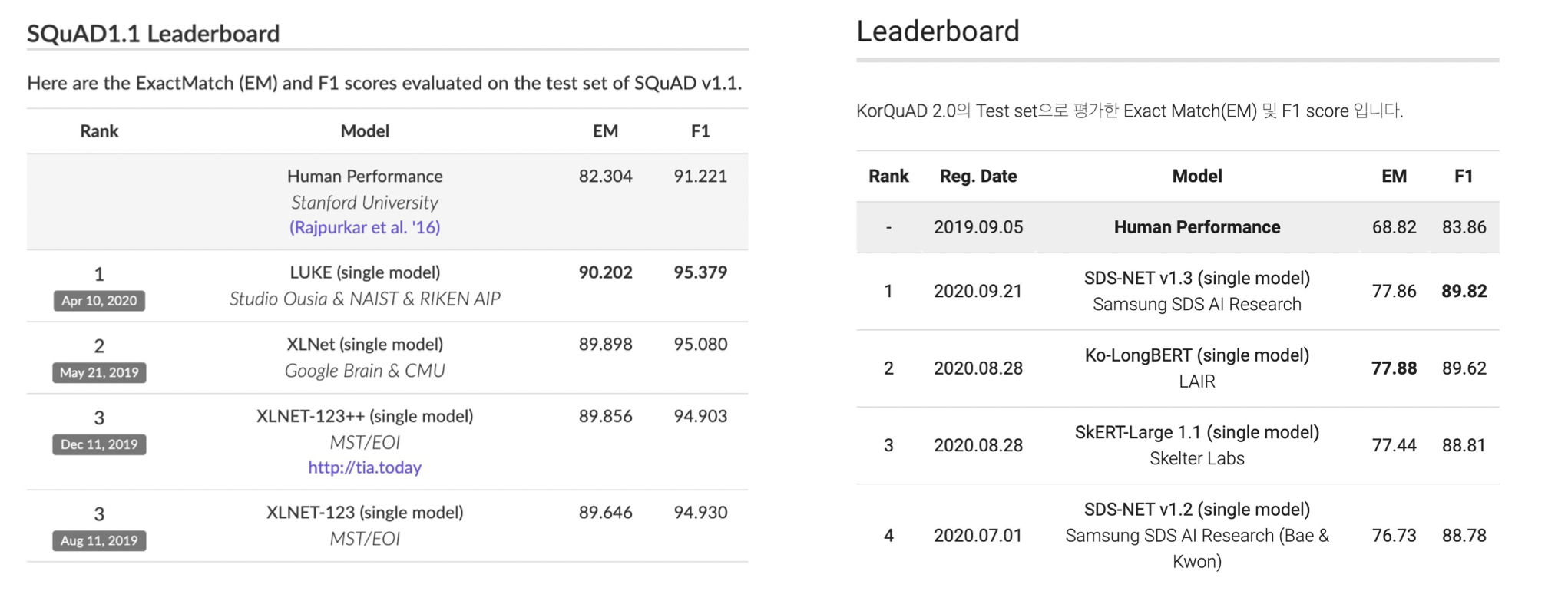
질문(question)의 답변(answer)이 항상 주어진 지문(context)내에 span으로 존재 e.g. SQuAD, KorQuAD, NewsQA, Natural Questions, etc.
