1. Passage Retrieval and Similarity Search
Dense Retrieval방법은 Query와 Passage를 vecotr 공간에 Embedding 한 뒤에 가장 가까운 거리에 임베딩 된 passage를 검색하는 방법이다. 가까운 거리를 찾는 방법으로 cosine similarity를 구하는 방법이 있는데, 이 때 dot-product연산을 활용하며 dimension이 커지면서 발생할 수 있는 과도한 연산량의 문제를 해결하는 방법이 필요했다. 즉, Simliarity Search이다.
효율성 측면에서 l2 norm, euclidean distance보다 두 벡터의 dot-product를 통해 계산하는 값이 maximize되는 문제로 보는 것이 훨씬 수월하다.
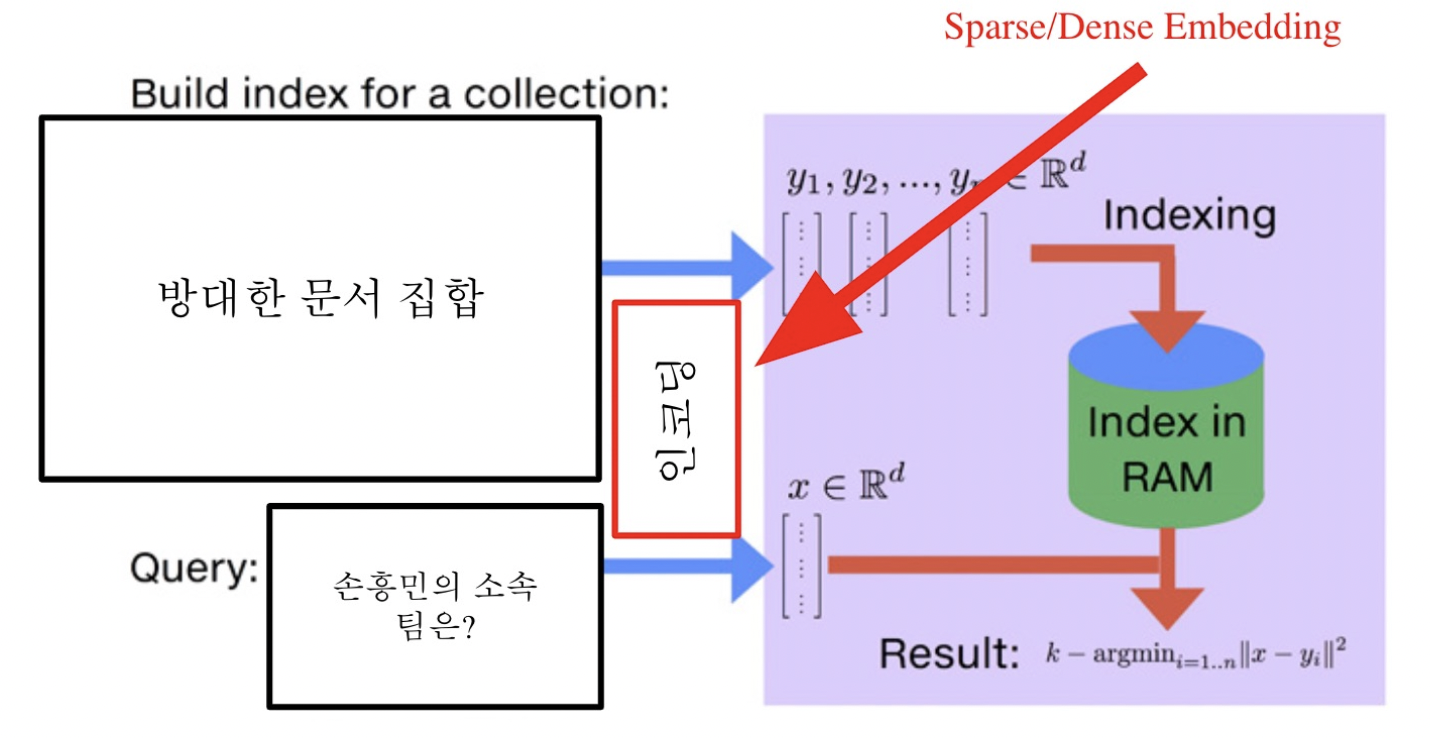
MIPS(Maximum Inner Product Search)
즉, 내적이 가장 큰 값을 통해 주어진 질문 Q에 대해 가장 관련성이 높은 passage 벡터를 찾아야한다. 이전까지 배운 방법으로는 Brute-Force search를 사용하여 저장해둔 모든 임베딩에 대해 일일히 score를 계산하여 가장 값이 높은 passage를 추출하는 방식이었다.
