관련 자세한 정보는 다음을 참조하자.
1. https://jeonsworld.github.io/NLP/orqa/
2. https://www.slideshare.net/kwanghoheo58/drqa-20170823
3. https://github.com/danqi/acl2020-openqa-tutorial/blob/master/slides/part5-dense-retriever-e2e-training.pdf
4. https://junseong.oopy.io/paper-reveiw/dpr
5. https://www.facebook.com/111809756917564/posts/276190540479484/
DrQA
2017년 facebook AI research 팀에서 발표한 Open Domain Question Answering 논문이다.
원제는 'Reading Wikipedia to Answer Open-Domain Questions' 이다.
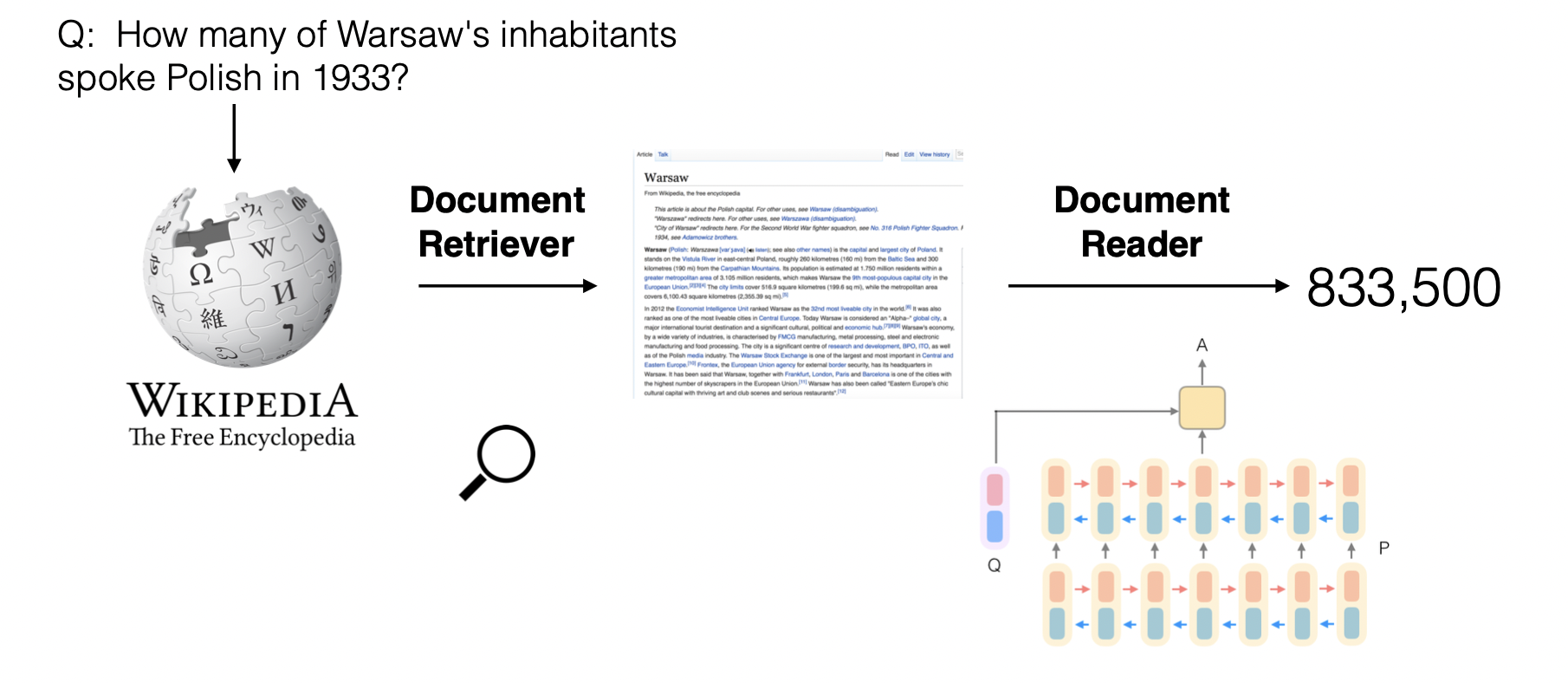
MRS란?
In order to answer any question, one must first retrieve the few relevant articles among more than 5 million items, and then scan them care- fully to identify the answer. We term this setting, machine reading at scale (MRS)
DrQA는 다음과 같은 두 개의 system을 말한다.