4.Boostcamp week11 day2 Generation-based MRC
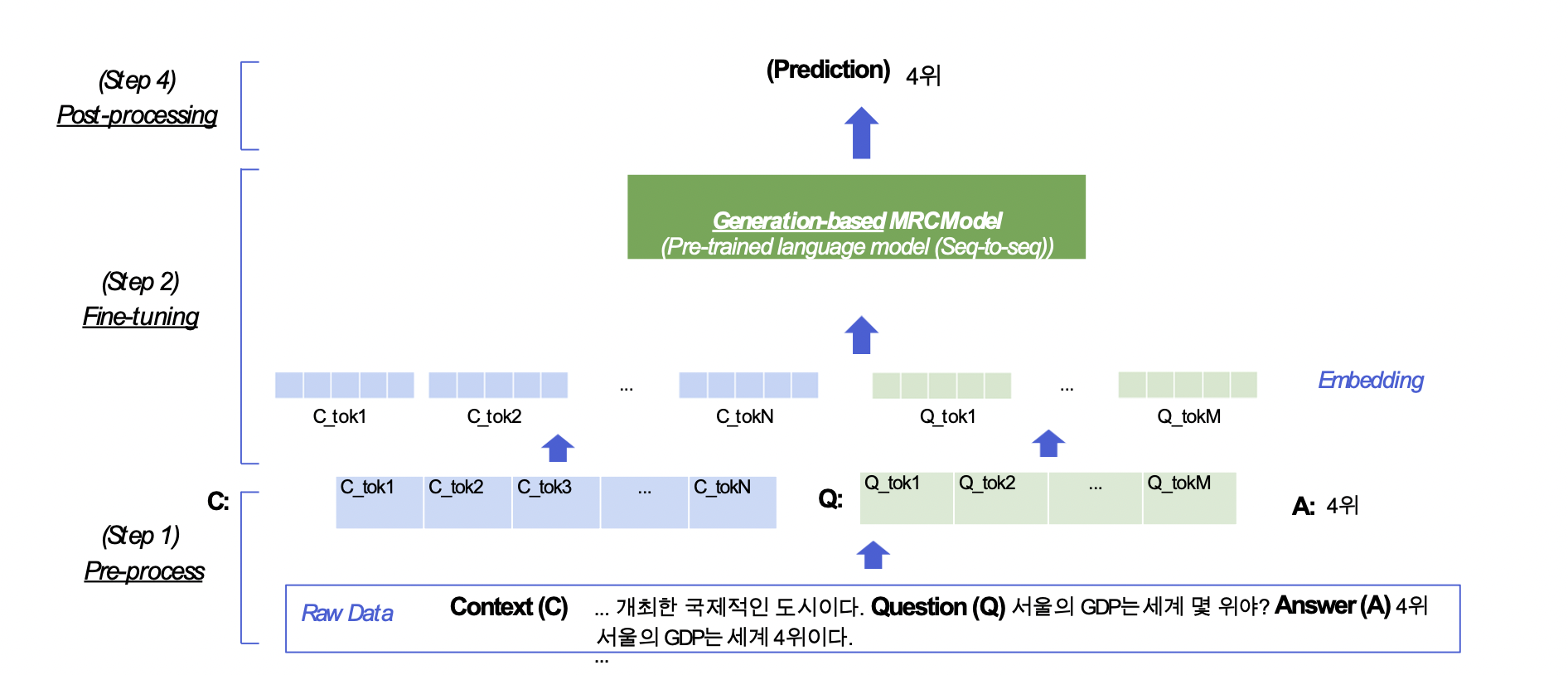
1) Extraction-based mrc: 지문 (context) 내 답의 위치를 예측 ⇒ 분류 문제 (classification)2) Generation-based mrc: 주어진 지문과 질의 (question) 를 보고, 답변을 생성 ⇒ 생성 문제 (generat
5.Boostcamp week11 day2 MRC with BERT, T5

샘플된 KorQuAD 데이터에 대해서 BERT를 fine-tuning 시키는 코드를 실습해보며, max_train_samples 를 조절하면서 원하는 개수만큼 학습 데이터를 선택할 수 있다.제공되는 코드를 기반으로 중요한 포인트에 집중하여 공부해보세요.Point 1.