MIPS & Challenges
- 실제로 검색해야할 데이터는 훨씬 방대하다. 수십 억, 조 단위까지 커질 수 있다.
- 따라서 더이상 모든 문서 임베딩을 일일히 보면서 검색할 수는 없다.
2. Approximating Similarity Search
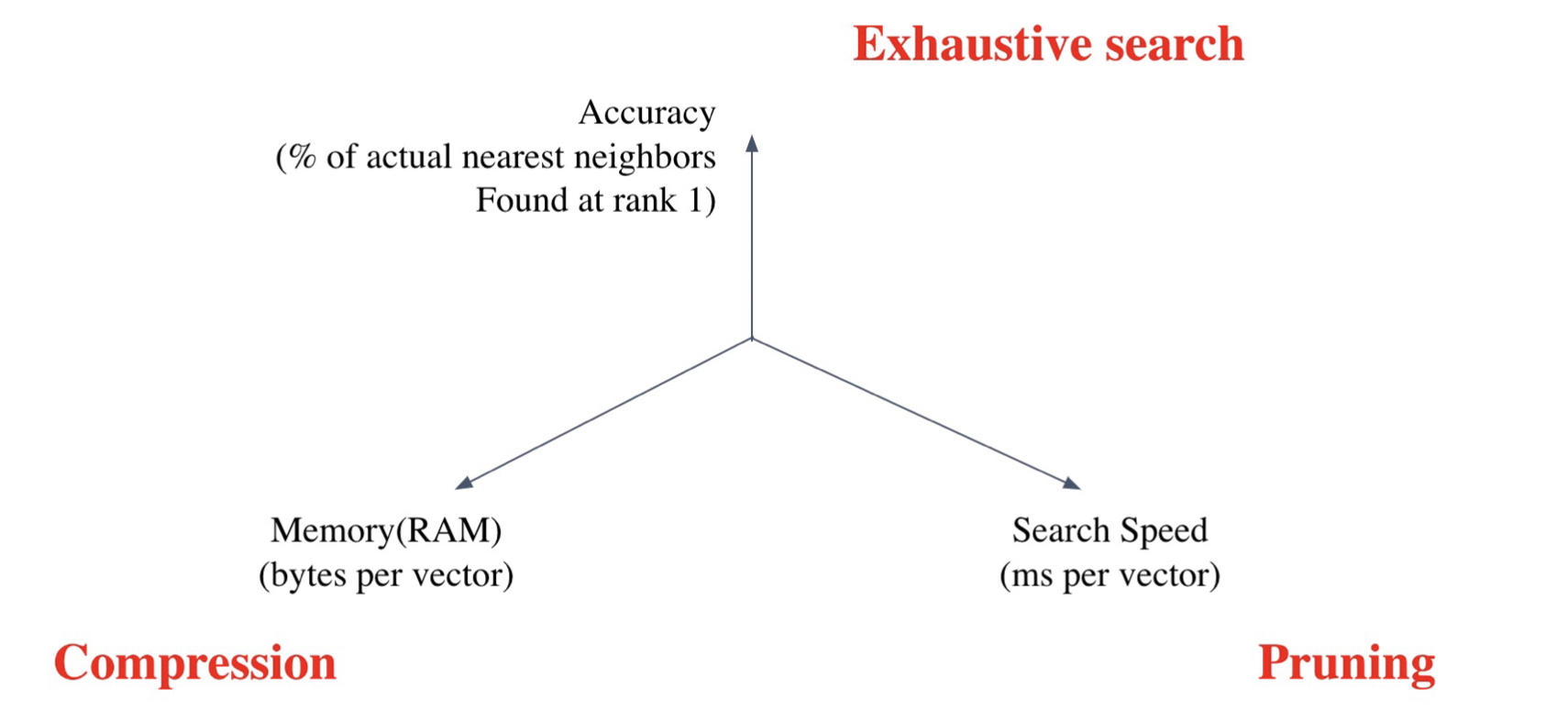
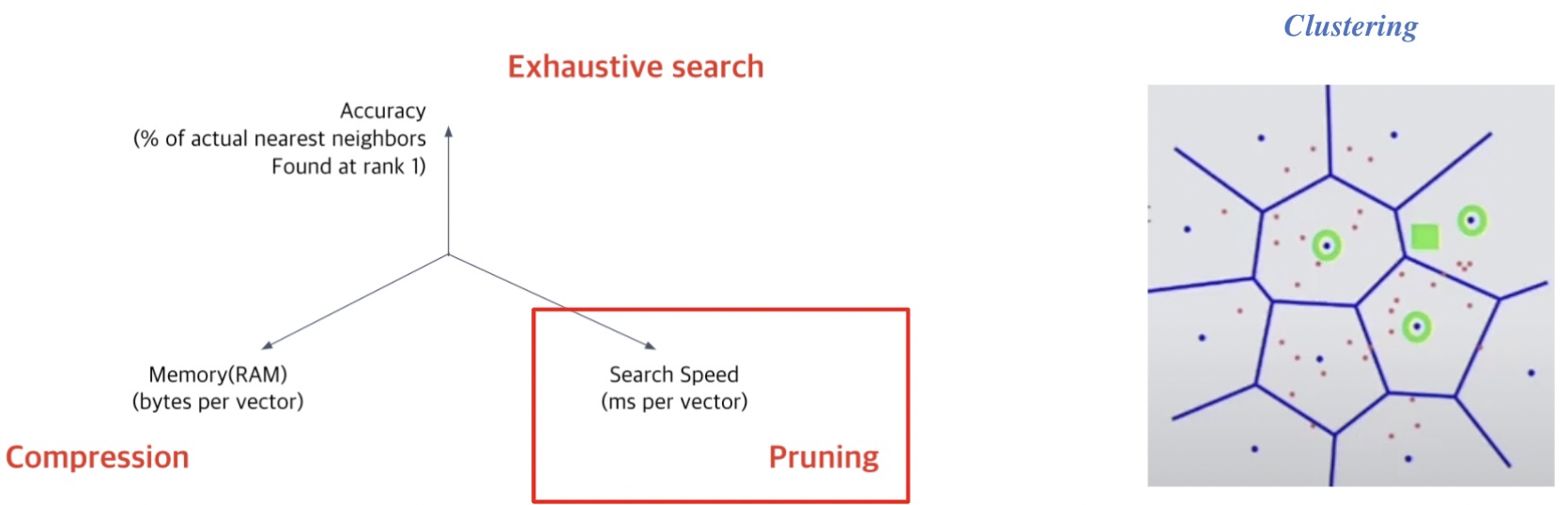
Tradeoffs of sim search
- Search speed : 적절한 가지치기
- Memory Usage : 적은 용량으로 저장하도록
- Accuracy
- brute-force 검색 결과에 비하면 정확도를 희생해야한다.
Increasing search space by bigger corpus
코퍼스의 크기가 커질 수록 탐색 공간이 커지고 검색이 어려워진다.
저장해 둘 memory space 또한 많이 요구된다.