1. The Document Retriever module for finding relevant articles
2. A machine comprehension model, Document Reader, for extracting answers
Document Retrieval
먼저, Document Retriever는 TF-IDF를 사용한 모델이며, bigram을 사용하는 것이 가장 좋은 성능을 보였다. Document Retrieval이 끝나면 5개의 relevent paragraph data를 반환한다.
Document Reader
Reader는 3-layer bidirectional LSTM with h=128 모델을 활용했다. At- tentiveReader described in (Hermann et al., 2015; Chen et al., 2016)
Paragraph Encoding, Question Encoding, Prediction의 형태로 이루어지며 Question Encoding에서는 워드 임베딩에 RNN레이어를 추가하여 hidden vector들을 combine 하는 형태이다. combine은 Question token에 가중치를 곱해서 더해주는 과정으로 이루어진다. prediction에서는 start와 end 토큰의 확률을 에 비례하도록 만들어 정답 span을 예측한다. 이 때 start와 end 토큰 사이의 길이는 15가 최대이다.
Paragraph Encoding은 어떤 paragraph p에 대해서 p1~pm개의 토큰으로 이루어져있다고 할 때, RNN(LSTM)모델을 거쳐 encoding을 한다. feature vector로 Word Embedding 뿐만 아니라 Exact match(whether pi can be exactly matched to one question word in q), Token features 정보(POS, NER, TF), Aligned question embedding 을 포함한다.
Conclusion
We studied the task of machine reading at scale, by using Wikipedia as the unique knowledge source for open-domain QA. Our results indicate that MRS is a key challenging task for researchers to focus on. Machine comprehension systems alone cannot solve the overall task. Our method integrates search, distant supervision, and multitask learning to provide an effective complete system. Evaluating the individual components as well as the full system across multiple benchmarks showed the efficacy of our approach.
Future work should aim to improve over our DrQA system. Two obvious angles of attack are: (i) incorporate the fact that Document Reader aggregates over multiple paragraphs and documents directly in the training, as it currently trains on paragraphs independently; and (ii) perform end-to-end training across the Document Retriever and Document Reader pipeline, rather than independent systems.
ORQA(Open Retrieval Question Answering)
2019년 Google research 팀에서 발표한 ODQA 논문으로, retriever와 reader를 동시에 학습하는 최초의 모델이다.
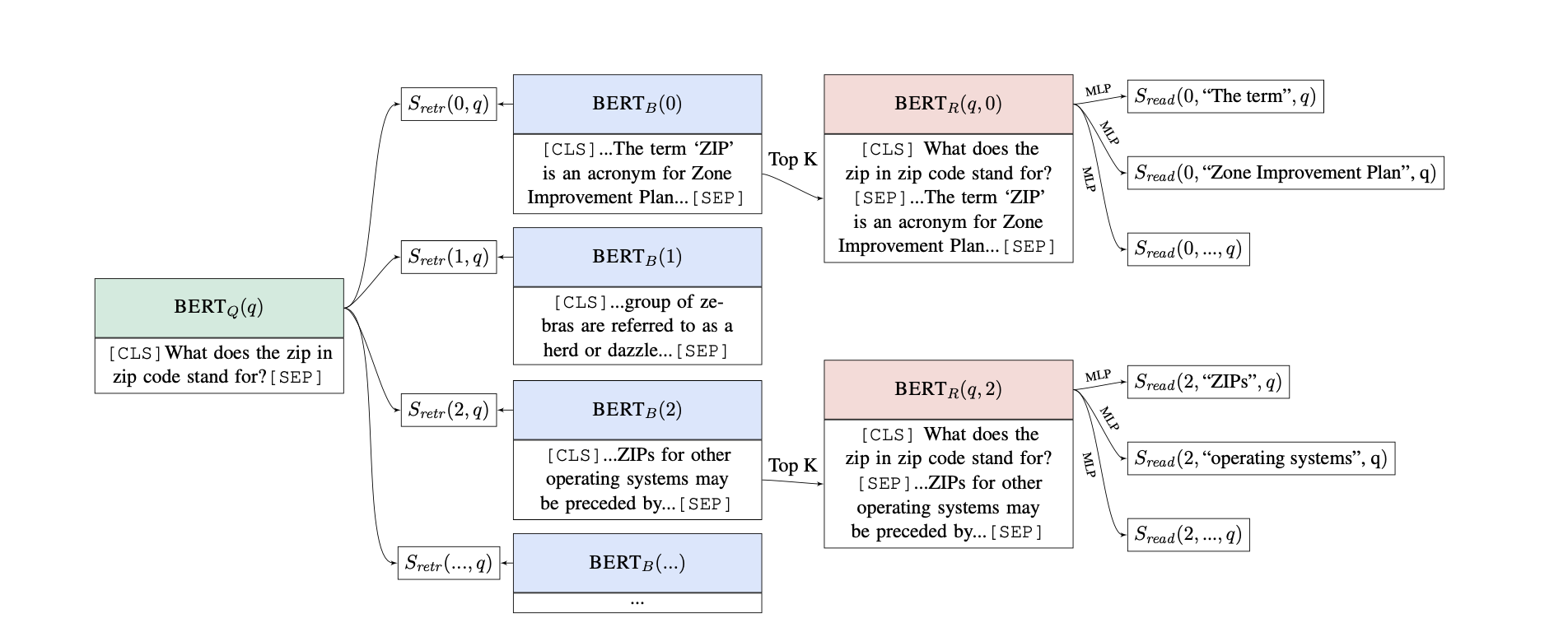