6.Boostcamp week11 day3 Passage Retrieval - Sparse Embedding
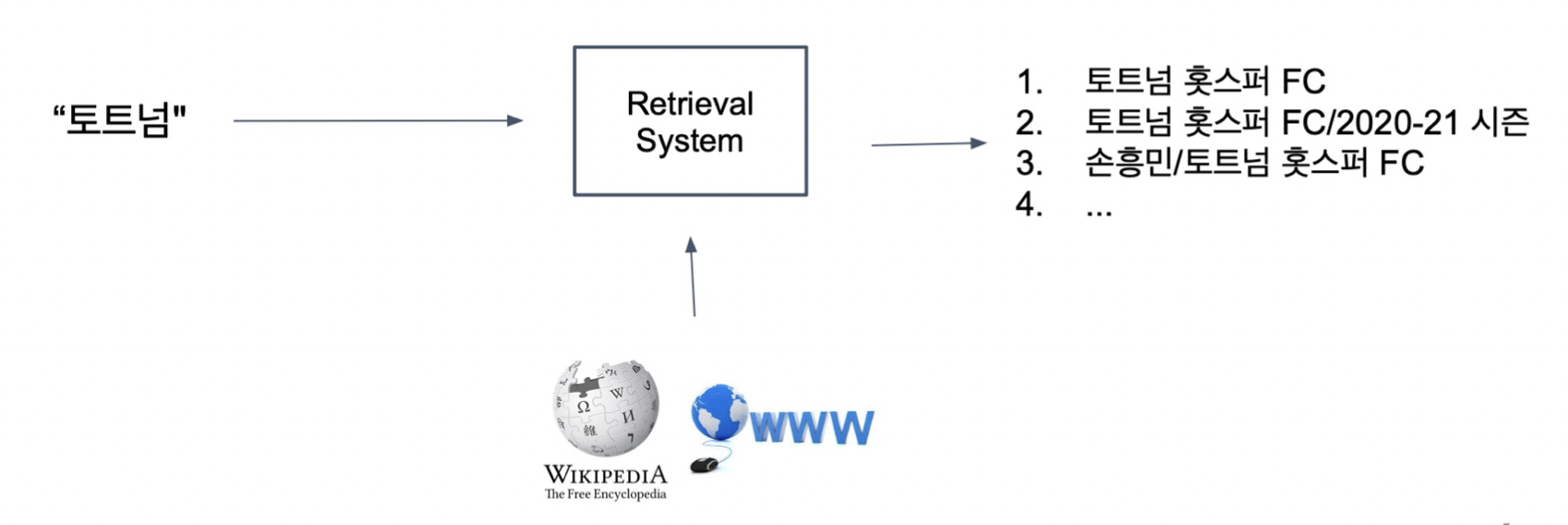
Passage Retrieval - Sparse Embedding
7.Boostcamp week11 day3 Passage Retrieval - Dense Embedding
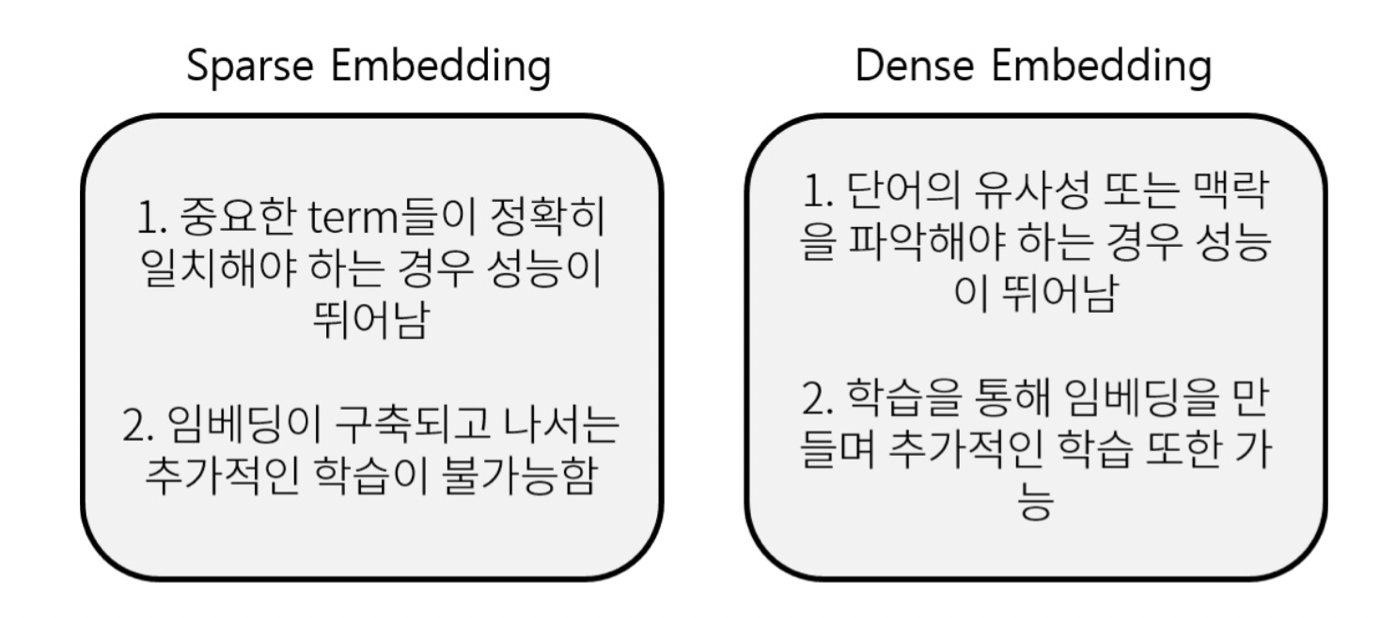
Passage Retrieval - Dense Embedding
8.Boostcamp week11 day4 Passage Retrieval -Scaling up FAISS
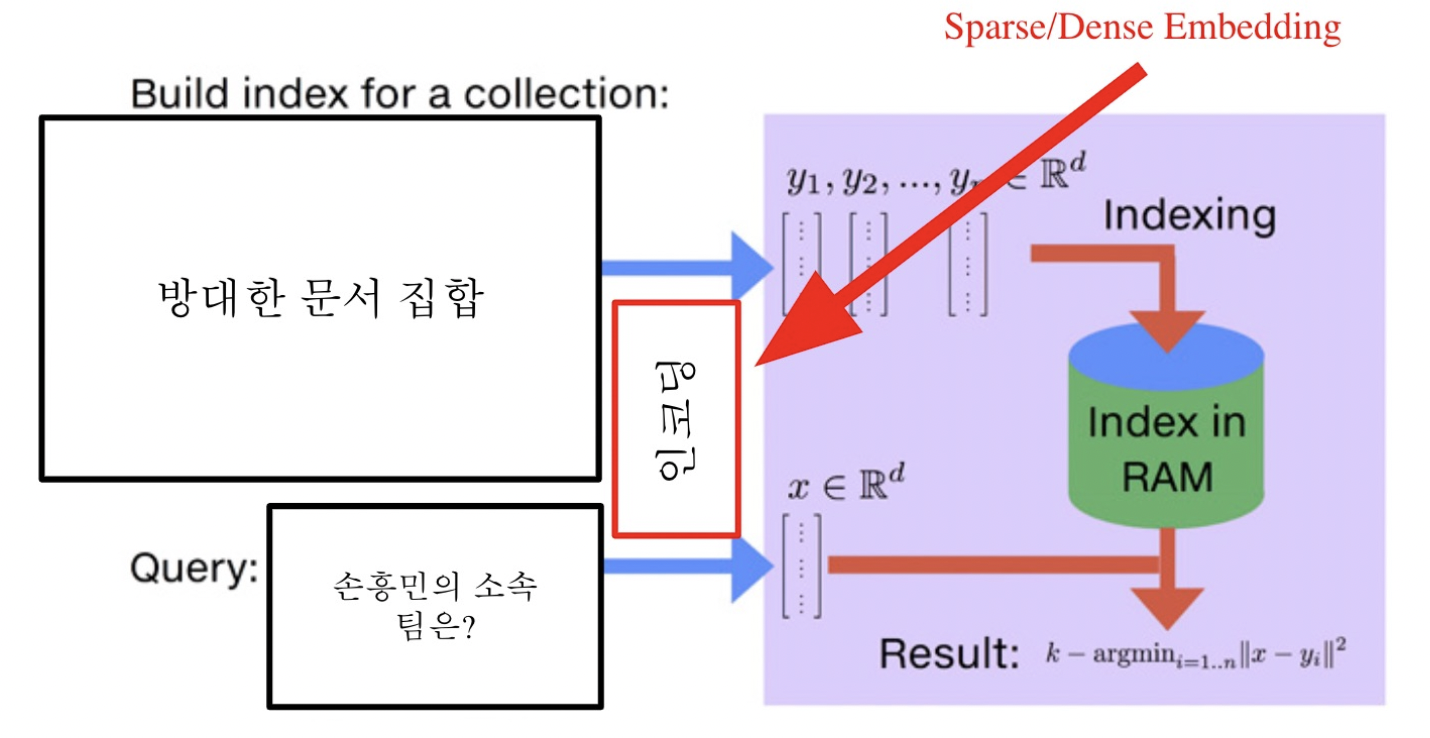
Dense Retrieval방법은 Query와 Passage를 vecotr 공간에 Embedding 한 뒤에 가장 가까운 거리에 임베딩 된 passage를 검색하는 방법이다. 가까운 거리를 찾는 방법으로 cosine similarity를 구하는 방법이 있는데, 이 때
9.Boostcamp week11 day5 Passage Retrieval 구현
Sprase Retrieval 구현수업시간에 배운 TF-IDF를 통해 문서들의 Sparse Representation을 구한 후, 벡터 내적을 통해 유사도를 구하여 관련된 문서를 구한다. 간단한 사용과 확장성을 위해 Class로 코드를 합쳐보자.Dense Retriev
10.Boostcamp week12 day1 Pre/Post-processing functions
Pre-processing functions, Post-processing functions
11.Boostcamp week12 day1 NLP model 정리
이 블로그를 참고해보자.