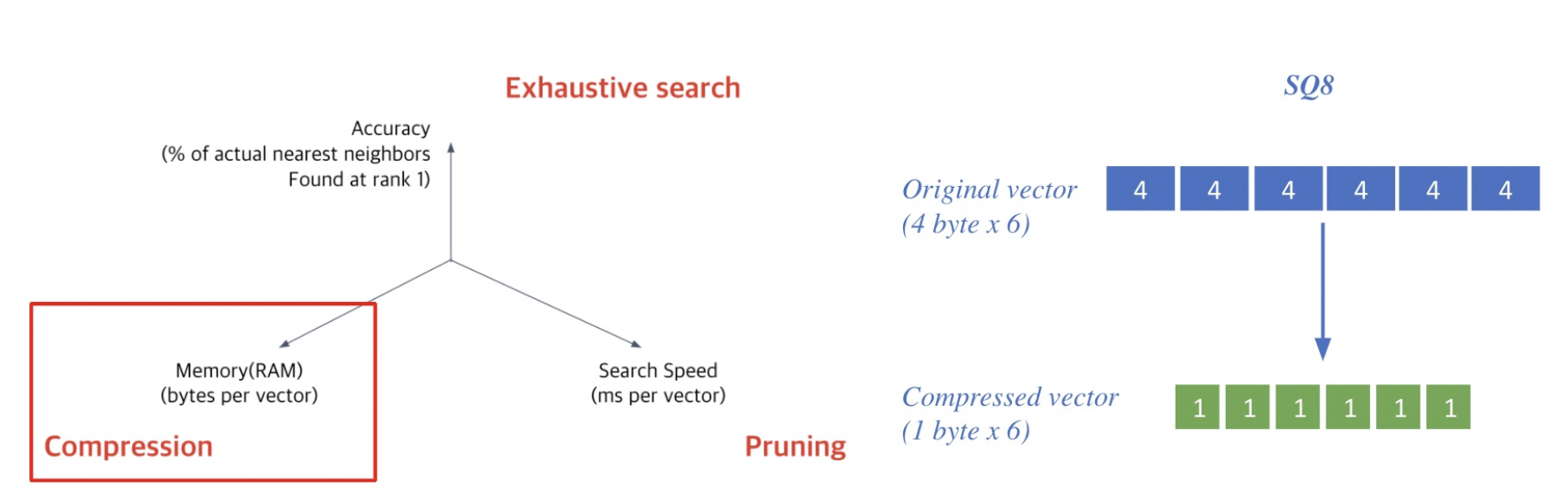
Compression - Scaler Quantization(SQ)
Pruning - Inverted File(IVF)
Search space를 줄여 search 속도 개선(dataset의 subset만 방문)
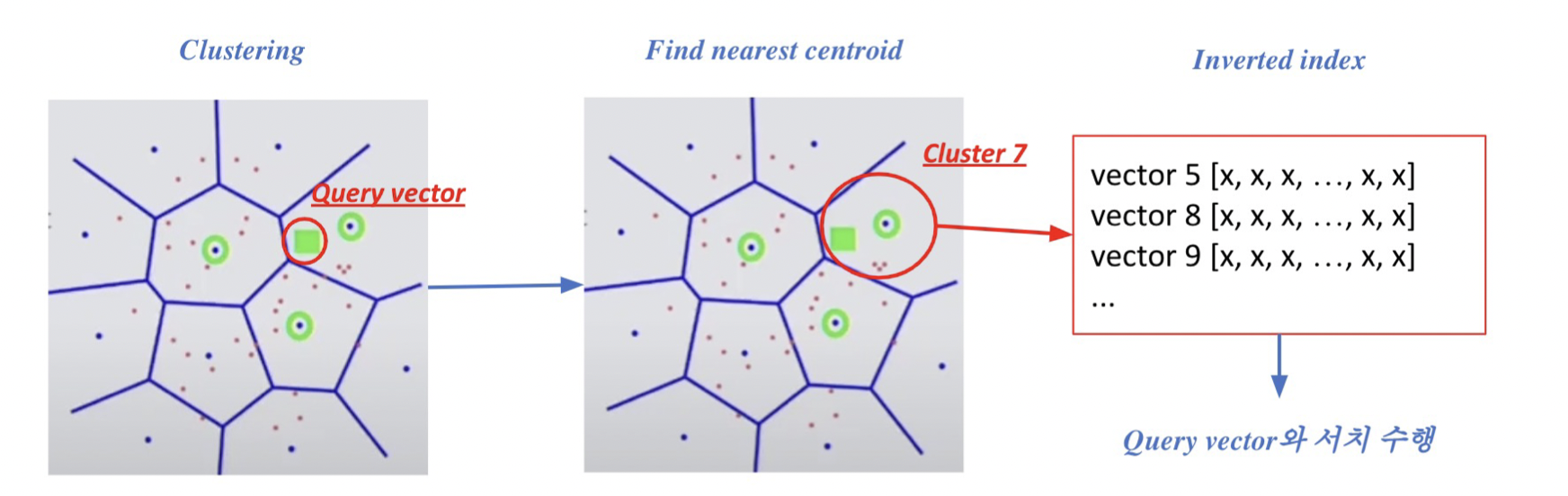
1. Clustering: K-means 군집화를 가장 많이 활용