본 논문에서는 Open Retrieval Question Answering(ORQA) System을 제안한다. ORQA는 open corpus에서 evidence를 검색하는 방법을 배우고 question-answer pair로만 학습이 된다. 핵심은 unsupervised Inverse Cloze Task(ICT)를 통해 retriever를 pre-train하면 end-to-end 학습이 가능하다는 것이다. ICT에서 sentence는 pseudo-question으로 처리되고 context는 pseudo-evidence로 처리된다. ICT pre-training은 정답을 marginal log-likelihood로 최적화하여 ORQA를 end-to-end로 fine-tuning할 수 있도록 초기화할 수 있다.
Transfer learning의 최근 발전에 따라 모든 scoring component는 unsupervised language modeling data로 부터 pre-train된 bidirectional transformer인 BERT에서 파생된다. 해당 task에서 relevant abstraction은 다음 function으로 설명할 수 있다.
BERT function은 하나 또는 두 개의 string input 및 선택적으로 을 argument로 사용한다. CLS pooling token 또는 input token representation에 해당하는 vector를 반환한다.
Retriever component: Retriever를 학습할 수 있도록 retrieval score를 question 와 evidence block 의 inner product로 정의한다.
여기서 및 는 BERT output을 128 dimension vector로 projection하는 matrix이다.
Reader component: Reader는 BERT에서 제안된 reading comprehension model의 span-based 변형이다.
Lee et al.,(2016)에서 span은 end point의 concatenation이며, 시작 및 종료 interaction을 가능하게 하는 multi-layer perceptron으로 score가 매겨 진다.
위의 방식은 latent variable 때문에 naive하게 적용하기는 어려운데, unsupervised pre-training을 통해 retriever를 신중하게 초기화하여 이러한 문제를 해결한다.
Inverse Cloze Task
제안된 pre-training procedure의 objective는 retriever가 QA에 대한 evidence retriever와 매우 유사한 unsupervised task를 해결하는 것이다.
직관적으로 useful evidence는 질문의 entity, event, 및 relation에 대해 논의한다. 또한 질문에 없는 추가 정보(답변)가 포함되어 있다. Question-evidence pair의 unsupervised analog는 sentence-context pair이다. context의 Sentence는 의미상으로 관련이 있으며 sentence에서 누락된 정보를 유추하는데 사용될 수 있다.
model learning


일치하는 답변이 발견되지 않으면 example이 폐기된다. 무작위 초기화로 거의 모든 사례가 폐기될것으로 예상하겠지만, ICT pre-train으로 인해 실제 사례의 10% 미만을 폐기한다.
또한, evidence block encoder의 parameter를 제외한 모든 parameter를 fine-tuning한다. Query encoder는 학습 가능하므로 model은 evidence block을 검색하는 방법을 학습할 수 있다. 이 표현력은 blackbox IR system과의 중요한 차이점으로, 더 많은 evidence를 검색해야만 recall을 개선할 수 있다.
DPR
2020년 facebook AI research 팀에서 발표한 Dense Retrieval 논문이다.
위의 링크해놓은 글들에서 자세히 다루고 있는데, 가장 핵심적인 부분은 Dense Retrieval과 Reader를 따로 구분하고 학습시켰다는 것과, Dense Retrieval의 학습 방법으로 사전학습된 BERT모델을 In-batch GOLD방법으로 학습했다는 것이다. 이 때 BM25를 이용해 성능이 가장 좋은 Hard Negative를 추가해주는 것도 좋은 방법이었다고 한다.
RAG