12.Boostcamp week12 Linking MRC and Retrieval
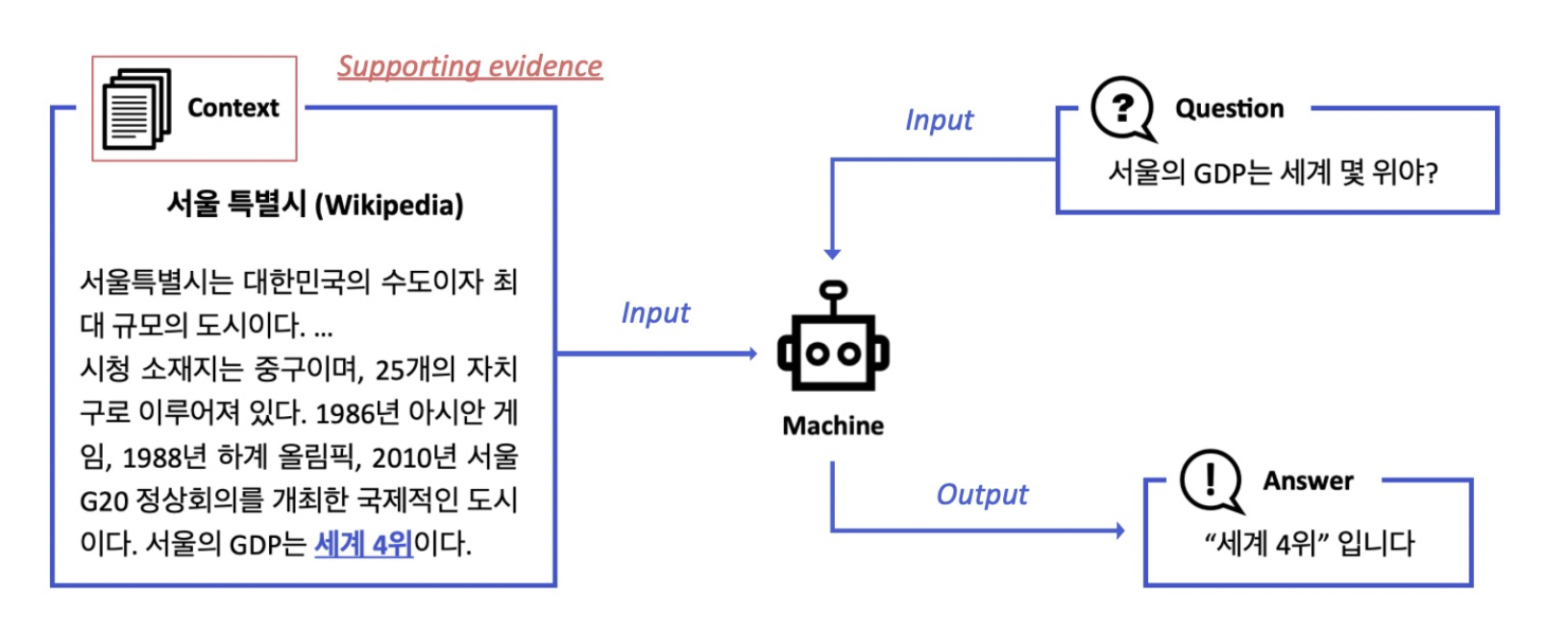
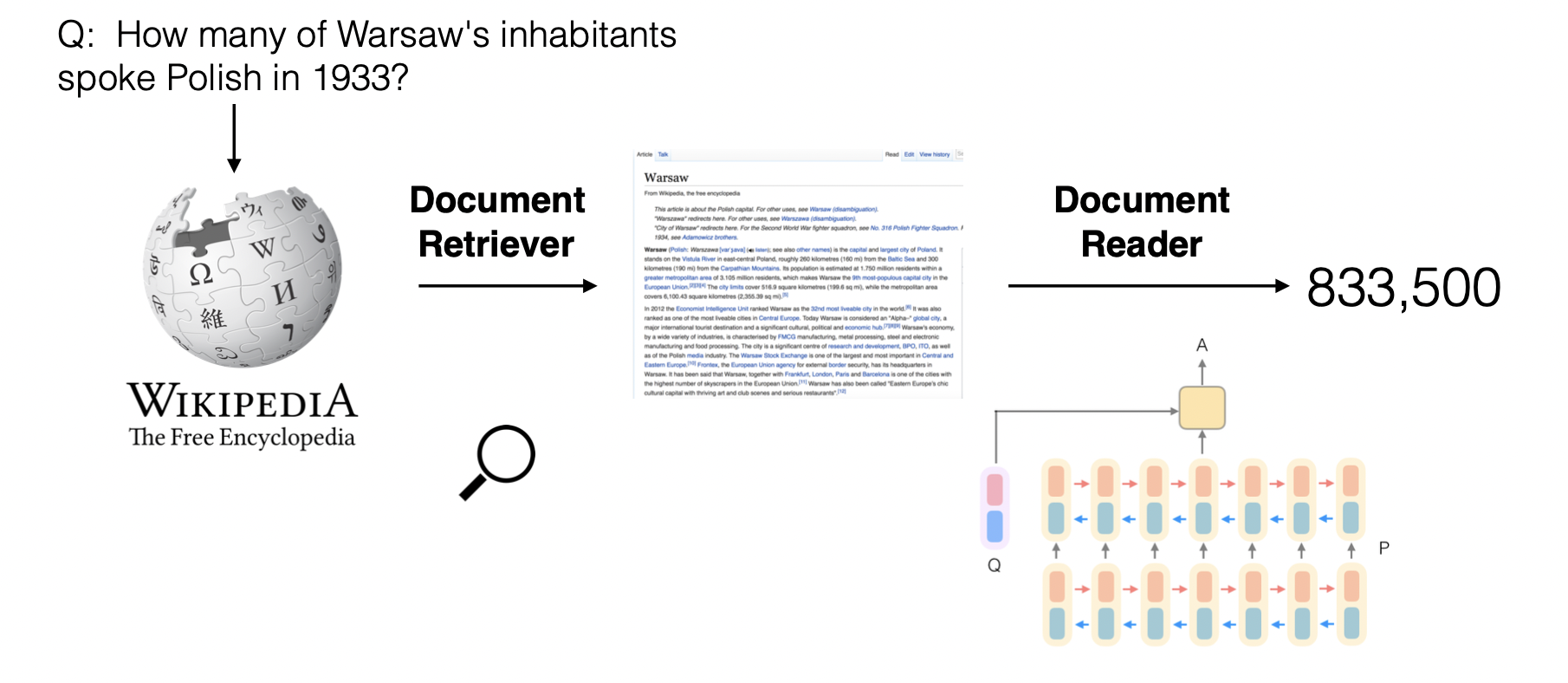
기존의 MRC는 문서가 주어지고 해당 문서에서 질문에 대답하는 task였다. 앞서 봤던 Reader들이 여기에 속한다. 그러나 ODQA(Open Domain Qustion Answering) 의 경우 supporting evidence 중에 문서를 검색해서 reader
13.Boostcamp week12 Retrieval Process
이제 Baseline에 대한 코드 리뷰도 끝났고, QA Task에 대한 어느정도 학습이 끝이 났다. 마무리하는 과정으로 Retrieval하는 과정을 이야기해보려한다.Sparse Retrieval에는 TF-IDF, BM25가 있다. 학습이 필요하지 않은 방법으로, 미리
14.Boostcamp week12 Inference, Retrieval, QAtrainer
Baseline의 구조에 대해 요약하려한다.main함수에서는 다음과 같은 순서로 코드가 실행된다.Argument ParserLogger, Dataset 정의Pretrained Reader model 호출다음과 같이 실행a. eval_retrieval = True : r
15.Boostcamp week12 추가학습 DrQA, ORQA, DPR 논문 리뷰
관련 자세한 정보는 다음을 참조하자.1\. https://jeonsworld.github.io/NLP/orqa/2\. https://www.slideshare.net/kwanghoheo58/drqa-201708233\. https://gith