2. Inverted file(IVF)
Vector의 index = inverted list structure
: 각 클러스터의 centroid id와 해당 클러스터의 vector들이 연결되어있는 상태
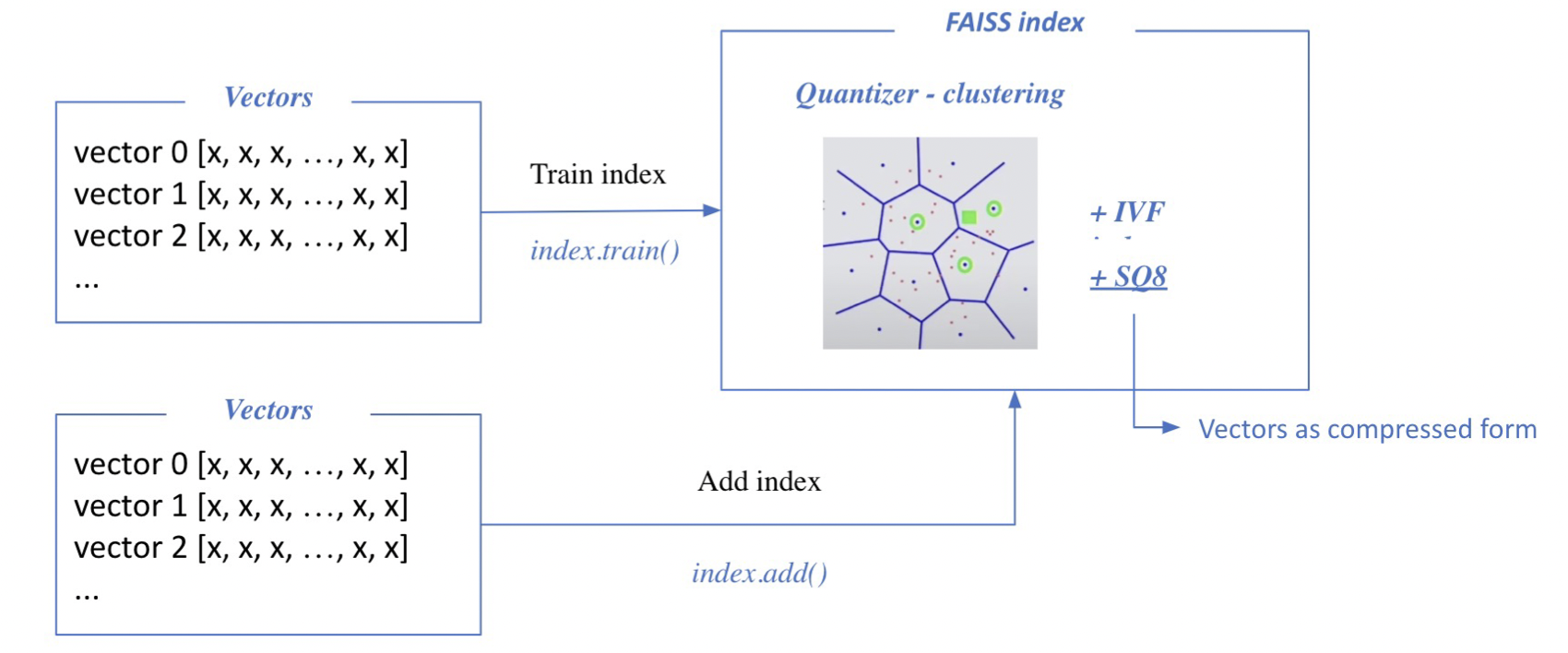
3. FAISS
Faiss : library for efficient similarity search
Quantization을 진행할 때만 train한다. 그렇지 않을 시 add만 진행.